基于自然语言处理的垃圾信息过滤方法
基于自然语言处理的垃圾信息过滤方法
Spam Filtering Method Based on Natural Language Processing
目 录
摘 要
Abstract
1 垃圾信息过滤技术
1.1 基于黑白名单的过滤技术
1.2 基于行为模式的过滤技术
1.3 基于社交平台举报机制的过滤技术
1.4 基于关键字的过滤技术
1.5 基于规则的过滤技术
1.5.1 粗糙集
1.5.2 决策树
1.5.3 Ripper
1.5.4 Boosting
1.6 基于统计的过滤技术
1.6.1 朴素贝叶斯
1.6.2 逻辑回归
1.6.4 KNN
1.6.5 神经网络
1.6.6 随机森林
1.6.7 Winnow
1.7 本文小结
参考文献
摘 要
随着互联网的发展,网络信息量日益剧增,而垃圾信息也随之泛滥,在消耗大量网络资源的同时,阻碍了用户之间的交流,甚至影响社会安定。因此,提取有用信息,过滤垃圾信息,成为目前社会迫切的需求。垃圾信息过滤作为提高网络信息可用性的主要途径,是自然语言处理领域一项主要研究内容。
根据信息产生平台的不同,具体的垃圾信息过滤技术会有区别。但目前主流的垃圾信息过滤技术主要分为基于黑白名单的过滤技术、基于关键字的过滤技术、基于行为模式的举报技术、基于规则的过滤技术和基于统计机器学习的过滤技术。本文基于自然语言处理的角度,简要介绍了这些垃圾信息过滤技术。
关键词:垃圾信息过滤;自然语言处理;
Abstract
With the development of the Internet, the amount of network information is increasing rapidly, and spam is also flooding. While consuming a large amount of network resources, it hinders communication between users and even affects social stability. Therefore, extracting useful information and filtering spam has become an urgent need of the society. As the main way to improve the usability of network information, spam filtering is a major research content in the field of natural language processing.
Depending on the information generation platform, specific spam filtering techniques will differ. However, the current mainstream spam filtering technologies are mainly classified into black-and-white list-based filtering technology, keyword-based filtering technology, behavior-based reporting technology, rule-based filtering technology, and statistical machine learning-based filtering technology. This paper briefly introduces these spam filtering technologies based on the perspective of natural language processing.
Key Words:Spam Filtering; Natural Language Processing;
1 垃圾信息过滤技术
1982年,Denning[1]首次提出垃圾信息过滤的概念。垃圾信息过滤是指采用一定技术手段识别出垃圾信息,并将其阻挡在外。迄今为止,垃圾信息载体从文本、图片到如今的视频。而在技术上,也衍生出以下几种方法:基于黑白名单过滤技术、基于行为模式的过滤技术、基于社交平台举报机制的过滤技术、基于关键字的过滤技术、基于规则的过滤技术和基于统计机器学习的过滤技术,其中,基于规则和统计的过滤技术又被统称为基于内容的过滤技术。
1.1 基于黑白名单的过滤技术
黑白名单过滤技术,是通过预先建立黑白名单来过滤信息,多用于垃圾邮件过滤。指当信息发送到接收方时,接收方根据系统设定的黑名单和白名单对信息进行接收或者阻挡。该名单可预先根据一定的信息建立,并且随时更新名单。
其中,黑名单过滤技术是指通过建立知识库,其中保存着从大量垃圾信息中得到的发送者的用户账号等信息。将待过滤信息与之对比,若该信息包含知识库中的对应字段,则认为是垃圾信息并将其过滤。白名单过滤技术则相反,通过建立白名单知识库,对接收到的信息判断其发送者用户信息是否在白名单中,若在则认为是正常信息直接发送,若不在则认为是垃圾信息过滤掉。
随着用户的增长,黑白名单愈发庞大,难以管理。且垃圾信息发送方会通过不断改变自己的IP地址来绕过黑名单,因此传统的黑白名单技术会因地址过时而效率降低,误判率提高。
1.2 基于行为模式的过滤技术
行为模式是从大量实际行为中归纳出来的行为的理论抽象、基本框架或标准[2]。而基于行为模式的过滤技术即通过对垃圾信息样本进行分析,建立其行为特征模型,将待处理信息用该模型进行分析,判断,过滤。在垃圾邮件过滤中,该行为模式可能是通过邮件的群发性或是否含有大量链接来判断是否为垃圾邮件。而在搜索引擎中,可能是通过分析WEB的内容和结构:欺骗性、隐藏性、标题与网页内容不符合、转向垃圾链接等来判断。
1.3 基于社交平台举报机制的过滤技术
2009年10月14日 Twitter推出了举报机制,并且于2018年,更新部分举报流程,用户可以点击举报按钮下面的“可疑或垃圾内容”选项,并详细说明自己这么认为的理由,包括可以表示“发布此推文的账号是虚假的”。而新浪微博在2012年也正式成立社区委员会来审核举报信息。一旦核查属实,平台将会移除相应博文,封停相关用户账号。这种用户举报的方式,能够更为精确地打击垃圾信息发送方,但是需要耗费大量人力,因此效率不是很高。
1.4 基于关键字的过滤技术
基于关键字匹配的过滤方法是创建一个关键字列表,然后按照该列表确定信息是否为垃圾信息。列表是从大量垃圾邮件中总结出来的经常出现的单词,例如“中奖”“特惠”等。该方法需要创建一个庞大的过滤关键字列表并保持更新。关键字匹配过滤方法易于理解且修改便捷。但是字符匹配会消耗大量系统资源,而且乱序或转换字体的垃圾信息识别率低,无法保证准确性。因此,该方法不适用于规律性低的领域。
1.5 基于规则的过滤技术
基于规则的垃圾过滤方法是设置一些过滤规则,这些规则是通过训练,归纳总结得到的。并将这些规则创立为规则库,将信息与之匹配来判断是否为垃圾信息。这类方法效率较高,规则库可以共享,推广性很强。缺点在于规则库庞大需要维护,规则更新时效差,在无规则的平台适用度低。基于规则的过滤方法主要有粗糙集、Ripper、决策树和Boosting等。
1.5.1 粗糙集
Rough Sets理论是波兰科学家Z.Pawlak于1982年提出的一种数据推理方法[3]。它研究不完整、不确定知识来进行数据的表达、学习、归纳,具有很强的定性分析能力。它通过集合等价关系来确定属于给定类的最大对象集合和最小对象集合来指导分类决策,属性约简和属性值约简来是粗糙集简化分类规则的方式。它以不完全的信息来处理不分明的现象,在垃圾信息过滤应用方面取得了很好的效果。
1.5.2 决策树
决策树是一种自顶向下自动对数据分类的树形结构。它由节点和有向边组成,通过一系列测试条件来逐步解决分类问题。初始状态为根节点,中间状态为内部节点,最终分类为叶节点。决策树通过对内部节点的属性值进行比较和判断,递归向下,在叶节点得到结论。著名的决策树算法有ID3、C4.5、CART等。Carreras使用决策树来过滤垃圾邮件,得到的准确率和正确率约为88%[4]。它的性能与贝叶斯相当,单准确率低于贝叶斯,且常被作为Boosting方法的弱学习器。
1.5.3 Ripper
Ripper是William W.Cohen提出的一种基于规则的方法[5]。它用具有约束条件的规则及来进行判断。每条RIPPER规则由一些规则前件(如属性值条件)和结果,且包括更好的剪枝和停止准则(最小描述长度:MDL)以及对规则集合的后处理。组成RIPPER算法由于不需要事先建立完整决策树,因此效率比C4.5等要高,缺点是正确率不是很高。
1.5.4 Boosting
Boosting是一种用来提高弱分类算法准确度的算法。它通过已有分类器(弱规则)加权求和,得到最终的分类器(强规则)。它是错误驱动的一种方法:初始时,样本权重相等,迭代后,将失败样本权重增加,从而加强弱学习机对较难的训练样本的学习。
Carreras[4]将AdaBoost引入垃圾邮件过滤,证明了基于Boosting的过滤技术具有很好的性能。缺点就是但是训练速度较慢
1.6 基于统计的过滤技术
随着垃圾信息制造者反识别手段的进化,传统的过滤技术不再适用。而基于统计机器学习的过滤技术由于准确率较高、速度较快、人工成本低,成为了目前应用最广泛的技术。其中,常用算法有朴素贝叶斯、逻辑回归、支持向量机、KNN、神经网络、随机森林等。
1.6.1 朴素贝叶斯
朴素贝叶斯分类算法通过计算概率进行过滤,是垃圾信息检测领域常用的算法。它在过滤垃圾信息时,将获取到的信息划分为垃圾信息和正常信息,分别建立两种信息类型的贝叶斯概率模型,再通过这个模型再去判断要测试的信息是不是垃圾信息。
简单贝叶斯(Naive Bayes)分类算法原理大致如下[6]:
假设文本内容中包含的词汇为Wi,垃圾信息S,正常信息H。 现有一个文本,内容包含的词汇为Wi,判断该文本是否是垃圾信息,即计算P(S|Wi)这个条件概率。根据贝叶斯定理得:
 (1.1)
(1.1)
其中:
Pr(S|Wi):出现词汇Wi的文本是垃圾信息的条件概率(即后验概率);
Pr(S):训练阶段文本数据集中是垃圾信息的概率,或实际调查的是垃圾信息的概率(即先验概率);
Pr(Wi|S):是垃圾信息中词汇Wi出现的概率;
Pr(H):训练阶段文本数据集中正常信息的概率,或实际调查的正常信息的概率;
Pr(Wi|H):正常文本中词汇Wi出现的概率;
对于文本中出现的所有词汇,考虑每个词汇出现事件的独立性,计算Pr(S|Wi)的联合概率Pr(S|W),W={W1,W2,…Wn}:
其中:  (1.2)
(1.2)
P 即Pr(S|W),出现词汇W={W1,W2……Wn}的文本是垃圾信息的条件概率;
Pi 即Pr(S|Wi),出现词汇Wi的文本是垃圾信息的条件概率;
该方法计算简单,速度快,且应用范围广。但是对于分布独立的假设前提,现实情况往往不能满足。
1.6.2 逻辑回归
逻辑回归是一个二分类问题。是一种判别学习模型,其假设条件比生成模型(以贝叶斯为代表)弱,且判别学习算法的目标往往与实际应用的评价标准密切相关。因此,它具有更好的应用优势。
它在判别信息是否为垃圾信息的因素是该信息中的特征。如下的公式为根据信息的特征计算该文本是垃圾信息的概率[7]。
 (1.3)
(1.3)

支持向量机(Support Vector Machine,简称SVM),是20世纪90年代提出的一种二分类学习方法。它通过构造最优线性分类面来指导信息分类:引入高维特征空间,利用核函数,将输入空间的非线性决策便捷转化为高维特征空间的线性决策边界。
在文本分类中,SVM是较好的方法之一。Druckerts[6]将线性SVM用于垃圾信息过滤,得到的结果再次印证了这一点。Drucker还指出,采用二值表示的SVM的性能稍高于采用多值表示的SVM。Kolcz[7]采用了多种SVM方法的变形进行垃圾信息过滤[8]。SVM在解决非线性问题上有一定优势,且适用于小样本和高维模式识别。但是它对于非线性的问题没有普遍使用的解决方法,并且计算量大,参数选择经验性强,一般需要其他方法辅助。
1.6.4 KNN
K近邻(k-Nearest Neighbor,KNN)是常用的模式识别统计方法。KNN无需训练过程,分类时直接将待分类文本与训练集合中的每个文本进行比较,然后根据最相似的k篇文本所属类别得到新文本的类别。而衡量文本之间距离的方式一般采用欧氏距离、余弦相似度或皮尔逊相关系数。它对于未知和非正态分布能够取得较好的分类准确率。并且根据Androutsopoulos的实验,得知其性能与Naive Byes相近。但由于其分类速度的局限性,不适用于对垃圾信息过滤速度要求较高的场景。
1.6.5 神经网络
神经网络是基于生物学建造的模型,它由同步并行处理的神经元和其间的联系构成。基于BP的人工神经网络广泛应用于信息过滤。在信息过滤时,首先要将训练集内容进行预先分类,特征提取和特征优化,然后利用提取出的特征矩阵训练神经网络,并通过输出误差修正系数和偏置值,直到满足分类要求,得到最终的模型。然后向带过滤的信息,得到其分类结果。
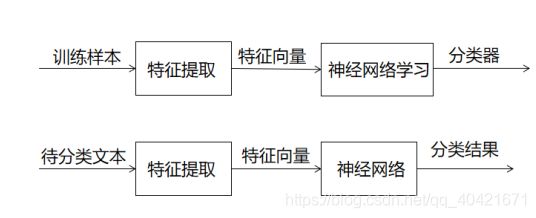
图1-1 神经网络过滤信息系统模型
它有自动学习的能力,在鲁棒性容错性,自适应性方面表现优良。并且并行处理的结构,使其储存能力高,运行速度快。但是其消耗时间长不适用于在线反馈的情景。
1.6.6 随机森林
随机森林是组合分类器。它以决策树分类器为基础,通过汇总所有分类器的投票结果,选出投票最多的分类。随机森林可以解决失衡数据集的平衡误差,并且对于系数样本,随机森林能够避免过拟合问题。
在处理上述问题时,随机森林常常采用基于代价敏感学习的方法和基于样本采样的方法。并且结合准确率、召回率、F值等评价指标,证明了这两种方法能提高预测精度。
1.6.7 Winnow
Winnow分类算法是一种典型的线性分类器。在信息过滤中,它采用向量空间模型表示文本,将文本中有代表意义的词作为特征项。对每个类别,通过训练得到其权重向量。然后设定某个阈值,若待分类的文本向量代入该类权重大于阈值,则将信息归为该类。并且在训练过程,权值调整是错误驱动的,并且按照错误类型:分类器预测训练文本属于某类,但实际上不属于;预测不属于某类,实际上属于分别降低和提高该分类器权重。
该方法在目前已经成功应用于垃圾邮件,垃圾短信和垃圾评论过滤系统,有很好的性能。
1.7 本文小结
本文简要介绍了目前应用与垃圾信息过滤方面的一些技术。大致分为:基于黑白名单的过滤技术、基于关键字的过滤技术、基于规则的过滤技术和基于机器学习统计的过滤技术等。其中,由于深度学习和机器学习的发展,基于机器学习统计的过滤技术在近年来受到广泛欢迎,并且体现出其他技术难以企及的性能。在了解这些技术的时候,可以得到的是,这些技术并不是一成不变的,也不是独立存在的,它们之间的相互组合往往能够得到更好的结果。
参考文献
- Denning P J. ACM president's letter: electronic junk[J]. Communications of the Acm, 1982, 25(3):163-165.
- Reed J M . Recognition behavior based problems in species conservation[J]. Annales Zoologici Fennici, 2004, 41(6):859-877.
- Z.Pawlak. Rough sets. International Journal of Computer and Information Sciences, 1982, 11(8): 41-356.
- Carreras X , Marquez L . Boosting Trees for Anti-Spam Email Filtering[J]. 2001.
- Cohen W W. Fast Effective Rule Induction[C]// Twelfth International Conference on International Conference on Machine Learning. 1995.
- NaiveBayesSpamFilter V1.0.[EB.OL]. 2016. https://blog.csdn.net/mark_lq/article/details/51171765
- 郑晓霞, 刘超, 邹钰. 基于逻辑回归模型的中文垃圾短信过滤[J]. 黑龙江工程学院学报(自然科学版), 2010(04):40-43.
- Drucker H, Wu D, Vapnik V N. Support vector machines for spam categorization[J]. IEEE Transactions on Neural networks, 1999, 10(5): 1048-1054.
- Kolcz A, Alspector J. SVMMbased Filtering of EMmail Spam with ContentMspecific Misclassification Costs[C]//Proc. of TextDM’01 Workshop on Text Mining. 2001.
- Androutsopoulos I, Paliouras G, Karkaletsis V, et al. Learning to Filter Spam E-Mail: A Comparison of a Naive Bayesian and a Memory-Based Approach[J]. Computer Science, 2000, 97(2):1--13.