www.allthingsdistributed.com/2007/10/amazons_dynamo.html , 英文版
http://blog.163.com/woshitony111@126/blog/static/71379539201231492557944/ , 中文版
1 Overview
Amazon服务平台中的许多服务只需要主键访问数据存储. 对于许多服务, 如提供最畅销书排行榜, 购物车, 客户的偏好, 会话管理, 销售等级, 产品目录, 常见的使用关系数据库的模式会导致效率低下, 有限的可扩展性和可用性. Dynamo提供了一个简单的主键唯一的接口, 以满足这些应用的要求
Dynamo uses a synthesis of well known techniques to achieve scalability and availability:
Data is partitioned and replicated using consistent hashing [10], and consistency is facilitated by object versioning [12].
The consistency among replicas during updates is maintained by a quorum-like technique and a decentralized replica synchronization protocol.
Dynamo employs a gossip based distributed failure detection and membership protocol.
Dynamo is a completely decentralized system with minimal need for manual administration. Storage nodes can be added and removed from Dynamo without requiring any manual partitioning or redistribution.
The main contribution of this work for the research community is the evaluation of how different techniques can be combined to provide a single highly-available system. It demonstrates that an
eventually-consistent storage system can be used in production with demanding applications. It also provides insight into the tuning of these techniques to meet the requirements of production systems with very strict performance demands.
Amazon Dynamo的贡献是整合这些技术提供一种eventually-consistent 的存储方案, 并证明其可以满足产品化的需求.
系统假设和要求
Query Model: simple read and write operations to a data item that is uniquely identified by a key. State is stored as binary objects (i.e., blobs) identified by unique keys. No operations span multiple data items and there is no need for relational schema. Dynamo targets applications that need to store objects that are relatively small (usually less than 1 MB).
ACID Properties: Experience at Amazon has shown that data stores that provide ACID guarantees tend to have poor availability. Dynamo targets applications that operate with weaker consistency (the “C” in ACID) if this results in high availability. Dynamo does not provide any isolation guarantees and permits only single key updates.
Efficiency: The system needs to function on a commodity hardware infrastructure.
Other Assumptions: Dynamo is used only by Amazon’s internal services. Its operation environment is assumed to be non-hostile and there are no security related requirements such as authentication and authorization.
这些是Dynamo的设计前提...
设计考虑
在早期商业系统中,
数据复制(Data replication)算法传统上执行同步的副本(replica)协调,以提供一个强一致性的数据访问接口。为了达到这个水平的一致性,在某些故障情况下,这些算法被迫牺牲了数据可用性。例如,与其不能确定答案的正确性与否,不如让该数据一直不可用直到它绝对正确时。
而我们设计Dynamo的想法是,
使用optimistic replication techniques来提高系统的可用性,其变化可以在后台传播到副本,同时,并发和断开(disconnected)是可以容忍的。
这种方法的挑战在于,它会导致更改冲突,而这些冲突必须检测并协调解决。
这种协调冲突的过程引入了两个问题:何时协调它们,谁协调它们,
when to resolve them and who resolves them
何时去协调更新操作冲突,即是否应该在读或写过程中协调冲突.
许多传统数据存储在写的过程中执行协调冲突过程,从而保持读的复杂度相对简单. 在这种系统中,如果在给定的时间内数据存储不能达到所要求的所有或大多数副本数,写入可能会被拒绝。
Dynamo的目标是一个“永远可写”(always writable)的数据存储(即数据存储的“写”是高可用)。对于Amazon许多服务来讲,拒绝客户的更新操作可能导致糟糕的客户体验。
所以在Dynamo的设计中, 只能将协调冲突的复杂性推给“读”,以确保“写”永远不会拒绝
谁执行协调冲突的过程。这可以通过data store or the application
If conflict resolution is done by the data store, its choices are rather limited. In such cases, the data store can only use simple policies, such as “last write wins” [22], to resolve conflicting updates.
客户应用程序,因为应用知道数据方案,因此它可以基于最适合的客户体验来决定协调冲突的方法。例如,维护客户的购物车的应用程序,可以选择“合并”冲突的版本,并返回一个统一的购物车。尽管具有这种灵活性,某些应用程序开发人员可能不希望写自己的协调冲突的机制,并选择下压到数据存储,从而选择简单的策略,例如“最后一次写入获胜”。
设计中包含的其他重要的设计原则是:
Incremental scalability: Dynamo should be able to scale out one storage host (henceforth, referred to as “node”) at a time, with minimal impact on both operators of the system and the system
itself.
Symmetry: Every node in Dynamo should have the same set of responsibilities as its peers; there should be no distinguished node or nodes that take special roles or extra set of responsibilities. In
our experience, symmetry simplifies the process of system provisioning and maintenance.
Decentralization: An extension of symmetry, the design should favor decentralized peer-to-peer techniques over centralized control. In the past, centralized control has resulted in outages and
the goal is to avoid it as much as possible. This leads to a simpler, more scalable, and more available system.
Heterogeneity: The system needs to be able to exploit heterogeneity in the infrastructure it runs on. e.g. the work distribution must be proportional to the capabilities of the individual servers. This is essential in adding new nodes with higher capacity without having to upgrade all hosts at once. 系统必须能够利用异质性的基础设施运行。例如,负载的分配必须与各个独立的服务器的能力成比例。这样就可以一次只增加一个高处理能力的节点,而无需一次升级所有的主机。
Dynamo有着不同的目标需求:
首先,Dynamo主要是针对应用程序需要一个“永远可写”数据存储,不会由于故障或并发写入而导致更新操作被拒绝。这是许多Amazon应用的关键要求。
其次,如前所述,Dynamo是建立在一个所有节点被认为是值得信赖的单个管理域的基础设施之上。
第三,使用Dynamo的应用程序不需要支持分层命名空间(许多文件系统采用的规范)或复杂的(由传统的数据库支持)关系模式的支持。
第四,Dynamo是为延时敏感应用程序设计的,需要至少99.9%的读取和写入操作必须在几百毫秒内完成。为了满足这些严格的延时要求,这促使我们必须避免通过多个节点路由请求(这是被多个分布式哈希系统如Chord和Pastry采用典型的设计)。这是因为多跳路由将增加响应时间的可变性,从而导致百分较高的延时的增加。Dynamo可以被定性为零跳(zero-hop)的DHT,每个节点维护足够的路由信息从而直接从本地将请求路由到相应的节点。
4系统架构
| Problem | Technique | Advantage |
| Partitioning |
Consistent Hashing |
Incremental |
| High Availability |
Vector clocks with |
Version size is |
| Handling temporary |
Sloppy Quorum and |
Provides high |
| Recovering from |
Anti-entropy using |
Synchronizes |
| Membership and |
Gossip-based |
Preserves symmetry and avoids having a centralized registry for storing |
4.1 系统接口
Dynamo stores objects associated with a key through a simple interface; it exposes two operations: get() and put() 典型的Key Value系统
The get(key) operation locates the object replicas associated with the key in the storage system and returns a single object or a list of objects with conflicting versions along with a context.
The put(key, context, object) operation determines where the replicas of the object should be placed based on the associated key, and writes the replicas to disk.
The context encodes system metadata about the object that is opaque to the caller and includes information such as the version of the object. The context information is stored along with the object so that the system can verify the validity of the context object supplied in the put request.
4.2 划分算法 (一致性hash算法)
Dynamo的关键设计要求之一是必须增量可扩展性, 并在扩展时尽量减少数据迁移.
Dynamo的分区方案依赖于Consistent Hashing, 相对于普通的Hash方法, 可以保证节点增删的时候, 仅仅影响相邻的节点, 大大减少了数据迁移.
One of the key design requirements for Dynamo is that it must scale incrementally. This requires a mechanism to dynamically partition the data over the set of nodes (i.e., storage hosts) in the
system. Dynamo’s partitioning scheme relies on consistent hashing to distribute the load across multiple storage hosts.
In consistent hashing [10], the output range of a hash function is treated as a fixed circular space or “ring” (i.e. the largest hash value wraps around to the smallest hash value). Each node in the
system is assigned a random value within this space which represents its “position” on the ring. Each data item identified by a key is assigned to a node by hashing the data item’s key to yield its position on the ring, and then walking the ring clockwise to find the first node with a position larger than the item’s position.
The basic consistent hashing algorithm presents some challenges.
First, the random position assignment of each node on the ring leads to non-uniform data and load distribution.
Second, the basic algorithm is oblivious to the heterogeneity in the performance of nodes.
To address these issues, Dynamo uses a variant of consistent hashing (similar to the one used in [10, 20]):
instead of mapping a node to a single point in the circle, each node gets assigned to multiple points in the ring. To this end, Dynamo uses the concept of “virtual nodes”. A virtual node looks like a single node in the system, but each node can be responsible for more than one virtual node. Effectively, when a new node is added to the system, it is assigned multiple positions (henceforth, “tokens”) in the ring.
Using virtual nodes has the following advantages:
• If a node becomes unavailable (due to failures or routine maintenance), the load handled by this node is evenly dispersed across the remaining available nodes.
• When a node becomes available again, or a new node is added to the system, the newly available node accepts a roughly equivalent amount of load from each of the other available nodes.
• The number of virtual nodes that a node is responsible can decided based on its capacity, accounting for heterogeneity in the physical infrastructure.
说白了, 就是这样load比较平均, 而且对于heterogeneity, 不同instance的能力不同, 可以通过生成不同数量的virtual nodes来进行load balance.
4.3 复本备份
Dynamo将复本备份机制和一致性hash算法融合在了一起, 巧妙的利于一致性hash的特点, 保证在当node fail时, 也可以在用户透明的情况下, 一次访问读到数据.
而如果你采用其他的备份方法, 当node fail时, 用户至少要两次访问才能读到数据, 一次访问失败(由于node fail), 第二次读backup replica.
而Dynamo的复本策略, replica会被存到顺时针的N个节点上, 当一个节点fail时, 按照一致性hash算法, 会自动读到顺时针的下一个replica.
To achieve high availability and durability, Dynamo replicates its data on multiple hosts. Each data item is replicated at N hosts
The coordinator is in charge of the replication of the data items that fall within its range. In addition to locally storing each key within its range, the coordinator replicates these keys at the N-1 clockwise successor nodes in the ring. This results in a system where each node is responsible for the region of the ring between it and its Nth predecessor.
In Figure 2, node B replicates the key k at nodes C and D in addition to storing it locally. Node D will store the keys that fall in the ranges (A, B], (B, C], and (C, D].
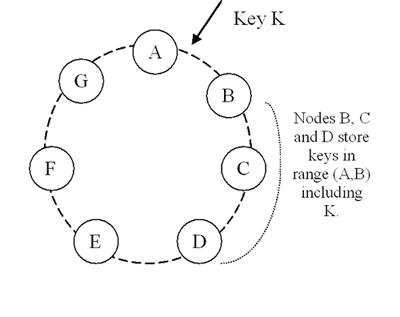
The list of nodes that is responsible for storing a particular key is called the preference list.
To account for node failures, preference list contains more than N nodes.
Note that with the use of virtual nodes, it is possible that the first N successor positions for a particular key may be owned by less than N distinct physical nodes. To address this, the
preference list for a key is constructed by skipping positions in the ring to ensure that the list contains only distinct physical nodes.
4.4版本化的数据
因为Dynamo的场景, 决定需要支持高可用, 即多复本的并发写, 这样很容易产生写冲突.
容易想到, 为了记录数据并发写之间的关系, 可以通过给数据增加版本号来控制,
为了保证版本号的一致性, 简单的策略是, 用一台单独的服务器作为全局版本服务器, 所有的并发写都必须首先去获取version, 当然问题很明显, 单点问题, 当写操作量很大时, 负载和响应时间问题.
所以Dynamo采用了比较复杂的, 分布式的局部版本策略, 每个replica只负责维护局部版本, 并不断的把局部版本更新情况传播给其他的复本, 同时也在不断接收其他复本的版本更新.
这就会产生多版本的合并, 称为reconciliation, 如果不存在冲突, 系统可用自动完成合并, 称为syntactic reconciliation.
但是当存在不同版本之间的冲突的时候, 系统无法自动完成合并, 只能保留多个冲突版本, 等client来读数据的时候, 由client来决定怎样合并, 称为semantic reconciliation.
Dynamo采取这样的策略, 解决了Write-Write consistency问题, 特别是Read-modify-write conflict detectioin.
read的时候同时得到context, 包含该对象多个版本时间向量(如果有冲突多版本的话), client负责进行semantic reconciliation.
然后modify, 并写回的时候, 必须指明你更新的版本(时间向量), 即你之前读到的版本, 从而可以detect Read-modify-write冲突.
Dynamo provides eventual consistency, which allows for updates to be propagated to all replicas asynchronously.
A put() call may return to its caller before the update has been applied at all the replicas, which can result in scenarios where a subsequent get() operation may return an object that does not have the latest updates. 这样会导致读写不同步, 读到老版本的数据, 并可能在老版本上进行更新, 所以必须给数据更新加上版本信息.
对于这种数据的暂时不一致, 并不是所有的场景都可以容忍, 比如银行... 在Amazon的平台,有一种类型的应用可以容忍这种不一致,购物车应用. 购物车应用程序要求写操作永久可用, 如果购物车的最近的状态是不可用,并且用户对一个较旧版本的购物车做了更改,这种变化仍然是有意义的并且应该保留。但同时它不应取代当前不可用的状态,而这不可用的状态本身可能含有的变化也需要保留。请注意在Dynamo中“添加到购物车“和”从购物车删除项目“这两个操作被转成put请求。当客户希望增加一个项目到购物车(或从购物车删除)但最新的版本不可用时,该项目将被添加到旧版本(或从旧版本中删除)并且不同版本将在后来协调(reconciled)
In order to provide this kind of guarantee, Dynamo treats the result of each modification as a new and immutable version of the data. It allows for multiple versions of an object to be present in
the system at the same time. Most of the time, new versions subsume the previous version(s), and the system itself can determine the authoritative version (syntactic reconciliation).
However, version branching may happen, in the presence of failures combined with concurrent updates, resulting in conflicting versions of an object. In these cases, the system cannot reconcile the multiple versions of the same object and the client must perform the reconciliation in order to collapse multiple branches of data evolution back into one (semantic reconciliation).
A typical example of a collapse operation is “merging” different versions of a customer’s shopping cart. Using this reconciliation mechanism, an “add to cart” operation is never lost. However, deleted items can resurface.
Dynamo uses vector clocks [12] in order to capture causality (因果关系) between different versions of the same object.
A vector clock is effectively a list of (node, counter) pairs. One vector clock is associated with every version of every object. One can determine whether two versions of an object are on parallel branches or have a causal ordering, by examine their vector clocks.
If the counters on the first object’s clock are less-than-or-equal to all of the nodes in the second clock, then the first is an ancestor of the second and can be forgotten. Otherwise, the two changes are considered to be in conflict and require reconciliation.
In Dynamo, when a client wishes to update an object, it must specify which version it is updating. This is done by passing the context it obtained from an earlier read operation, which contains the vector clock information.
Upon processing a read request, if Dynamo has access to multiple branches that cannot be syntactically reconciled, it will return all the objects at the leaves, with the corresponding version information in the context. An update using this context is considered to have reconciled the divergent versions and the branches are collapsed into a single new version.
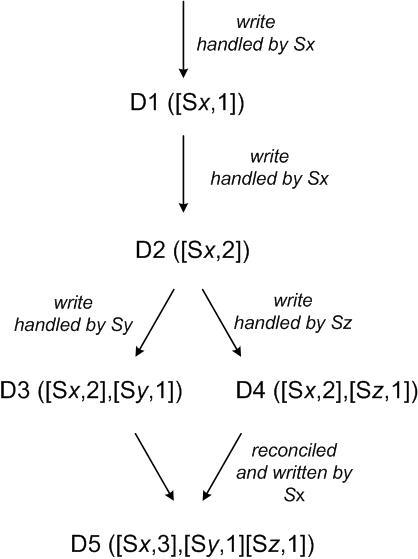
1) A client writes a new object.
The node (say Sx) that handles the write for this key increases its sequence number and uses it to create the data's vector clock.
The system now has the object D1 and its associated clock [(Sx, 1)].
2) The client updates the object.
Assume the same node handles this request as well. The system now also has object D2 and its associated clock [(Sx, 2)].
D2 descends from D1 and therefore over-writes D1, however there may be replicas of D1 lingering at nodes that have not yet seen D2.
3) Let us assume that the same client updates the object again and a different server (say Sy) handles the request.
The system now has data D3 and its associated clock [(Sx, 2), (Sy, 1)].
4) Next assume a different client reads D2 and then tries to update it, and another node (say Sz) does the write.
The system now has D4 (descendant of D2) whose version clock is [(Sx, 2), (Sz, 1)].
A node that is aware of D1 or D2 could determine, upon receiving D4 and its clock, that D1 and D2 are overwritten by the new data and can be garbage collected.
A node that is aware of D3 and receives D4 will find that there is no causal relation between them. In other words, there are changes in D3 and D4 that are not reflected in each other. Both versions of the data must be kept and presented to a client (upon a read) for semantic reconciliation.
5) Now assume some client reads both D3 and D4 (the context will reflect that both values were found by the read).
The read's context is a summary of the clocks of D3 and D4, namely [(Sx, 2), (Sy, 1), (Sz, 1)].
If the client performs the reconciliation and node Sx coordinates the write, Sx will update its sequence number in the clock.
The new data D5 will have the following clock: [(Sx, 3), (Sy, 1), (Sz, 1)].
A possible issue with vector clocks is that the size of vector clocks may grow if many servers coordinate the writes to an object.
如果数据处理的node变多, 那么vector clocks的size就会不断变大, 虽然在Dynamo中, 这个问题应该不常发生, 因为写入通常是由首选列表中的前N个节点中的一个节点处理.
但是如果发生, 解决的方法就是截断, 在向量内, 每个节点数据上加上时间戳, 定期把老的节点数据删除. 这个是一个折衷的方案.
显然,这个截断方案会导至在协调时效率低下,因为后代关系不能准确得到。不过,这个问题还没有出现在生产环境,因此这个问题没有得到彻底研究。
4.5执行get()和put()操作
Dynamo在处理request时, 两种策略
1. Client使用通用的load balance, 根据负载情况把request发送给load较轻的node.
但问题是只有coordinator(first among the top N nodes in the preference list)可以真正的handling a read or write operation. 所以接收到request的node如果不是coordinator, 他无法真正处理该request, 所以就会将request转发给相应的coordinator.
2. 在client保持集群一致性hash环, 这样可用直接将request发送给相应的coordinator. 高效的同时, client需要紧耦合, 不太优雅.
Both get and put operations are invoked using Amazon’s infrastructure-specific request processing framework over HTTP.
There are two strategies that a client can use to select a node:
(1) route its request through a generic load balancer that will select a node based on load information, or
(2) use a partition-aware client library that routes requests directly to the appropriate coordinator nodes.
The advantage of the first approach is that the client does not have to link any code specific to Dynamo in its application, whereas the second strategy can achieve lower latency because it
skips a potential forwarding step.
A node handling a read or write operation is known as the coordinator.
Typically, this is the first among the top N nodes in the preference list. If the requests are received through a load balancer, requests to access a key may be routed to any random node in the ring. In this scenario, the node that receives the request will not coordinate it if the node is not in the top N of the requested key’s preference list. Instead, that node will forward the request to the first among the top N nodes in the preference list.
同时Dynamo需要解决Read-Write consistency问题, 通过Quorum approach来解决, R + W > N, 即可保证至少读到一次最新的更新.
To maintain consistency among its replicas, Dynamo uses a consistency protocol similar to those used in quorum systems.
This protocol has two key configurable values: R and W.
R is the minimum number of nodes that must participate in a successful read operation.
W is the minimum number of nodes that must participate in a successful write operation.
Setting R and W such that R + W > N yields a quorum-like system.
In this model, the latency of a get (or put) operation is dictated by the slowest of the R (or W) replicas. For this reason, R and W are usually configured to be less than N, to provide better latency.
Upon receiving a put() request for a key, the coordinator generates the vector clock for the new version and writes the new version locally. The coordinator then sends the new version (along with
the new vector clock) to the N highest-ranked reachable nodes. If at least W-1 nodes respond then the write is considered successful.
Similarly, for a get() request, the coordinator requests all existing versions of data for that key from the N highest-ranked reachable nodes in the preference list for that key, and then waits for R
responses before returning the result to the client. If the coordinator ends up gathering multiple versions of the data, it returns all the versions it deems to be causally unrelated. The divergent versions are then reconciled and the reconciled version superseding the current versions is written back.
4.6故障处理:暗示移交(Hinted Handoff)
上一节介绍了通过Quorum approach来解决Read-Write consistency问题, 但是Dynamo集群经常会碰到server failures and network partitions的问题, 所以如果严格发给first N nodes , 可能会由于server failures 导致response数达不到R或W, 从而导致读写失败.
所以解决这个问题, 提出sloppy quorum, 当有节点fail时, 直接跳过, 将request发给first N healthy nodes, 来保证high可用性.
但这样带领的问题是, 当fail的节点恢复后, 需要将数据恢复 (因为下次读操作取first N healthy nodes, 它会被取到)
所以相对于sloppy quorum, 还需要配套的数据恢复策略, 就是hinted off策略, 底下给出了例子, D会把hinted replicas暂存在本地数据库里面, 不断的监控, 当A恢复了, 把hinted replicas handoff给A, 并在本地删除hinted replicas.
由衷佩服Dynamo团队给技术起名字的功力...
If Dynamo used a traditional quorum approach it would be unavailable during server failures and network partitions, and would have reduced durability even under the simplest of failure conditions.
To remedy this it does not enforce strict quorum membership and instead it uses a “sloppy quorum”;
All read and write operations are performed on the first N healthy nodes from the preference list, which may not always be the first N nodes encountered while walking the consistent hashing ring.
Consider the example of Dynamo configuration given in Figure 2 with N=3.
In this example, if node A is temporarily down or unreachable during a write operation then a replica that would normally have lived on A will now be sent to node D.
This is done to maintain the desired availability and durability guarantees. The replica sent to D will have a hint in its metadata that suggests which node was the intended recipient of the replica (in this case A). Nodes that receive hinted replicas will keep them in a separate local database that is scanned periodically. Upon detecting that A has recovered, D will attempt to deliver the replica to A. Once the transfer succeeds, D may delete the object from its local store without decreasing the total number of replicas in the system.
4.7处理永久性故障:副本同步
Hinted Handoff在系统成员流动性(churn)低,节点短暂的失效的情况下工作良好, 但是很多情况下, 复本同步还是必要的
比如前面的D在将hinted replicas handoff给A之前就发生crash, 那么就会导致A和其他的复本不一致
所以需要一种方式来保证N复本之间的一致性, 如果发现不一致, 需要进行同步...
在比较复本异同上, Dynamo使用了高效的Merkle tree技术, 只需要转播digest而不是data.
Dynamo使用anti-entropy 协议来传播digest经行复本同步, 对于Decentralized设计, 似乎anti-entropy 协议是最常用的同步协议
There are scenarios under which hinted replicas become unavailable before they can be returned to the original replica node.
To handle this and other threats to durability, Dynamo implements an anti-entropy (replica synchronization) protocol to keep the replicas synchronized.
To detect the inconsistencies between replicas faster and to minimize the amount of transferred data, Dynamo uses Merkle trees [13].
A Merkle tree is a hash tree where leaves are hashes of the values of individual keys. Parent nodes higher in the tree are hashes of their respective children.
The principal advantage of Merkle tree is that each branch of the tree can be checked independently without requiring nodes to download the entire tree or the entire data set.
Moreover, Merkle trees help in reducing the amount of data that needs to be transferred while checking for inconsistencies among replicas.
For instance, if the hash values of the root of two trees are equal, then the values of the leaf nodes in the tree are equal and the nodes require no synchronization.
If not, it implies that the values of some replicas are different. In such cases, the nodes may exchange the hash values of children and the process continues until it reaches the leaves of the trees, at which point the hosts can identify the keys that are “out of sync”.
Merkle trees minimize the amount of data that needs to be transferred for synchronization and reduce the number of disk reads performed during the anti-entropy process.
对于Merkle trees, 要解决的问题是, 你怎么知道哪些内容更新过, 是需要同步的? 最不济的方法是把整个dataset发过去, 这个方法明显不行, 效率太低了
使用用Merkle tree可以很好的解决这个问题, 可以看上面的例子, 很好理解, 赞叹这个方法真牛比...
Dynamo uses Merkle trees for anti-entropy as follows:
Each node maintains a separate Merkle tree for each key range (the set of keys covered by a virtual node) it hosts. This allows nodes to compare whether the keys within a key range are up-to-date. In this scheme, two nodes exchange the root of the Merkle tree corresponding to the key ranges that they host in common. Subsequently, using the tree traversal scheme described above the nodes determine if they have any differences and perform the appropriate synchronization action.
The disadvantage with this scheme is that many key ranges change when a node joins or leaves the system thereby requiring the tree(s) to be recalculated.
4.8 会员和故障检测
4.8.1 环会员(Ring Membership)
Dynamo一贯选择Decentralized的方案, 如果有master, 用于监控所有的node, 当监控到有membership的变化时, 将变化的配置同步给所有的node
而Decentralized的方案就比较麻烦, 每个节点start的时候只知道自己的情况, 并把这样的mapping信息保存在local disk上, 并互相通过gossip-based protocol进行传播和reconcile, 最终达到eventually consistent view of membership
所以每个节点上都存了所有节点的hash mapping的情况, 对于任何r/w request都可以直接forward至相应的coordinater
In Amazon’s environment node outages (due to failures and maintenance tasks) are often transient but may last for extended intervals. A node outage rarely signifies a permanent departure and therefore should not result in rebalancing of the partition assignment or repair of the unreachable replicas.
Similarly, manual error could result in the unintentional startup of new Dynamo nodes. For these reasons, it was deemed appropriate to use an explicit mechanism to initiate the addition and removal of nodes from a Dynamo ring. An administrator uses a command line tool or a browser to connect to a Dynamo node and issue a membership change to join a node to a ring or remove a node from a ring.
The node that serves the request writes the membership change and its time of issue to persistent store. The membership changes form a history because nodes can be removed and added back multiple times. A gossip-based protocol propagates membership changes and maintains an eventually consistent view of membership. Each node contacts a peer chosen at random every second and the two nodes efficiently reconcile their persisted membership change histories.
When a node starts for the first time, it chooses its set of tokens (virtual nodes in the consistent hash space) and maps nodes to their respective token sets. The mapping is persisted on disk and
initially contains only the local node and token set. The mappings stored at different Dynamo nodes are reconciled during the same communication exchange that reconciles the membership change
histories. Therefore, partitioning and placement information also propagates via the gossip-based protocol and each storage node is aware of the token ranges handled by its peers. This allows each
node to forward a key’s read/write operations to the right set of nodes directly.
4.8.2 外部发现 (External Discovery)
Decentralized的方案会带来环局部分裂问题, 因为gossip-based protocol需要一定时间经行同步, 下面举例子, A, B同时加入ring, 但是他们无法在短时间内知道对方的存在.
所以为了解决这个问题, 完全的Decentralized是不可行的, 所以任命centralized seed的角色, all nodes eventually reconcile their membership with a seed.
The mechanism described above could temporarily result in a logically partitioned Dynamo ring. For example, the administrator could contact node A to join A to the ring, then contact node B to join B to the ring. In this scenario, nodes A and B would each consider itself a member of the ring, yet neither would be immediately aware of the other. To prevent logical partitions, some Dynamo nodes play the role of seeds. Seeds are nodes that are discovered via an external mechanism and are known to all nodes. Because all nodes eventually reconcile their membership with a seed, logical partitions are highly unlikely. Seeds can be obtained either from static configuration or from a configuration service. Typically seeds are fully functional nodes in the Dynamo ring.
4.8.3故障检测
首先Dynamo的故障检测purely local notion, 只要B不响应A的message, A就可以认为B fail, 无论他是否响应其他节点.
节点间不会有主动专门的fail check通信, 都是client requests drive internode communication, 如果没有客户请求驱动, A不需要知道B是否fail
起初Dynamo的设计想使用decentralized failure detector 来维护一个globally consistent view of failure state. 但后来发现没有必要,因为显示的node的增加和删除会通知所有的nodes, 而node的临时fail可以简单的通过internode communication侦测到
Failure detection in Dynamo is used to avoid attempts to communicate with unreachable peers during get() and put() operations and when transferring partitions and hinted replicas.
For the purpose of avoiding failed attempts at communication, a purely local notion of failure detection is entirely sufficient: node A may consider node B failed if node B does not respond to node
A’s messages (even if B is responsive to node C's messages).
In the presence of a steady rate of client requests generating internode communication in the Dynamo ring, a node A quickly discovers that a node B is unresponsive when B fails to respond to
a message; Node A then uses alternate nodes to service requests that map to B's partitions; A periodically retries B to check for the latter's recovery.
In the absence of client requests to drive traffic between two nodes, neither node really needs to know whether the other is reachable and responsive.
Decentralized failure detection protocols use a simple gossip-style protocol that enable each node in the system to learn about the arrival (or departure) of other nodes. For detailed information on
decentralized failure detectors and the parameters affecting their accuracy, the interested reader is referred to [8].
Early designs of Dynamo used a decentralized failure detector to maintain a globally consistent view of failure state. Later it was determined that the explicit node join and leave methods obviates the need for a global view of failure state. This is because nodes are notified of permanent node additions and removals by the explicit node join and leave methods and temporary node failures are detected by the individual nodes when they fail to communicate with others (while forwarding requests).
4.9添加/删除存储节点
当节点增加和删除时, 需要数据的迁移, 这个很容易理解.
上面说了, 对于node临时的fail, 或是node短时间内的忽join忽leave情况, 需要避免数据的迁移和摇摆的情况.
同时transfer前的confirmation, 也可用用于避免duplicated transfer
When a new node (say X) is added into the system, it gets assigned a number of tokens that are randomly scattered on the ring. For every key range that is assigned to node X, there may be
a number of nodes (less than or equal to N) that are currently in charge of handling keys that fall within its token range. Due to the allocation of key ranges to X, some existing nodes no longer have
to some of their keys and these nodes transfer those keys to X.
Let us consider a simple bootstrapping scenario where node X is added to the ring shown in Figure 2 between A and B. When X is added to the system, it is in charge of storing keys in the ranges
(F, G], (G, A] and (A, X]. As a consequence, nodes B, C and D no longer have to store the keys in these respective ranges.
Therefore, nodes B, C, and D will offer to and upon confirmation from X transfer the appropriate set of keys. When a node is removed from the system, the reallocation of keys happens in a reverse process.
Operational experience has shown that this approach distributes the load of key distribution uniformly across the storage nodes, which is important to meet the latency requirements and to ensure
fast bootstrapping. Finally, by adding a confirmation round between the source and the destination, it is made sure that the destination node does not receive any duplicate transfers for a given key range.


5. IMPLEMENTATION
In Dynamo, each storage node has three main software components: request coordination, membership and failure detection, and a local persistence engine. All these components
are implemented in Java.
Dynamo’s local persistence component allows for different storage engines to be plugged in.
Engines that are in use are Berkeley Database (BDB) Transactional Data Store2, BDB Java Edition, MySQL, and an in-memory buffer with persistent backing store.
The main reason for designing a pluggable persistence component is to choose the storage engine best suited for an application’s access patterns. For instance, BDB can handle objects typically in the order of tens of kilobytes whereas MySQL can handle objects of larger sizes. Applications choose Dynamo’s local persistence engine based on their object size distribution.
The majority of Dynamo’s production instances use BDB Transactional Data Store.
Dynamo的local persistence component提供一种通用的engine, 可用plugged in不同的存储引擎以应对不同的场景. Dynamo用的最多的还是Berkeley Database
The request coordination component is built on top of an eventdriven messaging substrate where the message processing pipeline is split into multiple stages similar to the SEDA architecture [24].
All communications are implemented using Java NIO channels.
The coordinator executes the read and write requests on behalf of clients by collecting data from one or more nodes (in the case of reads) or storing data at one or more nodes (for writes).
Each client request results in the creation of a state machine on the node that received the client request. The state machine contains all the logic for identifying the nodes responsible for a key, sending the requests, waiting for responses, potentially doing retries, processing the replies and packaging the response to the client.
Each state machine instance handles exactly one client request.
For instance, a read operation implements the following state machine:
(i) send read requests to the nodes, (ii) wait for minimum number of required responses, (iii) if too few replies were received within a given time bound, fail the request, (iv) otherwise gather all the data versions and determine the ones to be returned and (v) if versioning is enabled, perform syntactic reconciliation and generate an opaque write context that contains the vector clock that subsumes all the remaining versions. For the sake of brevity the failure handling and retry states are left out.
After the read response has been returned to the caller the state machine waits for a small period of time to receive any outstanding responses. If stale versions were returned in any of the responses, the coordinator updates those nodes with the latest version. This process is called read repair because it repairs replicas that have missed a recent update at an opportunistic time
and relieves the anti-entropy protocol from having to do it.
As noted earlier, write requests are coordinated by one of the top N nodes in the preference list. Although it is desirable always to have the first node among the top N to coordinate the writes
thereby serializing all writes at a single location, this approach has led to uneven load distribution resulting in SLA violations. This is because the request load is not uniformly distributed across
objects. To counter this, any of the top N nodes in the preference list is allowed to coordinate the writes.
In particular, since each write usually follows a read operation, the coordinator for a write is chosen to be the node that replied fastest to the previous read operation which is stored in the context information of the request. This optimization enables us to pick the node that has the data that was read by the preceding read operation thereby increasing the chances of getting “read-your-writes” consistency. It also reduces variability in the performance of the request handling which improves the performance at the 99.9 percentile.
对于coordination模块, 如果每次都以preference list中的第一个作为coordinator, 会导致其负担过重, 所以优化为top N nodes in the preference list中最先响应的那个作为coordinator.
至于后面关于读, 写操作coordinator的选择的描述, 我不理解...
6经验与教训
Dynamo是可以被应用于不同的场景, 通过调整基本配置, reconciliation logic策略, 和read/write quorum中R和W参数
Dynamo is used by several services with different configurations. These instances differ by their version reconciliation logic, and read/write quorum characteristics.
The following are the main patterns in which Dynamo is used:
• Business logic specific reconciliation: This is a popular use case for Dynamo. Each data object is replicated across multiple nodes. In case of divergent versions, the client application performs its own reconciliation logic. The shopping cart service discussed earlier is a prime example of this category. Its business logic reconciles objects by merging different versions of a customer’s shopping cart.
• Timestamp based reconciliation: This case differs from the previous one only in the reconciliation mechanism. In case of divergent versions, Dynamo performs simple timestamp based reconciliation logic of “last write wins”; i.e., the object with the largest physical timestamp value is chosen as the correct version. The service that maintains customer’s session information is a good example of a service that uses this mode.
• High performance read engine: While Dynamo is built to be an “always writeable” data store, a few services are tuning its quorum characteristics and using it as a high performance read engine. Typically, these services have a high read request rate and only a small number of updates. In this configuration, typically R is set to be 1 and W to be N. For these services, Dynamo provides the ability to partition and replicate their data across multiple nodes thereby offering incremental scalability. Some of these instances function as the authoritative persistence cache for data stored in more heavy weight backing stores. Services that maintain product catalog and promotional items fit in this category.
The main advantage of Dynamo is that its client applications can tune the values of N, R and W to achieve their desired levels of performance, availability and durability.
For instance, the value of N determines the durability of each object. A typical value of N used by Dynamo’s users is 3.
The values of W and R impact object availability, durability and consistency. For instance, if W is set to 1, then the system will never reject a write request as long as there is at least one node in
the system that can successfully process a write request. However, low values of W and R can increase the risk of inconsistency as write requests are deemed successful and returned to the clients
even if they are not processed by a majority of the replicas. This also introduces a vulnerability window for durability when a write request is successfully returned to the client even though it has
been persisted at only a small number of nodes.
Traditional wisdom holds that durability and availability go handinhand. However, this is not necessarily true here. For instance, the vulnerability window for durability can be decreased by
increasing W. This may increase the probability of rejecting requests (thereby decreasing availability) because more storage hosts need to be alive to process a write request.
The common (N,R,W) configuration used by several instances of Dynamo is (3,2,2). These values are chosen to meet the necessary levels of performance, durability, consistency, and availability
SLAs.
6.1平衡性能和耐久性
对于read/write quorum, 操作的performance由slowest of the R or W replicas来决定, 而Dynamo是搭建在大量的standard commodity hardware, hardware之间的配置可能有很大的差距, 系统性能确定于最差的机器.
我们可以在牺牲一些durability的前提下来提升性能.
在每个节点维护buffer cache, 写操作先写到buffer中, 然后定期将buffer flush到磁盘上. 而读操作可以先从buffer读, 如果读到就不需要访问磁盘.
显然问题在于, 当server crash时, 数据会丢失, 所以做法是coordinator choose one out of the N replicas to perform a “durable write”, 而其他的buffer写就ok了.
Since Dynamo is run on standard commodity hardware components that have far less I/O throughput than high-end enterprise servers, providing consistently high performance for read and write operations is a non-trivial task. The involvement of multiple storage nodes in read and write operations makes it even more challenging, since the performance of these operations is limited by the slowest of the R or W replicas.
Dynamo provides the ability to trade-off durability guarantees for performance. In the optimization each storage node maintains an object buffer in its main memory. Each write operation is stored in the buffer and gets periodically written to storage by a writer thread. In this scheme, read operations first check if the requested key is present in the buffer. If so, the object is read from the buffer instead of the storage engine.
In this scheme, a server crash can result in missing writes that were queued up in the buffer. To reduce the durability risk, the write operation is refined to have the coordinator choose one out of the N replicas to perform a “durable write”. Since the coordinator waits only for W responses(这里讨论的这种情况包含W-1个缓冲区写,1个持久化写), the performance of the write operation is not affected by the performance of the durable write operation performed by a single replica.
6.2确保均匀的负载分布
Dynamo uses consistent hashing to partition its key space across its replicas and to ensure uniform load distribution. A uniform key distribution can help us achieve uniform load distribution assuming the access distribution of keys is not highly skewed.
In particular, Dynamo’s design assumes that even where there is a significant skew in the access distribution there are enough keys in the popular end of the distribution so that the load of handling popular keys can be spread across the nodes uniformly through partitioning. This section discusses the load imbalance seen in Dynamo and the impact of different partitioning strategies on load distribution.
This section discusses how Dynamo’s partitioning scheme has evolved over time and its implications on load distribution.
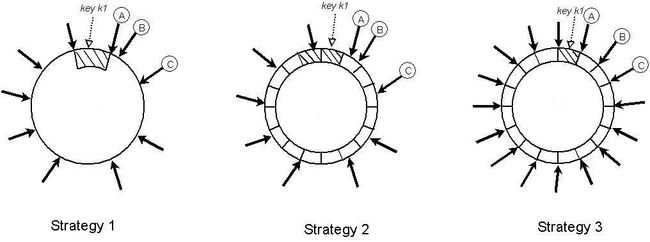
Strategy 1: T random tokens per node and partition by token value
This was the initial strategy deployed in production, each node is assigned T tokens. The tokens of all nodes are ordered according to their values in the hash space. Every two consecutive tokens define a range.
这个就是最开始的方案, 如图strategy1, 特点就是patition大小是由相邻的两个node间距决定的, 当node增删时, 会随时变化.
First, when a new node joins the system, it needs to “steal” its key ranges from other nodes. However, the nodes handing the key ranges off to the new node have to scan their local persistence store to retrieve the appropriate set of data items.
Note that performing such a scan operation on a production node is tricky as scans are highly resource intensive operations and they need to be executed in the background without affecting the
customer performance. This requires us to run the bootstrapping task at the lowest priority. However, this significantly slows the bootstrapping process and during busy shopping season, when the
nodes are handling millions of requests a day, the bootstrapping has taken almost a day to complete.
bootstrapping 效率问题, partition是动态变化的, 每次都需要实时scan their local persistence, 这是highly resource intensive operations, 这儿就有矛盾了, 如果要快速进行bootstrapping, 就会影响customer performance, 当然这是不可接受的, 那么bootstrapping就会很慢...
Second, when a node joins/leaves the system, the key ranges handled by many nodes change and the Merkle trees for the new ranges need to be recalculated, which is a non-trivial operation to perform on a production system.
重新计算Merkle trees的效率
Finally, there was no easy way to take a snapshot of the entire key space due to the randomness in key ranges, and this made the process of archival complicated. In this scheme, archiving the entire key space requires us to retrieve the keys from each node separately, which is highly inefficient.
archiving 的效率, 因为partition是随着node变化不断变化的
The fundamental issue with this strategy is that the schemes for data partitioning and data placement are intertwined.
本质的问题是节点的变化和数据的partition是紧耦合的, 所以节点一变化, 相关的数据分区就需要从新划分, 很麻烦, 因为上面说的这些, bootstrap, merkly tree, archive都是和数据分区紧密关联的
改进的方法, 显而易见就是, 解开耦合...所以就有了Stratege2和3
Strategy 2: T random tokens per node and equal sized partitions
In this strategy, the hash space is divided into Q equally sized partitions/ranges and each node is assigned T random tokens. Q is usually set such that Q >> N and Q >> S*T, where S is the
number of nodes in the system.
The primary advantages of this strategy are: (i) decoupling of partitioning and partition placement, and (ii) enabling the possibility of changing the placement scheme at runtime.
如图, 就是分区大小固定, 分配分区和node关系时, 只能以分区为单位, 所以图上A的range就是前面两块paritition
好处就是decoupling 分区本身和分区的位置, 因为分区本身不会因为节点的增减而改变, 所以节点增减时只需要以分区为单位进行transfer, 而不需要实时查询local persistence. 并且merkly tree和archive都可用以分区为单位进行而和分区的位置无关.
Strategy 3: Q/S tokens per node, equal-sized partitions
Similar to strategy 2, this strategy divides the hash space into Q equally sized partitions and the placement of partition is decoupled from the partitioning scheme. Moreover, each node is assigned Q/S tokens where S is the number of nodes in the system.
When a node leaves the system, its tokens are randomly distributed to the remaining nodes such that these properties are preserved.Similarly, when a node joins the system it "steals" tokens from nodes in the system in a way that preserves these properties.
策略2, 虽然固定了分区大小, 但是每个节点分配的节点数是随机的, 取决于节点在一致性hash ring上的间隔, 这样就容易导致不均衡, 可能有的节点分到很多分区, 而有的节点却很少
这个问题, 也应该可以采用虚拟节点的方式来解决
但这个策略更进一步, 干脆每个节点分配相同的分区数, 以保证绝对的均衡
虽然论文里面没有说, 这个策略应该基于两个假设, 各个节点的性能都差不多, 分区数>>节点数, 否则当增减节点时, 根本就无法保持等分的属性.
策略3达到最佳的负载平衡效率,而策略2最差负载均衡的效率。一个短暂的时期,在将Dynamo实例从策略1到策略3的迁移过程中,策略2曾作为一个临时配置。相对于策略1,策略3达到更好的效率并且在每个节点需要维持的信息的大小规模降低了三个数量级。虽然存储不是一个主要问题,但节点间周期地Gossip成员信息,因此最好是尽可能保持这些信息紧凑。除了这个,策略3还有下面的好处
Strategy 3 is advantageous and simpler to deploy for the following reasons:
(i) Faster bootstrapping/recovery:
Since partition ranges are fixed, they can be stored in separate files, meaning a partition can be relocated as a unit by simply transferring the file (avoiding random accesses needed to locate specific items). This simplifies the process of bootstrapping and recovery.
(ii) Ease of archival:
Periodical archiving of the dataset is a mandatory requirement for most of Amazon storage services.
Archiving the entire dataset stored by Dynamo is simpler in strategy 3 because the partition files can be archived separately.
By contrast, in Strategy 1, the tokens are chosen randomly and, archiving the data stored in Dynamo requires retrieving the keys from individual nodes separately and is usually inefficient and
slow.
The disadvantage of strategy 3 is that changing the node membership requires coordination in order to preserve the properties required of the assignment.
6.3 Divergent Versions: When and How Many?
this section discusses a good summary metric:
the number of divergent versions seen by the application in a live production environment.
Divergent versions of a data item arise in two scenarios.
The first is when the system is facing failure scenarios such as node failures, data center failures, and network partitions.
The second is when the system is handling a large number of concurrent writers to a single data item and multiple nodes end up coordinating the updates concurrently.
Experience shows that the increase in the number of divergent versions is contributed not by failures but due to the increase in number of concurrent writers. The increase in the number of
concurrent writes is usually triggered by busy robots (automated client programs) and rarely by humans. This issue is not discussed in detail due to the sensitive nature of the story.
divergent versions可以被看作是一种很好的metrics,
实验显示大量的divergent versions 往往是由于大量并发写导致的, 而不是由于fail导致的, 而这种大量的并发写往往来自robots
6.4 Client-driven or Server-driven Coordination
上面讨论过的问题, coordinate的到底是由Dynamo server还是由client来完成?
由client来完成无疑比较高效, 因为可以节省一跳, 但问题是client需要知道ring的布局, 当前的策略是client定期(10s)找任一dynamo node取同步membership 数据, 策略的有效性决定于how fresh, 因为client上的配置信息在更新间隔内, 很可能不是最新的. 而且client采用pull的方式定期从任一dynamo node上获取最新信息, 是考虑到扩展性, 因为如果要采用push方式, 当信息更新时主动推送到client, 这样实时性会好很多, 但是需要在server端保留所有client信息, 尤其是dynamo去中心化设计, 没有master, 会很麻烦.
Dynamo has a request coordination component that uses a state machine to handle incoming requests. Client requests are uniformly assigned to nodes in the ring by a load balancer.
Any Dynamo node can act as a coordinator for a read request. Write requests on the other hand will be coordinated by a node in the key’s current preference list.
This restriction is due to the fact that these preferred nodes have the added responsibility of creating a new version stamp that causally subsumes the version that has been updated by the write request. Note that if Dynamo’s versioning scheme is based on physical timestamps, any node can coordinate a write request.
读操作可以由任意一个node进行coordinate, 因为每个node都通过gossip协议知道整个ring的情况, 但是写操作, 必须写forward到preference list中的node, 然后由该node进行coordinate, 原因就是需要保证version之间的因果关系.
An alternative approach to request coordination is to move the state machine to the client nodes. In this scheme client applications use a library to perform request coordination locally.
A client periodically picks a random Dynamo node and downloads its current view of Dynamo membership state. Using this information the client can determine which set of nodes form the preference list for any given key. Read requests can be coordinated at the client node thereby avoiding the extra network hop that is incurred if the request were assigned to a random Dynamo node by the load balancer. Writes will either be forwarded to a node in the key’s preference list or can be coordinated locally if Dynamo is using timestamps based versioning.
An important advantage of the client-driven coordination approach is that a load balancer is no longer required to uniformly distribute client load. Fair load distribution is implicitly guaranteed by the near uniform assignment of keys to the storage nodes. Obviously, the efficiency of this scheme is dependent on how fresh the membership information is at the client.
Currently clients poll a random Dynamo node every 10 seconds for membership updates. A pull based approach was chosen over a push based one as the former scales better with large number of
clients and requires very little state to be maintained at servers regarding clients. However, in the worst case the client can be exposed to stale membership for duration of 10 seconds. In case,
if the client detects its membership table is stale (for instance, when some members are unreachable), it will immediately refresh its membership information.
6.5 Balancing background vs. foreground tasks
要考虑大量的后台操作(replica synchronization, data handoff )对正常put/get的效率的影响.
Each node performs different kinds of background tasks for replica synchronization and data handoff (either due to hinting or adding/removing nodes) in addition to its normal foreground put/get operations. In early production settings, these background tasks triggered the problem of resource contention and affected the performance of the regular put and get operations.
Hence, it became necessary to ensure that background tasks ran only when the regular critical operations are not affected significantly. To this end, the background tasks were integrated with an admission control mechanism. Each of the background tasks uses this controller to reserve runtime slices of the resource (e.g. database), shared across all background tasks. A feedback mechanism based on the monitored performance of the foreground tasks is employed to change the number of slices that are available to the background tasks.
6.6 Discussion
This section summarizes some of the experiences gained during the process of implementation and maintenance of Dynamo.
Many Amazon internal services have used Dynamo for the past two years and it has provided significant levels of availability to its applications. In particular, applications have received
successful responses (without timing out) for 99.9995% of its requests and no data loss event has occurred to date.
Moreover, the primary advantage of Dynamo is that it provides the necessary knobs using the three parameters of (N,R,W) to tune their instance based on their needs..
Unlike popular commercial data stores, Dynamo exposes data consistency and reconciliation logic issues to the developers. At the outset, one may expect the application logic to become more complex. However, historically, Amazon’s platform is built for high availability and many applications are designed to handle different failure modes and inconsistencies that may arise. Hence, porting such applications to use Dynamo was a relatively simple task. For new applications that want to use Dynamo, some analysis is required during the initial stages of the development to pick the right conflict resolution mechanisms that meet the business case appropriately.
Finally, Dynamo adopts a full membership model where each node is aware of the data hosted by its peers. To do this, each node actively gossips the full routing table with other nodes in the system. This model works well for a system that contains couple of hundreds of nodes. However, scaling such a design to run with tens of thousands of nodes is not trivial because the overhead in
maintaining the routing table increases with the system size. This limitation might be overcome by introducing hierarchical extensions to Dynamo. Also, note that this problem is actively addressed by O(1) DHT systems(e.g., [14]). 针对上千节点的gossips的效率问题