Nginx http_limit_req_module服务器请求限流
nginx 可以使用ngx_http_limit_req对服务器资源请求进行限制,这对使用ab等工具恶意压测服务器和cc(challenge Collapsar)会有一定的防范作用。防止用户恶意攻击刷爆服务器。
ngx_http_limit_req_module模块是nginx默认安装的,所以直接配置即可。
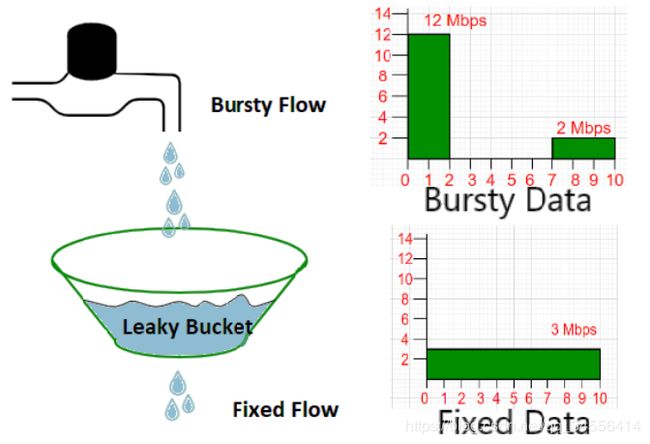
该模块使用漏斗算法(Leaky Bucket),该算法有两种处理方式Traffic Shaping和Traffic Policing
在桶满水之后,常见的两种处理方式为:
1.暂时拦截住上方水的向下流动,等待桶中的一部分水漏走后,再放行上方水。
2.溢出的上方水直接抛弃。
将水看作网络通信中数据包的抽象,则方式1起到的效果称为Traffic Shaping,方式2起到的效果称为Traffic Policing
由此可见,Traffic Shaping的核心理念是"等待",Traffic Policing的核心理念是"丢弃"。它们是两种常见的流速控制方法
nginx中该模块的使用配置示例

limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
server {
location /search/ {
limit_req zone=one burst=5 nodelay;
}
}
第一段配置
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
第一个参数:$binary_remote_addr是$remote_addr(客户端IP)的二进制格式,固定占用4个字节(可能是C语言的long类型长度),,是限制同一客户端ip地址。而$remote_addr按照字符串存储,占用7-15个字节。这样看来用$binary_remote_addr可以节省空间(“binary_”的目的是缩写内存占用量),但网上又说64位系统下都是占用64个字节,总之尽量用$binary_remote_addr吧
第二个参数:zone=one:10m表示:内存区域名称为one(自定义),占用空间大小为10m,,用来存储访问的频次信息
第三个参数:rate=1r/s表示允许相同标识的客户端的访问频次,这里限制的是每秒1次(平均处理的请求频率不能超过每秒一次),还可以有比如30r/m的
第二段配置
location /search/ {
limit_req zone=one burst=5 nodelay;
}第一个参数:zone=one 设置使用哪个配置区域来做限制,与上面limit_req_zone 里的name对应
第二个参数:burst=5,重点说明一下这个配置,burst爆发的意思,这个配置的意思是设置一个大小为5的缓冲区当有大量请求(爆发)过来时,超过了访问频次限制的请求可以先放到这个缓冲区内
第三个参数:nodelay字面的意思是不延迟,具体说是对用户发起的请求不做延迟处理,而是立即处理。比如我上面定义的rate=1r/s,即每秒钟只处理1个请求。如果同一时刻有两个后缀为/search的请求过来了,若设置了nodelay,则会立刻处理这两个请求。若没设置nodelay,则会严格执行rate=1r/s的配置,即只处理一个请求,然后下一秒钟再处理另外一个请求。直观的看就是页面数据卡了,过了一秒后才加载出来。
如果设置,超过访问频次而且缓冲区也满了的时候就会直接返回503,如果没有设置,则所有请求会等待排队
下面我们来分析一下具体案例
- 真正对限流起作用的配置就是rate=1r/s和burst=5这两个配置。
某一时刻有两个请求同时到达nginx,其中一个被处理,另一个放到了缓冲队列里。虽然配置了nodelay导致第二个请求也被瞬间处理了,但还是占用了缓冲队列的一个长度,如果下一秒没有请求过来,这个占用burst一个长度的空间就会被释放,否则就只能继续占用着burst的空间,直到burst空间占用超过5之后,再来请求就会直接被nginx拒绝,返回503错误码。
可见,如果第二秒又来了两个请求,其中一个请求又占用了一个burst空间,第三秒、第四秒直到第五秒,每秒都有两个请求过来,虽然两个请求都被处理了(因为配置了nodelay),但其中一个请求仍然占用了一个burst长度,五秒后整个burst长度=5都被占用了。第六秒再过来两个请求,其中一个请求就被拒绝了。
下面这个配置可以限制特定UA(比如搜索引擎)的访问
limit_req_zone $anti_spider zone=one:10m rate=10r/s;
limit_req zone=one burst=100 nodelay;
if ($http_user_agent ~* "googlebot|bingbot|Feedfetcher-Google") {
set $anti_spider $http_user_agent;
}
这里用到的$binary_remote_addr是在客户端和nginx之间没有代理层的情况。如果你在nginx之前配置了CDN,那么$binary_remote_addr的值就是CDN的IP地址。这样限流的话就不对了。需要获取到用户的真实IP进行限流。简单说明如下:
## 这里取得原始用户的IP地址
map $http_x_forwarded_for $clientRealIp {
"" $remote_addr;
~^(?P
}
## 针对原始用户 IP 地址做限制
limit_req_zone $clientRealIp zone=one:10m rate=1r/s;
同理,我们可以用limit模块对网络爬虫进行限流。
http模块
limit_req_zone $anti_spider zone=anti_spider:10m rate=1r/s;
server模块
location / {
limit_req zone=anti_spider burst=2 nodelay;
if ($http_user_agent ~* "spider|Googlebot") {
set $anti_spider $http_user_agent;
}
}
可以用curl -I -A "Baiduspider" www.remotejob.cn/notice.jsp 测试一下