论文翻译:Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector
原文链接:https://arxiv.org/abs/1908.01998
提出 带有注意力RPN和多关系检测器的小样本目标检测网络 并 开源 FSOD数据集(含1000个类别)
小样本学习的综述https://arxiv.org/pdf/1904.05046.pdf
小样本学习即少样本学习,少样本就是数据集样本数量比通用标准要少很多,甚至每个类别下只有几个的意思。少样本学习由于数据不足往往要借助于更多的先验知识。
小样本不是小目标。【可能只有我会搞混吧】
《Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector》
数据集地址:https://github.com/fanq15/Few-Shot-Object-Detection-Dataset
主要翻译了摘要、引言、方法三个部分
摘要
传统的目标检测方法通常需要大量的训练数据,并且准备这样高质量的训练数据是劳动密集型的(工作)。在本文中,我们提出了少量样本的目标检测网络,目的是检测只有几个训练实例的未见过的类别对象。我们的方法的核心是注意力RPN和多关系模块,充分利用少量训练样本和测试集之间的相似度来检测新对象,同时抑制背景中的错误检测。为了训练我们的网络,我们已经准备了一个新的数据集,它包含1000类具有高质量注释的不同对象。据我们所知,这也是第一个数据集专门设计用于少样本目标检测。一旦我们的网络被训练,我们可以应用对象检测为未见过的类,而无需进一步的训练或微调。我们的方法是通用的,并且具有广泛的应用范围。我们证明了我们的方法在不同的数据集上的定性和定量的有效性。
引言
现有的物体检测方法通常严重依赖大量的注释数据,并且需要很长的训练时间。这激发了少量样本物体检测的最新发展。鉴于现实世界中物体的光照,形状,纹理等变化很大,少量样本学习会遇到挑战。尽管已经取得了重要的研究和进展[1、2、3、4、5、6、7、8],但是所有这些方法都将重点放在图像分类上,而很少涉及到很少检测到物体的问题,这很可能是因为转移从少样本分类到少样本目标检测是一项艰巨的任务。
仅有少数样本的目标检测的中心是如何在杂乱的背景中定位看不见的对象,从长远来看,这是新颖类别中一些带注释的示例中对象定位的一个普遍问题。潜在的边界框很容易错过看不见的物体,否则可能会在后台产生许多错误的检测结果。我们认为,这是由于区域提议网络(RPN)输出的良好边界框得分不当而导致难以检测到新物体。这使得少样本目标检测本质上不同于少样本分类。另一方面,最近用于少样本物体检测的工作[9、10、11、12]都需要微调,因此不能直接应用于新颖类别。
在本文中,我们解决了少样本目标检测的问题:给定一些新颖目标对象的支持图像,我们的目标是检测测试集中属于目标对象类别的所有前景对象,如图1所示。

为此,我们提出两项主要贡献:
首先,我们提出了一种通用的少样本物体检测模型,该模型可用于检测新颖物体而无需重新训练和微调。借助我们精心设计的对比训练策略,RPN上的注意力模块和检测器,我们的方法在多个网络阶段利用权重共享网络中的对象对之间的匹配关系。这使我们的模型可以对不需要精细训练或无需进一步网络适应的新颖类别的对象执行在线检测。实验表明,我们的模型可以在建议质量得到显着提高的早期阶段中从关注模块以及多重关系检测器模块中受益,该模型可以抑制并在令人迷惑的背景中滤除错误检测。我们的模型在少样本设置下就在ImageNet Detection数据集和MS COCO数据集上实现了最新的性能。
第二个贡献是一个大型的带注释的数据集,该数据集包含1000个类别,每个类别仅包含几个示例。总体而言,与现有的大规模数据集(例如,coco[13]。据我们所知,这是具有空前数量的对象类别(1000)的少样本目标检测数据集之一。使用该数据集,即使没有任何微调,我们的模型也可以在不同的数据集上实现更好的性能。
相关工作
通用目标检测
少样本学习
FSOD数据集: A Highly-Diverse Few-Shot Object Detection Dataset
进行少量学习的关键在于,当新颖的类别出现时,相关模型的泛化能力。因此,具有大量对象类别的高多样性数据集对于训练可以检测到看不见的对象的通用模型以及执行令人信服的评估是必要的。但是,现有的数据集[13、52、53、54、55]包含的类别非常有限,并且不是在一次性评估设置中设计的。因此,我们建立了一个新的少样本物体检测数据集。
我们从现有的大规模对象检测数据集构建数据集以进行监督学习,即[56,54]。但是,由于以下原因,这些数据集无法直接使用:
1)不同数据集的标签系统是在某些具有相同语义的对象用不同的词注释的地方不一致;
2)由于标签不正确和缺失,重复的框,对象太大,现有注释的很大一部分是嘈杂的;
3)他们的训练/测试组包含相同的类别,而对于少样本设置,我们希望训练/测试组包含不同的类别,以评估其在看不见的类别上的普遍性
为了开始构建数据集,我们首先从[56,54]中总结标签系统。我们将叶子标签合并到其原始标签树中,方法是将相同语义(例如,冰熊和北极熊)的叶子标签归为一类,并删除不属于任何叶子类别的语义。然后,我们删除标签质量差的图像和带有不合适尺寸的盒子的图像。具体而言,删除的图像的框小于图像尺寸的0.05%,通常框的视觉质量较差,不适合用作支持示例。接下来,我们遵循几次学习设置,将我们的数据分为训练集和测试集,而没有重叠的类别。如果研究人员更喜欢预训练阶段,我们将在MS COCO数据集[13]中按类别构建训练集。然后,我们通过选择现有训练类别中距离最大的类别来划分包含200个类别的测试集,其中距离是连接is-a分类法中两个短语的含义的最短路径[57]。其余类别将合并到总共包含800个类别的训练集中。总而言之,我们构建了一个包含1000个类别的数据集,其中明确地划分了类别用于训练和测试,其中531个类别来自ImageNet数据集[56],而469来自开放图像数据集[54]。
数据集分析。我们的数据集是专为几次学习和评估新颖类别模型的通用性而设计的,该模型包含1000个类别,分别用于训练和测试集的800/200分割,总共约66,000张图像和182,000个边界框。表1和图3显示了详细的统计信息。我们的数据集具有以下属性:


类别的高度多样性
包含了83中父类语义,例如哺乳动物,衣服,武器等,这些语义进一步细分为1000个叶子类别。我们的标签树如图2所示。由于严格的数据集划分,我们的训练/测试集包含了非常不同的语义类别的图像,因此给要评估的模型带来了挑战。
具有挑战性的设置:我们的数据集包含对象大小和纵横比差异很大的对象,由26.5%的图像组成,其中测试集中的对象不少于3个。我们的测试集包含大量未包含在标签系统中的类别的框,因此对于少样本的模型提出了巨大挑战。
尽管我们的数据集具有大量类别,但是训练图像和框的数量远少于其他大规模基准数据集(例如MS COCO数据集),该数据集包含123,287张图像和约886,000个边界框。我们的数据集设计简练,同时对少样本学习有效。
方法
在本节中,我们首先定义了少样本检测的任务,然后详细描述了我们的新网络。
问题定义
给定一个带有目标对象特写的支持图像sc和一个可能包含支持类别c的对象的查询图像qc,任务是在查询图像中查找属于该支持类别的所有目标对象,并用紧密的边界框将他们标记出来。如果支持集包含K个类别,每个类别包含N个示例,则该问题被称为K-way N-shot检测。
深度注意力少样本检测
我们提出了一种新颖的注意力网络,它可以学习支持集与RPN模块和检测器上的查询之间的一般匹配关系。图4显示了我们网络的总体架构。
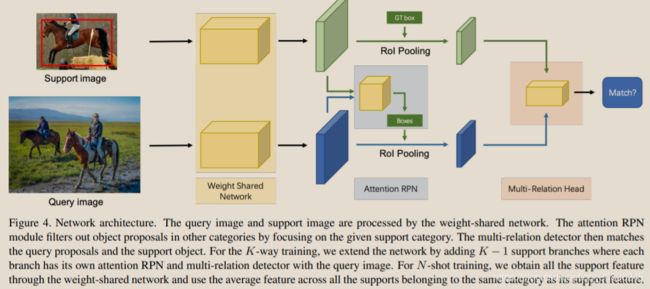
图四:网络结构。查询图像和支持图像由权重共享网络处理。注意力RPN模块通过关注给定的支持类别来过滤掉其他类别的对象建议。然后,多关系检测器将查询建议与支持对象进行匹配。对于K-way训练,我们通过添加K -1个支持分支来扩展网络,其中每个分支都有自己的注意力RPN和带有查询图像的多关系检测器。对于N-shot训练,我们通过重量共享网络获得所有支持特征,并使用属于同一类别的所有支持特征的平均特征。
具体来说,我们构建了一个由多个分支组成的权重共享框架,其中一个分支用于查询集,另一个分支用于支持集(为简单起见,我们在图中仅显示了一个支持分支)。权重共享框架的查询分支是Faster R-CNN网络,其中包含RPN和检测器。我们利用此框架来训练支持和查询功能之间的匹配关系,使网络学习相同类别之间的常识。在该框架的基础上,我们引入了一种新颖的注意力RPN和具有多关系模块的检测器,用于在支持框和查询框之间产生准确的查询解析。
基于注意力的区域提议网络
在少样本检测中,RPN产生可能相关的框,用于之后的检测任务。特别是,RPN不仅应区分对象还是非对象,还应过滤掉不属于支持类别的其他对象。但是,如果没有任何支持图像信息,即使它们不属于支持类别,RPN在具有高客观分数的每个潜在对象中也将毫无目标地运作,从而给检测器的后续分类任务增加了许多不相关的对象。为了解决这个问题,我们提出注意力RPN(图5),它使用支持信息来过滤掉大多数背景框和不匹配类别的背景框。因此,生成了一个较小且更精确的候选提案集,其中包含潜在的目标对象。

图五:注意力RPN。支持特征被平均合并到1×1×C向量。然后计算与查询特征的深度互相关,其输出用作关注特征,并馈入RPN以生成提案。
我们通过关注机制向RPN介绍支持信息,指导RPN生成相关提案,同时禁止其他类别提案。具体来说,我们以深度方式计算支持特征图和查询特征图之间的相似度。然后利用相似度图来构建提案生成。
特别地,我们将支持特征表示为X∈t S×S×C,将查询的特征图表示为Y∈t H×W×C,相似性定义为
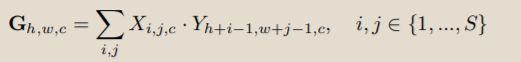 其中G是结果关注特征图
其中G是结果关注特征图
在这里,支持特征X被用作在查询特征图上滑动的内核,然后在它们之间进行深度卷积[58]。
在我们的工作中,我们采用了RPN模型顶层的功能,即ResNet50中的res4-6。我们发现在我们的例子中,内核大小为S = 1表现良好。这个事实与[25]一致,即全局特征可以为对象分类提供一个良好的对象。在我们的案例中,内核是通过对支持特征图进行平均来计算的。注意图通过3×3卷积处理,然后是客观分类层和框回归层。损失为Lrpn的注意力RPN与网络[25]一起训练。
多重关系检测器
在R-CNN框架中,RPN模块后面将是一个检测器,该检测器发挥重要作用,重新计分建议和类别识别。因此,我们希望检测器具有很强的区分不同类别的能力。为此,我们提出了一种新颖的多重关系检测器,可以有效地测量来自查询和支持对象的提议框之间的相似性,见图6。

图6:多关系检测器。不同的关系模块建模查询和支持图像之间的不同关系。全局关系模块使用全局表示来匹配图像;局部关系模块捕获像素到像素的匹配关系;补丁关系模块对一对多像素关系进行建模。
该检测器包括三个注意模块,分别是要学习的全局关系模块在深度嵌入的全局匹配中,局部相关模块学习支持和查询建议之间的像素级和深度互相关,而补丁关系模块则学习深度非线性度量以用于补丁匹配。我们通过实验证明,三个匹配的模块可以相互补充以产生更高的性能。有关三个模块的实施细节,请参阅补充材料。【这里三个模块在原文中是head(负责人)倒是生动形象】
我们需要哪些关系模块?我们遵循RepMet [59]中提出的Kway N-shot评估协议来评估我们的关系模块和其他组件。表2显示了我们在FSOD数据集的简单1-way 1-shot训练策略和5-way 5-shot评估下对我们提出的多关系检测器的模型简化测试【ablation:切除,ablation study 模型简化测试,即去掉一些模块后性能有没有影响,为了研究模型中所提出的一些结构是否有效而设计的实验】。
此后,我们对FSOD数据集上的所有模型简化测试使用相同的评估设置。对于单个模块,本地关系模块在AP50和AP75评估中均表现最佳。出人意料的是,尽管补丁关系模块对图像之间更复杂的关系进行建模,但其性能比其他关系模块差。我们认为,复杂的关系模块使模型难以学习。当组合任何两种类型的关系模块时,我们获得的性能要优于单个关系模块。通过组合所有的关系模块,我们获得了完整的多重关系检测器,并获得了最佳性能,表明三个提出的关系模块相互补充,可以更好地区分目标与不匹配的对象。因此,以下所有实验均采用完整的多关系检测器。
双向对比训练策略
最简单【naive】的训练策略是通过构造训练对(qc,sc)来匹配相同类别的对象,其中查询图像qc和支持图像sc都在同一第c个类别对象中。但是,好的模型不仅应匹配相同的类别对象,还应区分不同的类别。因此,我们提出了一种新颖的双向对比训练策略。
根据图7中不同的匹配结果,我们提出了2次对比训练,在区分不同类别的同时匹配相同类别。

图7:2次对比训练三联体和不同的匹配结果。在查询图像中,只有正支持与目标基本事实具有相同的类别。匹配对包括正面支持和前景建议,非匹配对具有三类:(1)正面支持和背景建议;(2)负面支持和前景建议;(3)负面支持和负面建议。
我们随机选择一个查询图像qc,一个包含相同第c个类别对象的支持图像sc和另一个包含不同第n个类别对象的支持图像sn来构建训练三元组(qc,sc,sn),其中c不等于n。
在训练三元组中,仅将查询图像中的第c个类别对象标记为前景,而将所有其他对象视为背景。
在训练期间,模型学习将查询图像中的注意力RPN生成的每个建议与支持图像中的对象进行匹配。因此,该模型不仅学习匹配(qc,sn)之间的相同类别对象,而且还可以区分(qc,sn)之间的不同类别的对象。但是,大量的背景建议通常会主导培训,尤其是带有负面支持图片时。因此,我们在查询提议和支持之间平衡了三个不同匹配对的比率。对于前景提案和正支持对(pf,sp),背景提案和正支持对(pb,sp),提案(前景或背景)和否定支持对(p,sn)。我们选择所有N(pf,sp)对,并根据它们的匹配分数分别选择前2N(pb,sp)对和前N(p,sn)对。我们计算所选对的匹配损耗。在训练过程中,我们在每个抽样建议上使用多任务损失,如L = Lmatching + Lbox,边界框损失Lbox如[24]中所定义,匹配损失为二进制交叉熵。
哪种训练策略更好?请参阅表3。
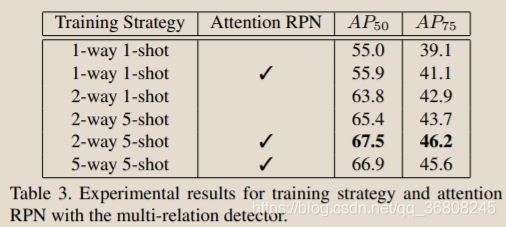
我们使用2-way 1-shot对比训练策略训练模型,与1-way 1-shot单纯训练策略相比,AP50改善了7.9%,这表明在训练中学习如何区分不同类别方面的重要性。通过5-shot训练,我们实现了进一步的改进,这在[1]中也得到了验证,少样本训练对少样本测试很有帮助。将我们的双向训练策略扩展到多向训练策略很简单。但是,从表3中可以看出,五次训练策略的效果并不比二次训练策略更好。我们认为,只有一个否定支持类别足以训练用于区分不同类别的模型。因此,我们的完整模型采用了2-way 5-shot对比训练策略。
哪个RPN更好?
我们根据不同的评估指标评估注意力RPN。为了评估提案质量,我们首先评估常规RPN和建议的RPN超过0.5 IoU阈值的前100个提案的召回率。我们关注的RPN具有比常规RPN更好的召回性能(0.9130对0.8804)。然后,我们针对这两个RPN评估整个ground truth框的平均最佳重叠率(ABO)。注意RPN的ABO为0.7282,而常规RPN的相同度量为0.7127。这些结果表明,关注RPN可以生成更多高质量的建议。
表3进一步比较了在不同训练策略下具有注意力RPN的模型和具有常规RPN的模型。在AP50和AP75评估中,注意力RPN的模型始终表现出比常规RPN更好的性能。在AP50 / AP75评估中,注意力RPN在1-way 1-shot训练策略中产生0.9%/ 2.0%的收益,在2-way 5-shot训练策略中产生2.0%/ 2.1%的收益。这些结果证实,我们注意力的RPN会产生更好的建议并有益于最终的检测预测。因此,在我们的完整模型中采用了注意力RPN。