hwui大概流程和FrameInfo统计信息
Android hwui硬件加速从3.0版本开始引入到7.0已经非常复杂,这里总结下大致的流程和原理
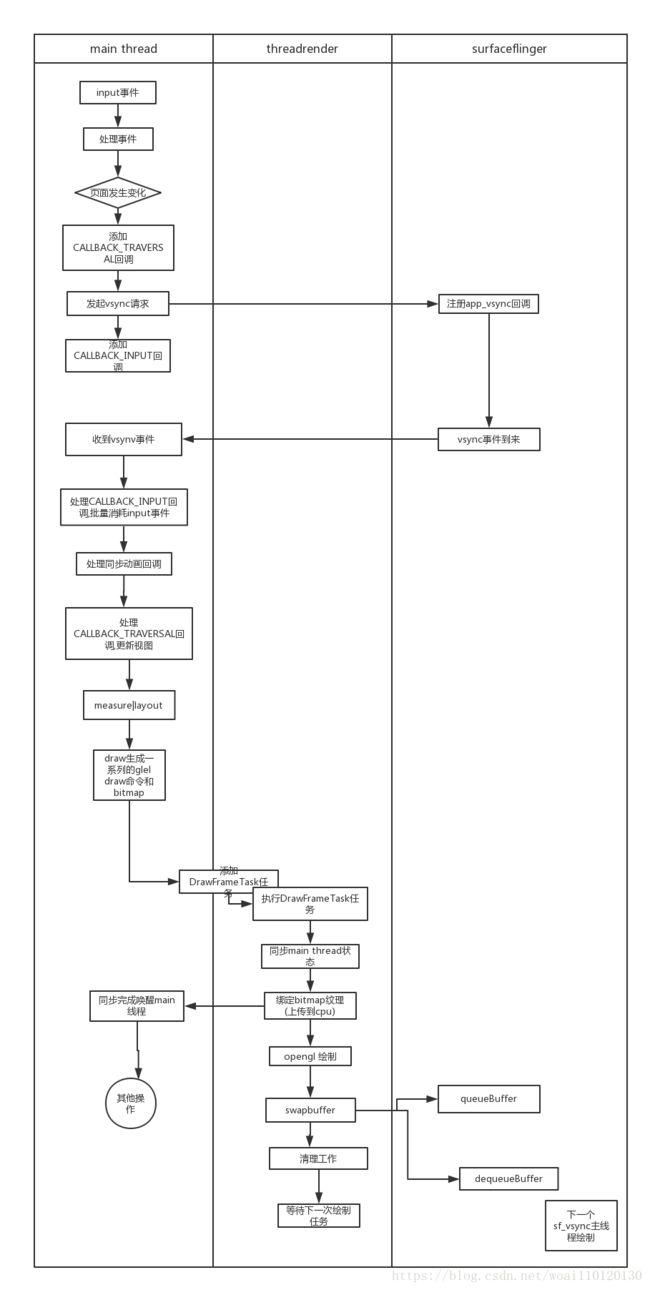
如果input的down事件到来,有些view接收到事件要求系统重绘就会调用到ViewRootImpl.scheduleTraversals()方法如下代码
void scheduleTraversals() {
if (!mTraversalScheduled) {
mTraversalScheduled = true;
mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();
mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
if (!mUnbufferedInputDispatch) {
scheduleConsumeBatchedInput();
}
notifyRendererOfFramePending();
pokeDrawLockIfNeeded();
}
}首先添加一个Choreographer.CALLBACK_TRAVERSAL回调函数,等待app vsync(vyns信号虚化)信号到来处理,
注意第一次添加回调会请求surfaceflinger发送app vsync事件给当前应用,之后调用scheduleConsumeBatchedInput()
void scheduleConsumeBatchedInput() {
if (!mConsumeBatchedInputScheduled) {
mConsumeBatchedInputScheduled = true;
mChoreographer.postCallback(Choreographer.CALLBACK_INPUT,
mConsumedBatchedInputRunnable, null);
}
}添加一个CALLBACK_INPUT回调用于在 app vsynv到来后处理批量input事件.
之后vsync事件到来,会执行到Choreographer.doFrame()方法,下面是关键步骤
ry {
Trace.traceBegin(Trace.TRACE_TAG_VIEW, "Choreographer#doFrame");
mFrameInfo.markInputHandlingStart();
doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos);
mFrameInfo.markAnimationsStart();
doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos);
mFrameInfo.markPerformTraversalsStart();
doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos);
doCallbacks(Choreographer.CALLBACK_COMMIT, frameTimeNanos);
} finally {
Trace.traceEnd(Trace.TRACE_TAG_VIEW);
}
if (DEBUG_FRAMES) {
final long endNanos = System.nanoTime();
Log.d(TAG, "Frame " + frame + ": Finished, took "
+ (endNanos - startNanos) * 0.000001f + " ms, latency "
+ (startNanos - frameTimeNanos) * 0.000001f + " ms.");
}分如下几步处理
1.处理input回调处理事件,导致视图变化
2.处理同步动画
处理视图变化
处理属性动画
对于第3步会更新视图
这里要补充的背景知识就是硬件加速的知识,hwui里增加了一个线程render thread,会不断轮训新的绘制任务,app main线程在执行draw函数的时候
会生成一系列的绘制命令,(另外比较重要的是bitmap资源,如调用canvas.drawbitmap就要储存这个要绘制的图片). 将这些绘制命令保存好后最终会
交给render thread去绘制. 交给render thread处理其实就是向它的任务队列添加消息,然后在threadloop中处理,
处理的过程要和main线程进行数据同步,在同步的过程中main线程是被阻塞的,防止main线程返回去后修改ui. 同步中最重要的一个步骤就是上传bitmap
到gpu纹理.同步完成后就可以唤醒主线程去做事情了(这里也并不一定直接唤醒,有时候要等到render thread渲染完成才会唤醒),
之后render thread就可以义无反顾的进行opengl绘制了,绘制完成要调用swapbuffer去把buffer交给
surfaceflinger进行合成(swapbuffer的过程会调用queueBuffer给surfaceflinger数据,同时也会调用dequeueBuffer获取新的buffer用于下一帧绘制).
交换完buffer就是一些清理工作,之后进入睡眠等待下一次任务. 整个代码流程很长,也很复杂不详细列举代码.
对于先不唤醒main thread的情况就是上传的纹理太多超出了限制(默认一个应用做多70M),太多的意思是同时使用的纹理数据,不使用的可以释放(lrucache)
另外对于每一帧数据,hwui会统计如下信息,这里做出解释
enum class FrameInfoIndex {
Flags = 0,
IntendedVsync,
Vsync,
OldestInputEvent,
NewestInputEvent,
HandleInputStart,
AnimationStart,
PerformTraversalsStart,
DrawStart,
// End of UI frame info
SyncQueued,
SyncStart,
IssueDrawCommandsStart,
SwapBuffers,
FrameCompleted,
DequeueBufferDuration,
QueueBufferDuration,
// Must be the last value!
// Also must be kept in sync with FrameMetrics.java#FRAME_STATS_COUNT
NumIndexes
};Flags
enum { WindowLayoutChanged = 1 << 0, RTAnimation = 1 << 1, SurfaceCanvas = 1 << 2, SkippedFrame = 1 << 3,};
支持上四种flags 其中WindowLayoutChanged代表windowlayout发生变化(这里会多用wms),SkippedFrame跳帧
其他的还没分析清楚IntendedVsync app_vsync的时间
Vsync 开始处理vync事件的时间
OldestInputEvent 如上处理批量事件中最老的一个inputEvent的时间
NewestInputEvent 最新事件
HandleInputStart mainthread开始处理input事件的时间
AnimationStart mainthread开始处理动画的时间
PerformTraversalsStart mainthread开始遍历视图的时间
DrawStart mainthread开始执行draw函数的时间
SyncQueued 添加事件到ThreadRender的时间
SyncStart renderthread开始同步main thread数据的的时间
IssueDrawCommandsStart renderThread开始绘制的时间
SwapBuffers renderThread开始交换buffer的时间
FrameCompleted renderThread 完成交换buffer的时间
DequeueBufferDuration renderThread交换buffer中dequeueBuffer花费的时间
QueueBufferDuration renderThread queueBuffer的时间
DequeueBufferDuration 和 QueueBufferDuration如果时间比较长的话系统卡段的可能性比较达
如果发生windowlayout的话PerformTraversalsStart和DrawStart 之间间隔比较长的话有可能是系统卡顿引起