C++ STL(第十五篇:hashtable)
1、hashtable
hashtable 的目的是为了提供任何操作都是常数级别。SGI STL 中, hash table 使用了 开链法 实现的。大致的意思如下图所示:
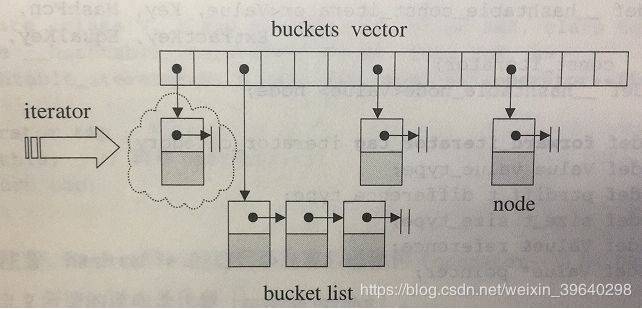
hash table 内的元素为 桶子(bucket),每个桶子里面有很多节点。其实有点像我们前面整理的 deque(双端队列),双端队列主控是个指向指针的指针,而hash table是一个vector;双端队列缓冲区是一块连续内存,像是array,而hash table 则是一个类似的单向链表。一下便是一个node节点的结构:
template
struct __hashtable_node
{
__hashtable_node* next;
Value val;
}
2、hashtable 迭代器
hashtable 迭代器必须永远维系着与整个 “buckets vector” 的关系,并记录目前所指的节点。前进时,如果正巧是list 的尾端,则跳到下一个节点。因为使用了类似单向链表的结构,所以迭代器类型是 forward_iterator_tag(前向迭代器)。迭代器的定义如下:
template
struct __hashtable_iterator
{
typedef forward_iterator_tag iterator_category;
typedef Value value_type;
typedef ptrdiff_t difference_type; //迭代器萃取那一套
...
node* cur; //迭代器目前所指节点
hashtable* ht; //保持对容器的连接关系(可能需要从当前 bucket 跳到下一个 bucket)
//其它操作就不写了,这里只写一下 operator++的操作
iterator operator++()
{
const node* old = cur;
cur = cur->next;
if( !cur ) //如果到了当前 bucket 的尾端
{
size_type bucket = ht->bkt_num(old->val); //根据元素值,定位出下一个bucket
while( !cur && ++bucket < ht->buckets.size() )
cur = ht->buckets[bucket];
}
return *this;
}
}
3、hashtable 的数据结构
hashtable 的模板参数比较多,包括:
Value:节点的实值型别
Key:节点的键值型别
HashFcn:hash function 的函数型别
ExtractKey:从节点中取出键值的方法(函数或仿函数)
EqualKey:判断键值相同与否的方法
Alloc:空间配置器
template
class hashtable
{
public:
typedef HashFcn hasher;
typedef EqualKey key_equal;
typedef size_t size_type;
private:
typedef __hashtable_node node;
haser hash;
key_equal equals;
ExtractKey get_key;
vector buckets; //中控表格
size_type num_elements; //所有链表元素的个数
};
hashtable 中控表格的大小一般设计为一个质数,至于为什么大家需要自行百度,这里我讲不明白。SGI STL 中先把 28 个质数准备好,以备随时访问,同时提供一个函数,用来查询在这 28 个质数之中,“最接近某数并大于某数” 的质数:
static const int __stl_num_primes = 28;
static const unsigned long __stl_prime_list[__stl_num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473ul, 4294967291ul
};
//以下是找出,最接近并大于或等于n的那个质数
inline unsigned long __stl_next_prime(unsigned long n)
{
const unsigned long* first = __stl_prime_list;
const unsigned long* last = __stl_prime_list + __stl_num_primes;
//lower_bound 是一个泛型算法
const unsigned long* pos = lower_bound(first, last, n);
}
4、hashtable操作
hashtable 的插入 跟 RB-tree 的插入类似,有两种插入方法 insert_unique 和 insert_equal ,意思也是一样的,insert_unique 不允许有重复值,而 insert_equal 允许有重复值。
因为都会用到是否需要重建表格的判断,我们先来整理这一部分:
template
void hashtable::resize(size_type num_elements_hint)
{
//判断 “表格重建与否” 是拿元素个数和 bucket vector 的大小来比,如果前者大于后者,就重建表格
//所以 每个 bucket list 的最大容量和 bucket vector 的大小相同
const size_type old_n = buckets.size();
if( num_elements_hint > old_n )
{
const size_type n = next_size(num_elements_hint); //next_size 底层调用 __stl_next_prime()
if( n > old_n)
{
vector tmp(n, (node*) 0); //设立新的 buckets
//以下是处理每一个旧的 bucket
for( size_type bucket = 0; bucket < old_n; ++bucket )
{
node* first = buckets[bucket]; //指向节点所对应之串行的起始节点
while( first ) //串行还没结束
{
//找出当前节点应该放在 新buckets 的哪一个位置
size_type new_bucket = bkt_num(first->val, n);
//以下就是对新旧表格的处理,同时还要维护好 first 指针
buckets[bucket] = first->next;
first->next = tmp[new_bucket];
tmp[new_bucket] = first;
first = buckets[bucket];
}
buckets.swap( tmp ); //vector::swap 函数,新旧两个buckets对调,对调之后释放tmp内存
}
}
}
}
现在来看一下 insert_unique 函数,需要注意的是插入时,新节点直接插入到链表的头节点,代码如下:
pair insert_unique(const value_type& obj)
{
resize(num_elements + 1);
return insert_unique_noresize(obj);
}
pair insert_unique_noresize(const value_type& obj)
{
const size_type n = bkt_num(obj); //决定 obj 应位于 buckets 的那一个链表中
node* first = buckets[n];
//遍历当前链表,如果发现有相同的键值,就不插入,立刻返回
for( node* cur = first; cur; cur = cur->next)
{
if( equals(get_key(cur->val), get_key(obj)) )
return pair(iterator(cur, this), false);
}
//离开以上循环(或根本未进入循环)时,first指向 bucket 所指链表的头节点
node* tmp = new_node(obj); //产生新节点
tmp->next = first;
buckets[n] = tmp; //令新节点为链表的第一个节点
++num_elements; //节点个数累加1
return pair( iterator(tmp,this), true);
}
允许重复插入的 insert_equal,需要注意的是插入时,重复节点插入到相同节点的后面,新节点还是插入到链表的头节点,代码如下:
iterator insert_equal(const value_type& obj)
{
resize( num_elements + 1 ); //判断是否 需要重建表格,如需要就扩充
return insert_equal_noresize(obj);
}
iterator insert_equalnoresize(const value_type& obj)
{
const size_type n = bkt_num(obj); //决定 obj 应位于 buckets 的那一个链表中
node* first = buckets[n];
//遍历当前链表,如果发现有相同的键值,就马上插入,立刻返回
for( node* cur = first; cur; cur = cur->next)
{
if( equals(get_key(cur->val), get_key(obj)) )
{
node* tmp = new_node(obj);
tmp->next = cur->next; //新节点插入当前节点位置之后
cur->next = tmp;
++num_elements;
return iterator(tmp, this);
}
}
//运行到这里,表示没有发现重复的键值
node* tmp = new_node(obj); //产生新节点
tmp->next = first;
buckets[n] = tmp; //令新节点为链表的第一个节点
++num_elements; //节点个数累加1
return iterator(tmp, this);
}
整体的删除操作 clear,代码如下:
void clear()
{
for( size_type i = 0; inext;
delete_node(cur);
cur = next;
}
buckets[i] = 0; //令bucket内容为null指针
}
num_elements = 0; //令总节点个数为 0
//注意:buckets vector 并未释放掉空间,扔保留原来大小
}
复制操作 copy_from,代码如下:
void copy_from(const hashtable& ht)
{
//先清除己方的 buckets vector
buckets.clear();
buckets.reserve(ht.buckets.size());
//从己方的 buckets vector 尾端开始,插入 n 个元素,其值为 null 指针
buckets.insert(buckets.end(), ht.buckets.size(), (node*)0);
//真正的执行复制操作
for(size_type i = 0; i < ht.buckets.size(); ++i)
{
if( const node* cur = ht.bucktes[i] )
{
node* copy = new_node(cur->val);
buckets[i] = copy;
for(node* next = cur->next; next; cur = next, next = cur->next)
{
copy->next = new_node(next->val);
copy = copy->next;
}
}
}
}
hashtable 使用时,一开始是53个元素节点,因为咱上面28个质数中,最小的是53。也就是说 buckets vector 保留的是 53 个bucket,每个 bucket 是一个指针,初始值为 null。如果,我们循序加入 6 个元素:59,63,108,2,53,55,于是 hashtable 变成如下图的样子:

59 除 53 余数为 6,所以放到第六个bucket中,同理,63放第十个bucket中,而108,2,55都放在第二个 bucket 中。
如果,我们在插入48个元素(0~47),是总数达到54个元素,则超过了 buckets vector 的大小,符合表格重建的条件,hashtable扩充到第二个质数 97。然后排列如下所示:
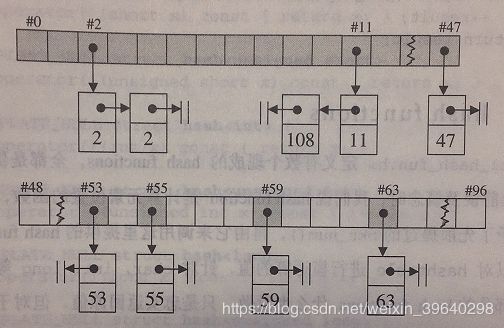
hashtable 进行了重整,bucket 2 和 bucket 11 的节点个数都是 2,其余的灰色bucket,节点个数都是1。白色 bucket 表示节点个数为0。
注意:hashtable 中,键值相同的元素,一定落在用一个 bucket list 中。
5、其它
至于hash_set、hash_map、hash_multiset、hash_multimap 与 set、map等原理是一样的,只不过 set 底层用的是 RB-tree,而 hash_set 用的是 hash。我们只整理了 hash 开链的实现,其实还有其它方法来实现hash,这里我们就不整理了。
在 C++ 11 中提供了标准的 hash_set 等容器,那就是 unordered_set、unordered_map等,看名字意味着无序排列。通过上面的总结,我们也能看出 hash_set 确实是无序的,它把所有取余相同的都放在同一个 bucket 下,但是并不进行排序。
感谢大家,我是假装很努力的YoungYangD(小羊)。
参考资料:
《STL源码剖析》