R语言︱数据集分组、筛选(plit – apply – combine模式、dplyr、data.table)
R语言︱数据集分组
大型数据集通常是高度结构化的,结构使得我们可以按不同的方式分组,有时候我们需要关注单个组的数据片断,有时需要聚合不同组内的信息,并相互比较。
一、日期分组
1、关于时间的包都有很多很好的日期分组应用。
2、cut()函数
cut(x, n):将连续型变量x分割为有着n个水平的因子
cut(x, breaks, labels = NULL,
include.lowest = FALSE, right = TRUE, dig.lab = 3,
ordered_result = FALSE, ...)介绍一种按照日期范围——例如按照周、月、季度或者年——对其进行分组的超简便处理方式:R语言的cut()函数。
假设vector中存在以下示例数据:
vDates <- as.Date(c("2013-06-01", "2013-07-08", "2013-09-01", "2013-09-15")) #as.Data()函数的作用非常重要;如果没有它,R语言会认为以上内容仅仅是数字串而非日期对象
[1] "2013-06-01" "2013-07-08" "2013-09-01" "2013-09-15"
vDates.bymonth <- cut(vDates, breaks = "month")
[1] 2013-06-01 2013-07-01 2013-09-01 2013-09-01
Levels: 2013-06-01 2013-07-01 2013-08-01 2013-09-01
Dates <- data.frame(vDates, vDates.bymonth) 3、dplyr包
#dplyr中基本函数 filter——数据筛选(筛选观测值,行)
filter(Hdma_dat,pclass == 1)
#####################################
#dplyr中基本函数 select——子集选取(筛选变量,列)
select(Hdma_dat,pclass,survived) ##选择pclass变量

二、数据分组以及分组汇总
1、cut函数
b<- cut(a, 5,labels=F) #将数据平均分成5组,rank=5代表大,rank=1代表小2、aggregate函数——分组汇总
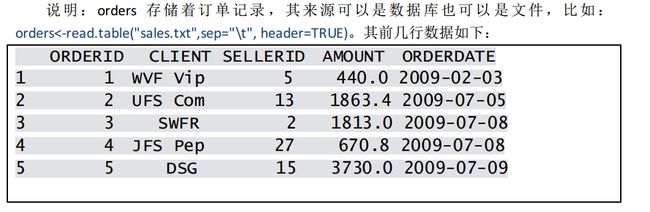
result1<-aggregate(orders$AMOUNT, orders[,c("SELLERID","CLIENT")],sum)
result2<-aggregate(orders$AMOUNT, orders[,c("SELLERID","CLIENT")],max)
result<-cbind(result1,result2$x)代码解读:
1.从名字就可以看出,aggregate是专用于分组汇总的函数,它的输入参数和计算结果都是数据框,用法相对简单。
2.aggregate函数不能对分组后的数据进行多种汇总计算,因此要用两句代码分别实现sum和max算法,最后再用cbind拼合。显然,上述代码在性能和易用性上存在不足。
3.aggregate函数对分组字段的顺序有一个奇怪的要求:必须反向排列。鉴于这个怪要求,先对CLIENT分组再对SELLERID分组就必须写成:orders[,c("SELLERID","CLIENT")]。如果按照正常的思维习惯写代码,结果将是错误的。
4.不仅代码的写法违反正常的思维习惯,计算后的结果也很怪异:SELLERID字段会排在CLIENT之前。事实上,为了使计算结果更符合业务逻辑,上述的代码还要继续加工才行。
总结:aggregate函数勉强可用,但在性能和方便性上存在不足,代码的写法、计算结果、业务逻辑这三者不一致。
三、split – apply – combine模式——分组处理模式
对数据的转换,可以采用split – apply – combine模式来进行处理:
split:把要处理的数据分割成小片断;
apply:对每个小片断独立进行操作;
combine:把片断重新组合。
R 当中是split( ),*apply( ),aggregate( )…,以及plyr包
1、split函数
split( )的基本用法是:group <- split(X,f)
其中X 是待分组的向量,矩阵或数据框。f是分组因子。
##按照已有的类别数据,分类
g<-split(Cars93,Cars93$Origin) #按照cars93数据集,按照origin进行分组
##例2:对矩阵分组(按列)
m<-cbind(x=1:10,y=11:20)
split(m,col(m)) #col代表m的下标(行)
$`1`
[1] 1 2 3 4 5 6 7 8 9 10
$`2`
[1] 11 12 13 14 15 16 17 18 19 20
> col(m)
[,1] [,2]
[1,] 1 2
[2,] 1 2
[3,] 1 2
[4,] 1 2
[5,] 1 2
[6,] 1 2
[7,] 1 2
[8,] 1 2
[9,] 1 2
[10,] 1 2
##后续处理
##计算组的长度和组内均值
> sapply(g,length)
USA non-USA
48 45
> sapply(g,mean)
USA non-USA
18.57292 20.50889
##用lapply也可以,返回值是列表
> lapply(g,mean)
$USA
[1] 18.57292
$`non-USA`
[1] 20.50889
##分组结果
summary(g)split还有一个逆函数,unsplit,可以让分组完好如初。
在base包里和split功能接近的函数有cut(对属性数据分划),strsplit(对字符串分划)以及subset(对向量,矩阵或数据框按给定条件取子集)等。
举例:
a<-matrix(1:20,ncol=4)
[,1] [,2] [,3] [,4]
[1,] 1 6 11 16
[2,] 2 7 12 17
[3,] 3 8 13 18
[4,] 4 9 14 19
[5,] 5 10 15 20
a[row(a)==1&col(a)==1] #将返回1, 第一行第一列
a[row(a)==1&col(a)==2] #将返回6, 第一行第二列2、一个网络例子:
sp<-split(orders,orders[,c("SELLERID","CLIENT")],drop=TRUE)
result1<-lapply(sp,FUN=function(x) sum(x$AMOUNT))
result2<-lapply(sp,FUN=function(x) max(x$AMOUNT))
result<-cbind(result1,result2)代码解读:
1.Split函数的作用是将数据框按照指定字段分组,但不做后续计算。lapply函数可以对每组数据都执行同样的算法。Split和lapply两者结合可以实现本案例。
2.由于分组后的数据可以复用,因此本算法比aggregate性能更高。
3.Lapply函数也不支持多种统计方法,因此也要用两句代码分别实现sum和max算法,最后再用cbind拼合。另外,本算法还要额外用到split函数,因此在易用性上没有改进,反而是更差了。
4.分组顺序仍然要违反正常的思维习惯,必须反写成:orders[,c("SELLERID","CLIENT")]。
5.计算结果需要大幅加工,很不方便。可以看到,计算结果中的第一列实际上是“SELLERID.CLIENT”,我们需要把它拆分成两列并调换顺序才行。
总结:
本算法在性能上有所提高,但在易用性上明显不足,在代码写法、业务逻辑、计算结果上仍然存在不一致。
3、Lapply 是 apply 函数族
Lapply 是 apply 函数族的一份子,类似的函数还有 sapply 和 tapply。其中 sapply 的用法和 lapply 的区别只在参数上,如下:
sp<-split(orders,orders[,c("SELLERID","CLIENT")],drop=TRUE)
result1<-sapply(sp,simplify=FALSE,FUN=function(x) sum(x$AMOUNT))
result2<-sapply(sp,simplify=FALSE,FUN=function(x) max(x$AMOUNT))
result<-cbind(result1,result2)tapply 专用于数据框,按理说最适合解决本案例,但事实并非如此。 tapply 只对单字段分组适用,在进行双字段联合分组时其结果为二维矩阵,用户还需要进行复杂的处理才行,比如 tapply(orders$AMOUNT, orders[,c("SELLERID","CLIENT")],function(x) sum(x))
4、subset()函数
利用subset()函数进行访问和选取数据框的数据更为灵活,subset函数将满足条件的向量、矩阵和数据框按子集的方式返回。subset(x, subset, ...)
subset(x, subset, select, drop = FALSE, ...) ##对于矩阵
subset(x, subset, select, drop = FALSE, ...) ##对于数据框
x是对象,subset是保留元素或者行列的逻辑表达式,对于缺失值用NA代替。
Select 是选取的范围,应小于x。
> x<-data.frame(matrix(1:30,nrow=5,byrow=T))
> rownames(x)=c("one","two","three","four","five")
> colnames(x)=c("a","b","c","d","e","f")
> x
> new<-subset(x,a>=14,select=a:f)
> new ## 从a到f列选取a>14的行。5、which定位函数
功能:返回服从条件的观测所在位置(行数),有一定的排序功能在其中。可见order用法
subset()在数据集中非常好用,which是针对较小的数据筛选,比较低纬度的数据筛选时候可以用的。
subset=which+数据集操作
which=order+多变量运行。
data$V1[which(data$V2<0)] #筛选出V1中,V2小于0的数字,跟order的作用些许相似
#order用法
iris$Sepal.Length[order(iris$setosa)] #按照照setosa的大小,重排Sepal.Length数据列 每每以为攀得众山小,可、每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~
——————————————————————————————————————————————————————————————
四、dplyr与data.table
data.table可是比dplyr以及python中的pandas还好用的数据处理方式。
data.table包的语法简洁,并且只需一行代码就可以完成很多事情。进一步地,data.table在某些情况下执行效率更高。(参考来源:R高效数据处理包dplyr和data.table,你选哪个?)

在使用data.table时候,需要预先布置一下环境:
data<-data.table(data)如果不布置环境,很多内容用不了。data.table包提供了一个非常简洁的通用格式:DT[i,j,by],可以理解为:对于数据集DT,选取子集行i,通过by分组计算j。
最让我在意的是分组汇总这块内容:
mygroup= group_by(data,gender,ID)
from_dplyr<-summarize(mygroup,mean=mean(mortgage)) #dplyr用两步
from_data_table<-try[,.(mean=mean(mortgage)),by=.(gender,ID)] #data.table用一步data.table比较简洁一步搞定,dplyr花了两步,不过也dplyr也可以通过%>%来实现一步搞定。%>%的功能是用于实现将一个函数的输出传递给下一个函数的第一个参数。
from_dplyr=data %>% group_by(gender,ID) %>% summarize(mean=mean(mortagage))