机器学习之基于水色图像的水质评价
机器学习之基于水色图像的水质评价
一、案例背景
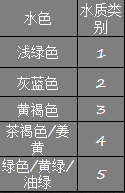
- 水质等级最高为10分,请为以下水质打分:

- 水产养殖
水产养殖的关键因素之一是水质
养殖水体生态系统的平衡状况可通过水质颜色体现
传统水质监控的关键:行家
- 依赖人(专家)的局限性
对个人经验要求高
存在主观性引起的观察性偏差
观察结果的可比性、可重复性不高,不易推广应用
- 在线水质监测
1.计算机视觉
2.数字图像处理技术
3.专家经验(专家数据)
4.机器学习算法
- 原始数据

- 水质分类标准
二、挖掘目标
请根据水质图片,利用图像处理技术和相应模型,实现水质的自动评价。

三、分析方法与过程
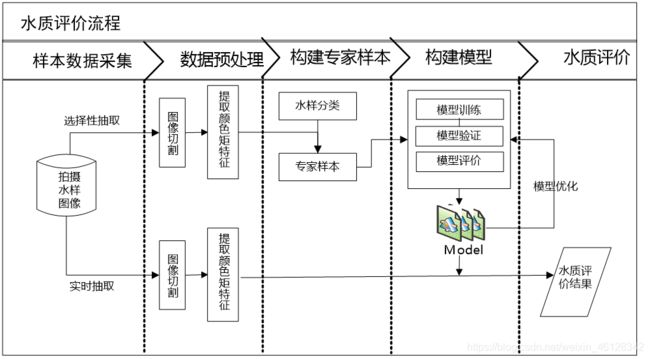
- 采集水样图像
- 特征提取
- 图像特征主要包括:颜色特征、纹理特征、形状特征、空间关系特征等。
- 与几何特征相比,颜色特征更为稳健,对于物体的大小和方向均不敏感,表现出较强的鲁棒性。
- 本案例中由于水色图像是均匀的,故主要关注颜色特征。

四、数据预处理
- 数据转化(Python)
图片转像素值矩阵:PIL Image.open()
r,g,b = im.split() #分成3个颜色通道
r_d = np.asarray® #取出各通道像素值 - 图像切割

- 颜色特征
颜色直方图:反映的是图像中颜色的组成分布,即出现了哪些颜色以及各种颜色出现的概率。其优点在于它能简单描述一幅图像中颜色的全局分布,即不同色彩在整幅图像中所占的比例,特别适用于描述那些难以自动分割的图像和不需要考虑物体空间位置的图像。其缺点在于它无法描述图像中颜色的局部分布及每种色彩所处的空间位置,即无法描述图像中的某一具体的对象或物体。
颜色矩:图像中任何的颜色分布均可以用它的矩来表示。根据概率论,随机变量的概率分布可以由其各阶矩唯一的表示和描述。一副图像的色彩分布也可认为是一种概率分布,那么图像可以由其各阶矩来描述。颜色矩包含各个颜色通道的一阶距、二阶矩和三阶矩,对于一幅RGB颜色空间的图像,具有R、G和B三个颜色通道,则有9个分量。
颜色直方图产生特征维数一般大于颜色矩的特征维数,为了避免过
多变量影响后续的分类效果,在本案例采用颜色矩来提取水样图像的特征。
- 特征提取:各阶颜色矩
一阶颜色矩:采用一阶原点矩,反映了图像的整体明暗程度。
![]()
二阶颜色矩:采用二阶中心矩的平方根,反映了图像颜色的分布范围。
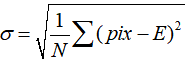
三阶颜色矩:采用三阶中心矩的立方根,反映了图像颜色分布的对称性。
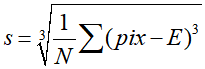
- 颜色矩特征提取后的数据集
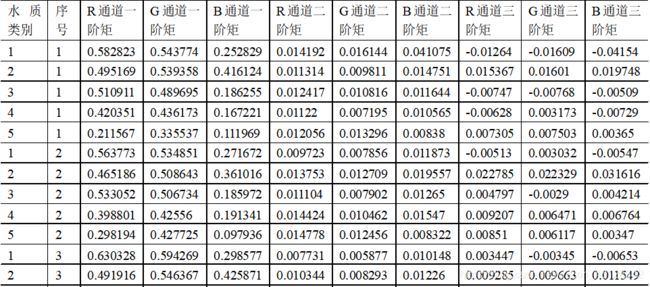
五、模型构建与评价 - 抽取80%作为训练样本,剩下的20%作为测试样本。
- 用训练集样本对模型进行训练。
- 用测试集样本对模型性能进行评价。

相关代码如下:(其中可以点击此处获取原始数据的照片样本即water-images)
#data-procss文件
#进行数据处理
import os, re #调用os,re正则表达式
from PIL import Image #通过PIL库导入照片类
import numpy as np
#自定义函数获取指定路径中的所有图片名称
path = 'water_images/'
def get_img_names(path=path):
file_names = os.listdir(path)
img_names = []
for i in file_names:
if re.findall('\d_\d+\.jpg$',i) !=[] : #\d表示数字,\d+表示至少一个数字,\.运用\表示转意符号,$表示结尾
img_names.append(i) #append对元素i的追加
return img_names
def var(rd): #求颜色通道的三阶颜色距
mid = np.mean((rd-rd.mean())**3)
return np.sign(mid)*abs(mid)**(1/3)
#获取样本数据:自变量data和标签 labels
def get_img_data(path=path):
img_names = get_img_names(path=path) #获取所有图片的名称
n = len(img_names)
data = np.zeros([n,9]) #data保存所有样本自变量
labels = np.zeros([n]) #样本标签
for i in range(n):
img = Image.open(path+img_names[i]) #读取图片数据
M, N = img.size #像素矩阵的行列数
box = (M/2-50, N/2-50, M/2+50, N/2+50)
region = img.crop(box) #用crop方法截取图像的中心区域
#region.show()
#img.show() #展示图片
#数据预处理
r, g, b = region.split() #分割像素通道
rd = np.asarray(r) #把图片数据转换为数组
gd = np.asarray(g)
bd = np.asarray(b)
data[i, 0] = rd.mean() #一阶颜色距
data[i, 1] = gd.mean()
data[i, 2] = bd.mean()
data[i, 3] = rd.std() #二阶颜色距
data[i, 4] = gd.std()
data[i, 5] = bd.std()
data[i, 6] = var(rd) #三阶颜色距
data[i, 7] = var(gd)
data[i, 8] = var(bd)
labels[i] = img_names[i][0]
return data, labels
#main
#模型构建与性能评估
from data_process import get_img_data # 导入数据预处里的函数
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
data, labels = get_img_data() # 数据预处理
data_tr, data_te, labels_tr, labels_te = train_test_split(data, labels, test_size=0.2) # 将专家样本拆分为训练集和测试集
Dtc = DecisionTreeClassifier().fit(data_tr, labels_tr) # 模型训练
pre = Dtc.predict(data_te) # 模型预测
sum(pre==labels_te)/len(pre) # 预测精度
confusion_matrix(labels_te, pre) # 混淆矩阵
classification_report(labels_te, pre) # 分类性能报告
运行结果:
