浅谈Python爬虫(五)【网易云热评爬取实例】
浅谈Python爬虫(五)
- 目的:爬取网易云歌单所有歌曲的信息及热评
- Python环境:3.7
- 编译器:PyCharm2019.1.3专业版
- 存储格式:JSON
1、分析网页
进入网易云音乐首页,点击排行版,任选一个歌单(这里以云音乐飙升榜为例),按下F12,点击NetWork,按F5刷新。点击Doc,发现有一个名为toplist的数据,猜测是有用的数据(蹩脚英语翻译)。点开验证(搜索歌名,看里面有没有需要的数据)。如图。
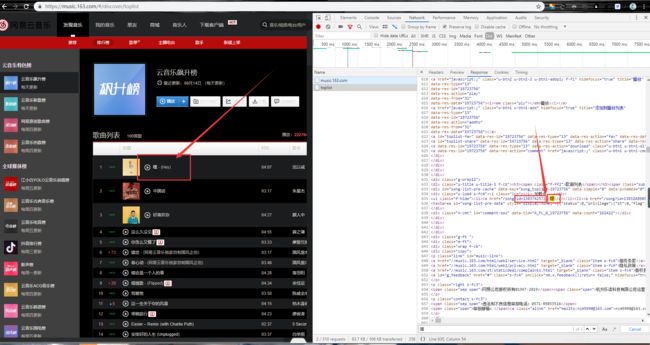
发现包含着音乐名字和音乐id。而进入下层页面需要的正是音乐id。如第一首“嘿”的链接是https://music.163.com/#/song?id=1383742572。
进入歌曲详情页之后,按照同样的步骤进行网页分析。发现Doc里面有一个以音乐id命名的数据,点进去发现只有歌曲基本的信息,如歌曲名字、歌手、所属专辑,但是这也是我们需要的。然而没有找到评论的信息,我们选择去XHR找。
在XHR有一个名为“R_SO_4_1383742572?csrf_token=”的数据,里面包含着评论信息。这是一个POST请求,且参数是采用AES加密算法加密的,笔者没有能力破解,但是笔者偶尔在一篇文章里发现一个链接,可以获取完整的评论信息,所以笔者选择使用这个链接进行爬取。
2、代码编写
首先,第一步需要获取网页源码,这里选择将其写成一个函数,方便后面继续调用。代码如下。
def get_html(url):
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
html = etree.HTML(response.text)
return html
然后我们写获取音乐id的函数。代码如下。
def get_song_id(html):
# 分析网页找到的音乐id所处的位置
id = html.xpath('//ul[@class="f-hide"]/li/a/@href')
for i in range(len(id)):
# 用正则表达式将数字筛选出来
id[i] = re.findall(r'\d+', id[i])
return id
由歌曲id可以组成两个链接,一个是歌曲的链接https://music.163.com/song?id=(歌曲id),一个是评论的链接http://music.163.com/api/v1/resource/comments/R_SO_4_(歌曲id)?limit=20&offset=0。我们访问评论链接,发现是一个json数据,所以还需要一个解析json数据的函数。代码如下。
def get_json(url):
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
return response.json()
由音乐id,可以获取音乐的基本信息。代码如下。
def get_song_info(html):
song_name = str(html.xpath('//em[@class="f-ff2"]/text()')).replace('[\'', '').replace('\']', '')
songer = html.xpath('//p[@class="des s-fc4"]//a[@class="s-fc7"]//text()')[0]
special = html.xpath('//p[@class="des s-fc4"]//a[@class="s-fc7"]//text()')[1]
data_dict = {'歌名': song_name,
'歌手': songer,
'专辑': special}
return data_dict
由评论信息的json数据,可以获取对应的热评信息。由于由的热评较多,所以我们选择前5个热评,不足5个的则全部获取。代码如下。
def get_comment(json):
data_dict = {}
if len(json['hotComments']) >= 5:
# 当热评数量大于5个时
for i in range(5):
data_dict['用户名' + str(i+1)] = json['hotComments'][i]['user']['nickname']
data_dict['评论' + str(i+1)] = str(json['hotComments'][i]['content']).replace('\n', '')
data_dict['获赞数量' + str(i+1)] = json['hotComments'][i]['likedCount']
data_dict['发表时间' + str(i+1)] = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(int(json['hotComments'][i]['time'])/1000))
else:
# 当热评数量不大于5个时
for i in range(len(json['hotComments'])):
data_dict['用户名' + str(i+1)] = json['hotComments'][i]['user']['nickname']
data_dict['评论' + str(i+1)] = str(json['hotComments'][i]['content']).replace('\n', '')
data_dict['获赞数量' + str(i+1)] = json['hotComments'][i]['likedCount']
data_dict['发表时间' + str(i+1)] = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(int(json['hotComments'][i]['time'])/1000))
return data_dict
当把音乐信息及热评信息都获取过来之后,我们选择将其合并,并转换成下面这种格式的JSON数据,然后保存到本地。
{"歌名": ,
"歌手": ,
"专辑": ,
"热评": {
"用户名1": ,
"评论1": ,
"获赞数量1": ,
"发表时间1": ,
}
}
代码如下。
# data包含着歌曲基本信息,comment包含着评论信息
data['热评'] = comment
data_json = json.dumps(data, ensure_ascii=False)
with open('F://SpiderData//网易云.json', encoding='utf8', mode='a') as f:
f.write(data_json + ',')
print(i)
完整代码如下。
import requests
from lxml import etree
import re
import json
import time
def get_html(url):
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
html = etree.HTML(response.text)
return html
def get_json(url):
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
return response.json()
def get_song_id(html):
# 分析网页找到的音乐id所处的位置
id = html.xpath('//ul[@class="f-hide"]/li/a/@href')
for i in range(len(id)):
# 用正则表达式将数字筛选出来
id[i] = re.findall(r'\d+', id[i])
return id
def get_song_info(html):
song_name = str(html.xpath('//em[@class="f-ff2"]/text()')).replace('[\'', '').replace('\']', '')
songer = html.xpath('//p[@class="des s-fc4"]//a[@class="s-fc7"]//text()')[0]
special = html.xpath('//p[@class="des s-fc4"]//a[@class="s-fc7"]//text()')[1]
data_dict = {'歌名': song_name,
'歌手': songer,
'专辑': special}
return data_dict
def get_comment(json):
data_dict = {}
if len(json['hotComments']) >= 5:
for i in range(5):
data_dict['用户名' + str(i+1)] = json['hotComments'][i]['user']['nickname']
data_dict['评论' + str(i+1)] = str(json['hotComments'][i]['content']).replace('\n', '')
data_dict['获赞数量' + str(i+1)] = json['hotComments'][i]['likedCount']
data_dict['发表时间' + str(i+1)] = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(int(json['hotComments'][i]['time'])/1000))
else:
for i in range(len(json['hotComments'])):
data_dict['用户名' + str(i+1)] = json['hotComments'][i]['user']['nickname']
data_dict['评论' + str(i+1)] = str(json['hotComments'][i]['content']).replace('\n', '')
data_dict['获赞数量' + str(i+1)] = json['hotComments'][i]['likedCount']
data_dict['发表时间' + str(i+1)] = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(int(json['hotComments'][i]['time'])/1000))
return data_dict
if __name__ == '__main__':
url = 'https://music.163.com/discover/toplist'
song_id = get_song_id(get_html(url))
for i in range(len(song_id)):
song_url = 'https://music.163.com/song?id={}'.format(song_id[i][0])
comment_url = 'http://music.163.com/api/v1/resource/comments/R_SO_4_{}?limit=20&offset=0'.format(song_id[i][0])
data = get_song_info(get_html(song_url))
comment = get_comment(get_json(comment_url))
data['热评'] = comment
data_json = json.dumps(data, ensure_ascii=False)
with open('F://SpiderData//网易云.json', encoding='utf8', mode='a') as f:
f.write(data_json + ',')
print(i)
爬取的数据截图如下。

3、结语
如果你按照笔者的步骤来,相信数据是可以顺利的保存到本地的,如果有任何问题,欢迎在下面评论或者私信笔者。谢谢各位的观看。