ggplot2笔记5:通过图层构建图像
ggplot2绘图基础系列:
1初识ggplot2、基本用法以及如何绘制几何对象
2图层的使用——基础、怎样加标签、注释
3工具箱——误差线、加权数、展示数据分布
4语法基础
Build a Plot Layer by Layer
5.1 简介
(略)
5.2 创建图表
(以汽车耗油量mpg数据集为例)
当我们使用 ggplot()创建图表时,最基本的代码是:
ggplot(mpg, aes(displ, hwy)) +
geom_point()
实际上这条代码包含了两步命令:
第一个是:
p <- ggplot(mpg, aes(displ, hwy))
它的意义只是创建了一个图层(将这个图层赋予变量p),横纵坐标是数据集 mpg中的两组变量名称 displ和 hwy,但是由于没有命令几何图形,数据无法形成映射,所以就是一块只有横纵坐标的白板↓↓↓↓↓↓

第二个是:
p + geom_point()
在p的基础上,添加函数 geom_point()(散点图),括号是空的就是各种参数都是默认值,于是有了确切的几何图形命令,白板上就有图了↓↓↓↓↓↓

在 geom_point()这个命令的背后,隐藏着一个叫做 layer()的命令,他的意思是创造一个图层,下面的代码里显示了藏在 layer()里面的各种参数:
p + layer(
mapping = NULL,
data = NULL,
geom = "point",
stat = "identity",
position = "identity"
)
这里面就包括了图层(layer)的五个重要组成部分:
mapping:映射,就是
aes()函数,通常省略,NULL就是指默认的ggplot()函数中的映射data:数据,覆盖默认数据集,通常省略,NULL就是默认取
ggplot()中的数据集geom:几何对象,包含很多美学参数,例如颜色等,在这里设置不会成为标度。
stat:统计变换,执行一些统计汇总,默认设置为
"identity"时保持不变。这个参数在直方图和平滑曲线图中应用较多。geom和stat设置一个即可。position:位置,调整遮盖情况
5.3 数据
You’ll learn about tidy data in Chap. 9, but for now, all you need to know is that a tidy data frame has variables in the columns and observations in the rows.
ggplot2的作用只是将数据框可视化。在使用之前应该提前整理你的数据框,使其整齐、易于操作(第九章)。
ggplot2的特点在上面的散点图基础上添加一条拟合的曲线:
library(ggplot2)
mpg
mod <- loess(hwy~displ, data = mpg)
grid <- data_frame(displ = seq(min(mpg$displ), max(mpg$displ), length = 50))
grid$hwy <- predict(mod, newdata = grid)
grid
std_resid <- resid(mod) / mod$s
outlier <- filter(mpg, abs(std_resid) > 2)
outlier
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
geom_line(data = grid, colour = "blue", size = 1.5) +
geom_text(data = outlier, aes(label = model))
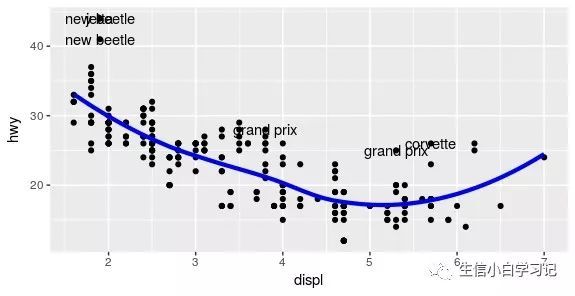
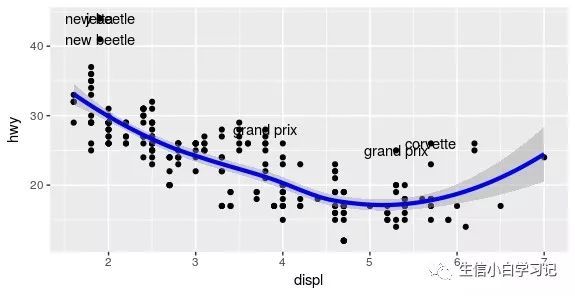
上述数据处理过程,简化之,可以使用函数 geom_smooth():添加平滑条件均直线,即上面的一大串数据处理过程:
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
geom_smooth(colour = "blue", size = 1.5) +
geom_text(data = outlier, aes(label = model))
5.4 美学映射(Aesthetic Mappings)
映射的函数就是 aes()。设置数据是怎样对应在到图表上的:
aes(x = displ, y = hwy, colour = class)
x= 和 y= 也可以省略,即放在第一个逗号前的变量默认是x轴,第二个逗号前的变量默认在y轴。
aes()中可以进行一些简单地运算,比如, aes(log(carat),log(price)),但不能出现 美元符号$(例如:diamonds$carat)。
1. 在图表或图层中添加图形属性
这次我们来试试将一个变量映射成一个图形属性——
在上面散点图的基础上,用不同颜色代表不同class(mpg数据集中的离散型变量:
ggplot(mpg, aes(displ, hwy, colour = class)) +
geom_point()
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class))
ggplot(mpg, aes(displ)) +
geom_point(aes(y = hwy, colour = class))
ggplot(mpg) +
geom_point(aes(displ, hwy, colour = class))
实际上,因为图层只有一层,所以以上四种代码意义是一样的,可以画出同样的图表↓↓↓↓↓

但是当图层不只一层之后,参数放在哪里,很重要
比如下面的例子:
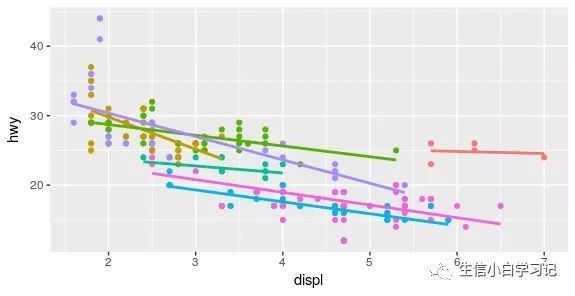
映射 aes(colour=class)放在 ggplot函数中:
ggplot(mpg, aes(displ, hwy, colour = class)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE) +
theme(legend.position = "none")
映射 aes(colour=class)只放在 geom_point图层中:
ggplot(mpg, aes(displ, hwy)) +
geom_point(aes(colour = class)) +
geom_smooth(method = "lm", se = FALSE) +
theme(legend.position = "none")

2. 设定和映射 (Setting vs. Mapping)
除了将图形属性和变量映射(mapping)起来,我们也可以在图层的参数里将其设定(setting)成一个单一值(例如,colour = "read")。
Setting和Mapping是不同的。
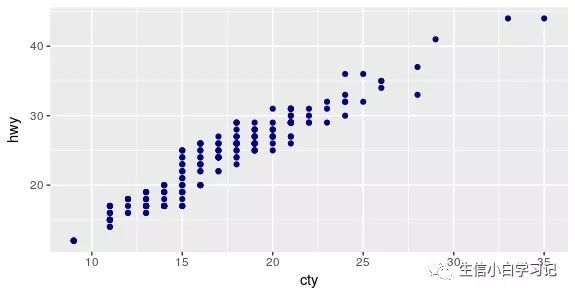
例如将上述例子中的图层颜色设置成统一的颜色("darkblue"):
colour="darkblue"直接填写在 point()里即可,不需要在aes()里面设定。
ggplot(mpg, aes(cty, hwy)) +
geom_point(colour = "darkblue")
否则,如果添加在 aes()里面,它的意义就变成了,将颜色映射到"darkblue"(普通的字符串)上,是用默认的颜色(桃红色)标度进行了转换,就图不达意了:
ggplot(mpg, aes(cty, hwy)) +
geom_point(aes(colour = "darkblue"))

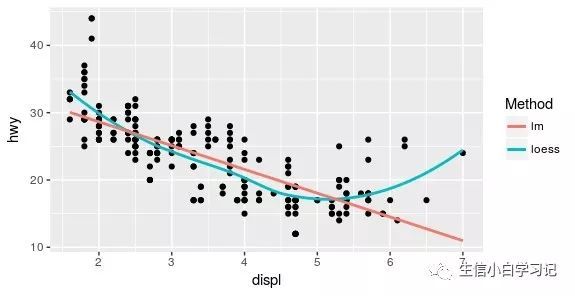
不过这种方法有时也能用到,比如,如果你想命名两个图层:
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
geom_smooth(aes(colour = "loess"), method = "loess", se = FALSE) +
geom_smooth(aes(colour = "lm"), method = "lm", se = FALSE) +
labs(colour = "Method")
5.5 几何图形函数小结
基础命令
geom_blank(): 空白,可以用来限制轴的范围geom_point(): 散点geom_path(): 路径geom_ribbon(): 色带图,连续的x值所对应的y值范围geom_segment(): 添加线段或者箭头geom_rect(): 二维矩形图geom_polyon(): 填充多边形geom_text(): 文本注释
一个变量
离散型变量
geom_bar():
连续型变量
geom_histogram(): 直方图geom_density(): 光滑密度曲线图geom_dotplot(): 点直方图geom_freqpoly(): 频率多边形图
两个变量
都是连续的
geom_point(): 散点图geom_quantile(): 添加分位数回归线geom_rug(): 边际地毯图geom_smooth(): 条件均值线geom_text(): 文本标签
展现分布图
geom_bin2d:二维热图geom_density2d:二维密度等高线图geom_hex():六边形表示的二维热图
至少一个连续型变量
geom_count:统计不同地点,点的数量geom_jitter:给点增加扰动,减轻图形重叠的问题
一个连续变量+一个离散变量
geom_bar(stat="identity"):条形图geom_boxplot(): 箱型图geom_violin():小提琴图
时间序列+连续变量
geom_area(): 面积图geom_line(): 按照x轴坐标大小顺序依次连接各个观测值geom_step(): 以阶梯的形式连接各个观测值
显示误差或置信区间
geom_crossbar(): 带水平中心线的盒子图geom_errorbar(): 误差线+条形图geom_linerange(): 一条代表一个区间的竖直线geom_pointrange(): 以一条中心带点的竖直线代表一个区间
地图
geom_map()
三个变量
geom_contour(): 等高线图geom_tile(): 瓦片图geom_raster(): 高效矩形瓦片图
5.6 统计变换(stat)
统计变换是指原始数据通过一定的计算或者汇总,以另一种方式呈现。
在不知不觉中,我们已经使用了一些统计变换,实际上它们藏在很多重要的geom命令里,比如:

除此之外,还有很多统计变换是没有包含在函数里的,不能通过 geom_函数使用:
stat_ecdf():经验累积分布函数stat_function():添加新函数stat_summary():对每个x值所对应的y值做汇总stat_summary2d(),stat_summary hex():对二维矩形封箱设定函数stat_qq():计算qqplot图的相关值stat_spoke():将角度和半径转换成xend和yendstat_unique():删除重复值
以下两种代码生成的图是一样的,使用示例:
ggplot(mpg, aes(trans, cty)) +
geom_point() +
stat_summary(geom = "point", fun.y = "mean", colour = "red", size = 4)
ggplot(mpg, aes(trans, cty)) +
geom_point() +
geom_point(stat = "summary", fun.y = "mean", colour = "red", size = 4)

生成变量(Generated Variables)
stat的后台操作是将一个你输入的数据集(依据某种命令)转换成一个新的数据集输出,因此stat会在原有数据的基础上增加一些新的变量。
例如,直方图 geom_histogram()中用到的 stat_bin()就会产生下面三个变量:
count:每个条形中观测值的个数density:每个条形中观测值的密度(占总数的百分比)x:中间值
有时候通过stat产生的变量可以替代原始数据集中的简单变量
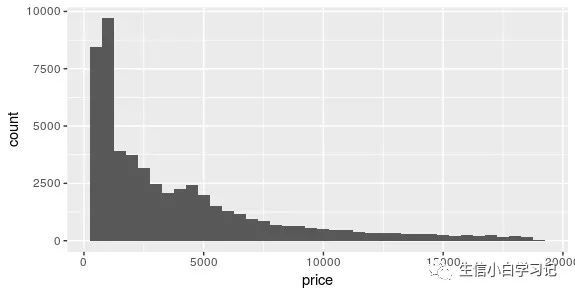
例如,钻石数据集(diamonds)中,我们只做price(连续)变量的频率直方图(横轴单位宽度设置为500):
ggplot(diamonds, aes(price)) +
geom_histogram(binwidth = 500)
x轴变量是price,而y周变量默认为count(计数):
实际上,如果加以设置, geom_histogram()函数内部是经过统计变换的,过程中生成 density这个变量。于是在函数 geom_histogram()中增加 aws(y=..density..)这个设定,就可以将y轴的映射改为stat中间生成的变量 density:
ggplot(diamonds, aes(price)) +
geom_histogram(aes(y = ..density..), binwidth = 500)

当你想观察多组的组间分布,而这些小组本身分布就不均匀的时候,这种方法很重要:
ggplot(diamonds, aes(price, colour = cut)) +
geom_freqpoly(binwidth = 500) +
theme(legend.position = "none")

要观察各个价位不同cut类型钻石的个数,但是有的cut类型的钻石总数就很少,有的总数就很多,这种情况下,当y轴为普通计数时,那些总数较少的类别的钻石数量就几乎看不到了
如果修改一下代码:
ggplot(diamonds, aes(price, colour = cut)) +
geom_freqpoly(aes(y = ..density..), binwidth = 500) +
theme(legend.position = "none")
如果y轴是百分比,这样的分布图就就更加清晰了↓↓↓↓↓↓

5.7 位置调整(Position Adjustments)
位置调整主要用于调整图层中微小元素的微调。
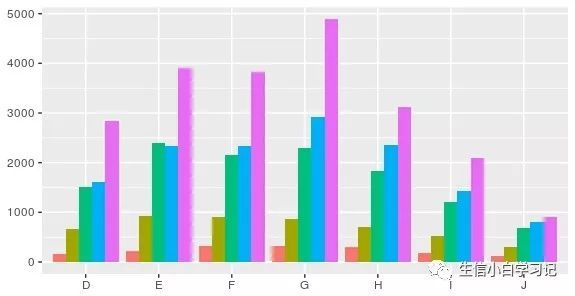
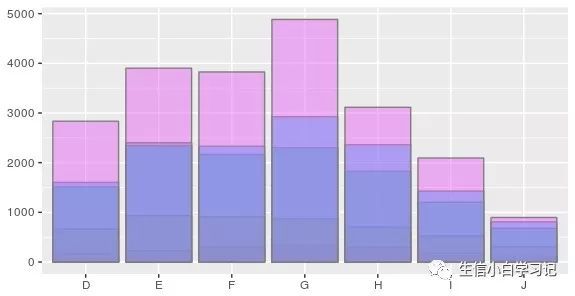
position_stack(): 将图形(条形、面积)元素堆叠起来position_fill(): 堆叠元素,并将其填充,高度标准化为1position_dodge(): 避免堆叠,并排放置
条形图中可以很容易看出不同类型的位置调整。下图展示了三种类型:堆叠(stack)、填充(fill)、并列(dodge)。
dplot <- ggplot(diamonds, aes(color, fill = cut)) +
xlab(NULL) + ylab(NULL) + theme(legend.position = "none")
dplot + geom_bar() #position stack is the default for bars, so `geom_bar()` is equivalent to `geom_bar(position = "stack")`
dplot + geom_bar(position = "fill")
dplot + geom_bar(position = "dodge")
我理解的是,
堆叠就是相同的x坐标,一个条形放到另一个上面
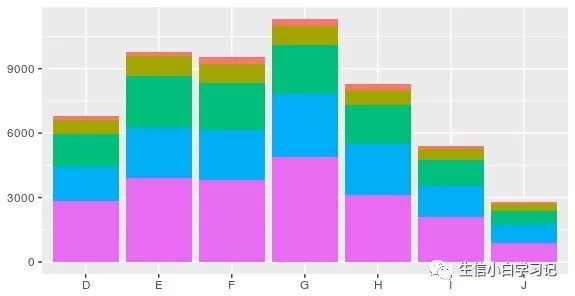
填充就是再堆叠的基础上高度标准化

并列更像是一种分类
还有一种叫做 position_identity(),意思是原地不动。
另外,在 geom_bar()函数中可以添加颜色和边框透明度设置
dplot <- ggplot(diamonds, aes(color, fill = cut)) +
xlab(NULL) + ylab(NULL) + theme(legend.position = "none")
dplot + geom_bar(position = "identity", alpha = 1 / 2, colour = "grey50")
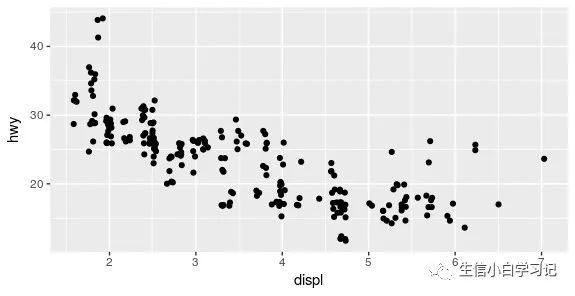
散点图中的位置调整主要有以下三个函数:
position_nudge(): 将每个点移动固定的位移position_jitter(): 添加随机扰动,减少遮盖position_jitterdodge(): 闪避组内的点
例如:
ggplot(mpg, aes(displ, hwy)) +
geom_point(position = "jitter")
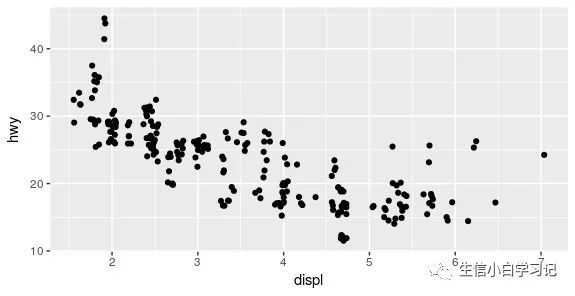
ggplot(mpg, aes(displ, hwy)) +
geom_point(position = position_jitter(width = 0.05, height = 0.5))

扰动点图,可以简写成以下代码:
ggplot(mpg, aes(displ, hwy)) +
geom_jitter(width = 0.05, height = 0.5)
参考资料:
Hadley Wickham(2016). ggplot2. Springer International Publishing. doi: 10.1007/978-3-319-24277-4
《R语言应用系列丛书·ggplot2:数据分析与图形艺术》
快快和我一起上车,请关注:生信小白学习记

猜你喜欢
10000+:肠道细菌 人体上的生命 宝宝与猫狗 梅毒狂想曲 提DNA发Nature 实验分析谁对结果影响大 Cell微生物专刊
系列教程:微生物组入门 Biostar 微生物组 宏基因组
专业技能:生信宝典 学术图表 高分文章 不可或缺的人
一文读懂:宏基因组 寄生虫益处 进化树
必备技能:提问 搜索 Endnote
文献阅读 热心肠 SemanticScholar Geenmedical
扩增子分析:图表解读 分析流程 统计绘图
16S功能预测 PICRUSt FAPROTAX Bugbase Tax4Fun
在线工具:16S预测培养基 生信绘图
科研经验:云笔记 云协作 公众号
编程模板 Shell R Perl
生物科普 生命大跃进 细胞暗战 人体奥秘
写在后面
为鼓励读者交流、快速解决科研困难,我们建立了“宏基因组”专业讨论群,目前己有国内外150+ PI,1300+ 一线科研人员加入。参与讨论,获得专业解答,欢迎分享此文至朋友圈,并扫码加主编好友带你入群,务必备注“姓名-单位-研究方向-职称/年级”。技术问题寻求帮助,首先阅读《如何优雅的提问》学习解决问题思路,仍末解决群内讨论,问题不私聊,帮助同行。

学习16S扩增子、宏基因组科研思路和分析实战,关注“宏基因组”


点击阅读原文,跳转最新文章目录阅读