pix2pix 学习笔记
论文:
Image-to-Image Translation with Conditional Adversarial Networks
https://arxiv.org/pdf/1611.07004v1.pdf
代码:
官方project:https://phillipi.github.io/pix2pix/
官方torch代码:https://github.com/phillipi/pix2pix
官方pytorch代码(CycleGAN、pix2pix):https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
第三方的tensorflow版本:https://github.com/yenchenlin/pix2pix-tensorflow
如下图所示,左侧为正样本,右侧为负样本。其中真实图像为y,真是图像对应的航空图像为x,这两张图像通过判别器,得到正样本。右图中将航空图像x通过生成器G,得到重建的图像G(x,z),而后将重构图像及真实航空图像输入判别器D,作为负样本。

1. 介绍:
图像处理的很多问题都是将一张输入的图片转变为一张对应的输出图片,比如灰度图、梯度图、彩色图之间的转换等。通常每一种问题都使用特定的算法(如:使用CNN来解决图像转换问题时,要根据每个问题设定一个特定的loss function 来让CNN去优化,而一般的方法都是训练CNN去缩小输入跟输出的欧氏距离,但这样通常会得到比较模糊的输出)。这些方法的本质其实都是从像素到像素的映射。于是论文在GAN的基础上提出一个通用的方法:pix2pix 来解决这一类问题。通过pix2pix来完成成对的图像转换(Labels to Street Scene, Aerial to Map,Day to Night等),可以得到比较清晰的结果。
先看一张效果图:

2. 方法

training procedure
训练大致过程如上图所示。图片 x 作为此cGAN的条件,需要输入到G和D中。G的输入是{x,z}(其中,x 是需要转换的图片,z 是随机噪声),输出是生成的图片G(x,z)。D则需要分辨出{x,G(x,z)}和{x,y}。
2.1 目标函数
pix2pix使用的是Conditional GAN(cGAN)。传统的GAN通过随机向量z学习到图像y:G:z→yG:z→y;cGAN则是通过输入图像x及随机向量z学到图像y:G:{x,z}→yG:{x,z}→y。一般的cGAN的目标函数如下,生成器 G 不断的尝试minimize下面的目标函数,而D则通过不断的迭代去maximize这个目标函数。

cGAN的目标函数
为了测试输入的条件x对于D的影响,论文也训练一个普通的GAN,判别器D只用于判别生成的图像是否真实。
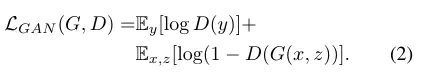
GAN
前人的一些工作中发现,将GAN的目标函数和传统的loss结合,可以带来更好的效果。由于以前的研究中发现,对于cGAN,增加一个额外的损失,如L2距离(真实图像和生成图像),效果更好。此时判别器的损失不变,生成器的损失变了。该论文中使用L1距离,原因是相比于L2距离,L1距离产生的模糊更小。所以论文增加了一个L1 loss交给生成器G去最小化。

L1 loss
所以最终的目标函数是:
![]()
final objective
文中对于不同的loss的效果做了一个对比,可以看到L1 + cGAN的效果相对于只用L1或者cGAN都是比较好的。

different loss
2.2 网络结构
论文对DCGAN的生成器和判别器的结构做了一些改进。
2.2.1 生成器结构
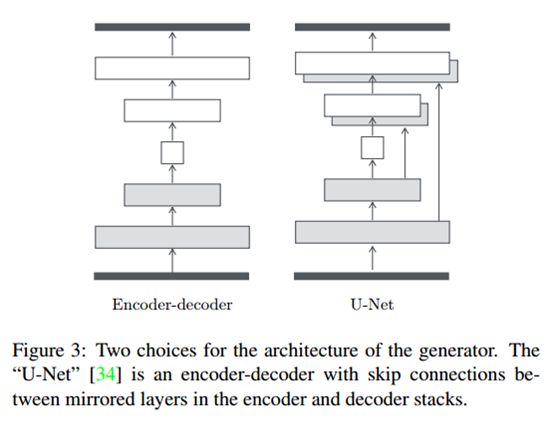
pix2pix未使用传统的encoder-decoder的模式(下图左侧),而是使用了U-Net(下图右侧)网络。U-Net论文为:U-net: Convolutional networks for biomedical image segmentation。U-net在decoder部分,每个conv层之前将输入和decoder对应的镜像层进行了拼接,因而输入的通道数增加了1倍,但是不严谨的说,输入的通道数不会影响卷积的输出维度,因而网络不会出问题。
网络中的判别器结构比较容易理解,生成器按照上面U-Net理解之后,也比较容易理解(开始没有理解U-Net,导致对生成器中encoder的理解有困难)。具体网络结构如下图所示(对应于第三方的tensorflow代码)。当输入为256*256的图像时,第一行为图像宽高(未考虑batchsize及channel),第二行中e1…e8和第三行d1…d8为generator函数中对应的变量。第三行d1t…d7t为generator函数中encoder的临时变量。其和e8…e2在channel维度进行concat后得到最终的d1…d7。最终d8经过tanh后,得到输入范围为[-1,1]之内的生成图像。


U-Net
U-Net是德国Freiburg大学模式识别和图像处理组提出的一种全卷积结构。和常见的先降采样到低维度,再升采样到原始分辨率的编解码(Encoder-Decoder)结构的网络相比,U-Net的区别是加入skip-connection,对应的feature maps和decode之后的同样大小的feature maps按通道拼(concatenate)一起,用来保留不同分辨率下像素级的细节信息。U-Net对提升细节的效果非常明显,下面是文中给出的一个效果对比,可以看到不同尺度的信息都得到了很好的保留。

不同结构的G与不同的目标函数组合的效果对比
2.2.2 判别器结构
利用马尔科夫性的判别器(PatchGAN)
pix2pix采用的一个想法是,用重建来解决低频成分,用GAN来解决高频成分。一方面,使用传统的L1 loss来让生成的图片跟训练的图片尽量相似,用GAN来构建高频部分的细节。
![]()
final objective
另一方面,使用PatchGAN来判别是否是生成的图片。PatchGAN的思想是,既然GAN只用于构建高频信息,那么就不需要将整张图片输入到判别器中,让判别器对图像的每个大小为N x N的patch做真假判别就可以了。因为不同的patch之间可以认为是相互独立的。pix2pix对一张图片切割成不同的N x N大小的patch,判别器对每一个patch做真假判别,将一张图片所有patch的结果取平均作为最终的判别器输出。
具体实现的时候,作者使用的是一个NxN输入的全卷积小网络,最后一层每个像素过sigmoid输出为真的概率,然后用BCEloss计算得到最终loss。这样做的好处是因为输入的维度大大降低,所以参数量少,运算速度也比直接输入一张快,并且可以计算任意大小的图。论文对比了不同大小patch的结果,对于256x256的输入,patch大小在70x70的时候,从视觉上看结果就和直接把整张图片作为判别器输入没有多大区别了:

patchGAN
3. 效果




4. 总结
优点:pix2pix巧妙的利用了GAN的框架来为“Image-to-Image translation”的一类问题提供了通用框架。利用U-Net提升细节,并且利用PatchGAN来处理图像的高频部分。
缺点:训练需要大量的成对图片,比如白天转黑夜,则需要大量的同一个地方的白天和黑夜的照片。
作者:AlanPaul
链接:https://www.jianshu.com/p/8c7a7cb7198c
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。