基因组注释1. 重复序列repeatmasker, trf
本文转自“美格基因”,已获授权
基因组注释(Genome annotation)是利用生物信息学方法和工具,对基因组所有基因和其他结构进行高通量注释。
基因组注释主要包括:基因组组成成分分析(重复序列的识别、非编码基因预测、编码基因预测)和基因的功能注释,前者属于结构性注释,尤其是编码基因的预测十分重要。

重复序列
重复序列的分类
重复序列是指在基因组中出现的相同的或对称的片段,大量实验证明,重复序列包含大量的遗传信息,是基因调控网络的重要组成部分,在影响生命的进化、遗传、变异的同时对基因表达、转录调控等起着不可或缺的作用。
根据重复序列的结构特征和在基因组上位置可以为:
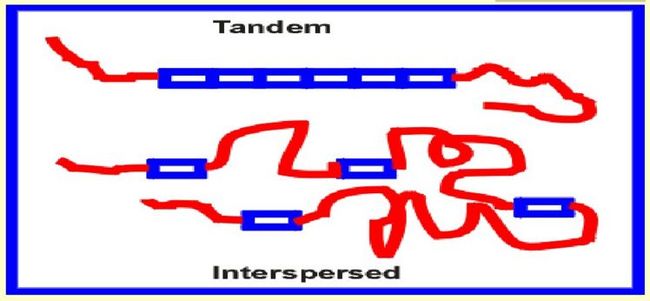
1. 串联重复序列(tandem repeats):
由1-500个碱基的重复单元构成,这种重复序列首尾依次相连,重复几十到几百万次,包括有微卫星(1-10 bp),小卫星(10-65 bp)序列等。
2. 散在重复序列(interspersed repeats):
是指比较均匀分布在基因组中重复序列,主要是转座子(transposable elements,TEs),包括:
(1) classI TEs(反转录转座子)
通过RNA介导的“copy and paste”机制进行转座,主要由LTR(long terminal repeat) 构成,LTR的部分序列可能具有编码功能;而nonLTR则包含2个子类:LINEs(long interspersed nuclear elements)和SINEs(short interspersed elements)其中前者可能具有编码功能,后者则没有。
(2) classII TEs(DNA 转座子)
通过DNA介导的“cut and paste”机制来转座,其中一个子类 MITEs(miniature inverted repeat transposable elements),是基于DNA的转座因子,但是通过“copy and paste”的机制来转座(Wicker et al., 2007)。
不同类型的重复序列是一个物种演化研究的重要标记,通过对不同物种之间的重复序列类型的对比分析可以研究不同物种基因组演化的趋异速度等事件及其发生的时间估计。
重复序列注释的算法
1. Homology-based
根据序列相似性的元件之间具有相似功能的原理,对已有的数据库中收集的重复序列模式进行同源搜索。
常用软件:RepeatMasker、GREEDIER
RepeatMasker:带有一个屏蔽DNA序列中重复序列的程序,通过将基因组与已知重复序列的数据库进行同源搜素,将识别出的基因组中的重复序列都屏蔽为N或X。该方法过于依赖于数据库的大小,只能识别出数据库已有的已知特定类型的重复序列,不能用于所有的重复序列识别,尤其是新物种中未知的重复序列的识别。详细教程见RepeatMasker:基因组重复序列注释。
GREEDIER(Li et al.,2008):该软件在其文章中表明该软件性能还不错,在repeats鉴定的敏感性上稍微比RepeatMasker高一点,但是repeats的鉴定率只有RepeatMasker的一半左右。
2. De novo,从头预测
直接从DNA序列中根据元件的结构特征或者功能特征等等来识别重复序列,不依赖于任何先前的研究基础、不依赖于数据库的完整性。
常用软件:RepeatScout、LTR-finder、TRF、Repeatmoderler、Piler、LTR_STRUC等。
TRF:最为常用,重复单元可以为1~500 bp,DNA查询序列大小可超过5 Mb。该方法的特点是能得到一些物种特异的重复序列,局限在于不能识别重复次数较少、变异较大的重复序列。预测得到的重复序列可以和Repbase等数据库进行比对得到类别的信息,然后根据LTR和串联重复序列的结构和分布特征,利用LTR-finder和TRF分别预测基因组中的LTR和串联重复序列,最终可以对所得到的重复序列进行分类和趋异度计算。
重复序列识别的难点
首先,第二代测序技术测基因组,有成本低、速度快等优点。但是由于目前产生的读长(reads)较短。由于基因组序列采用kmer算法进行组装,高度相似的重复序列可能会被压缩到一起,影响对后续的重复序列识别。
其次,某些高度重复的序列用现有的组装方法难以组装出来,成为未组装reads(unassembled reads)。有必要同时分析未组装reads以得到更为完整的重复序列分布图。之前,华大已开发了ReAS软件,专门用于识别未组装reads中的重复序列。但该软件目前只能处理传统测序技术(如sanger测序)生成的较长片段的reads,需要进一步改进方可用于分析第二代测序技术得到的 reads。同时,未组装的短片段reads重复度更高,识别其重复区域具有较大难度。
重复序列注释实例操作
1. RepeatMasker的使用
RepeatMasker是一款基于已知的转座子数据库寻找散在重复序列和低复杂度DNA序列软件,被广泛用于脊椎动物基因组分析。其官方地址为:http://www.repeatmasker.org/。这个软件的输出是对其中重复序列的碱基进行标注,默认的是改为N。目前56%的人类基因组重复序列的标注用的是这个工具。

(1)创建LIBRARY文件
(如果使用软件自带的LIBRARY,这步可省略)
$RepeatModelerHome/BuildDatabase ‐name species ‐engine ncbi species.genome.fasta
$RepeatModelerHome/RepeatModeler ‐engine ncbi ‐pa 10 ‐database species &> run.out &
# 结果生成了一个文件夹,名称为RM_[PID].[DATE],例如“RM_5098.MonMar141305172005”。该文件夹中的“consensi.fa.classified”即为library文件,用于RepeatMasker的输入。
(2) 使用RepeatMasker
$RepeatMaskerPath/RepeatMasker ‐lib consensi.fa.classified ‐pa 8 ‐e ncbi mySequence.fa
# 默认生成的结果文件在当前目录,如果需要改变输出路径,可设置参数 ‐dir
如果使用软件自带的LIBRARY,则很简单,
简单例子:
RepeatMasker ‐pa 10 lyc.genome.fasta
自定义参数的例子:
RepeatMasker ‐species human ‐s ‐no_is ‐xsmall ‐cutoff 255 ‐frag 20000 ‐pa 10 lyc.fa
想要了解更多参数信息,可执行:RepeatMasker ‐h
RepeatMasker专题教程,见:RepeatMasker:基因组重复序列注释
2. TRF的使用
TRF(Tandem repeats finder),其官方地址:http://tandem.bu.edu/trf/trf.unix.help.html

# 用法格式
trf File Match Mismatch Delta PM PI Minscore MaxPeriod [options]
# 参数说明
File = sequences input file
Match = matching weight
Mismatch = mismatching penalty
Delta = indel penalty
PM = match probability (whole number)
PI = indel probability (whole number)
Minscore = minimum alignment score to report
MaxPeriod = maximum period size to report
[options] = one or more of the following:
‐m masked sequence file
‐f flanking sequence
‐d data file
‐h suppress html output
‐r no redundancy elimination
‐l
# 示例
trf yoursequence.fasta 2 7 7 80 10 50 500 ‐f ‐d ‐m
更多说明见:http://tandem.bu.edu/trf/trf.unix.help.html
假基因的识别
假基因(pseudogene)指的是与已知功能的基因有较高的序列相似性,但由于某些变异而未能检出任何功能的基因序列。
耶鲁大学 Gerstein 实验室研究小组从果蝇、线虫、小鼠、人等很多物种基因组中系统地搜索识别假基因,并创建了专门的假基因数据库(http://www.pseudogene.org/),可供研究人员免费下载使用。
猜你喜欢
10000+:菌群分析 宝宝与猫狗 梅毒狂想曲 提DNA发Nature Cell专刊 肠道指挥大脑
系列教程:微生物组入门 Biostar 微生物组 宏基因组
专业技能:学术图表 高分文章 生信宝典 不可或缺的人
一文读懂:宏基因组 寄生虫益处 进化树
必备技能:提问 搜索 Endnote
文献阅读 热心肠 SemanticScholar Geenmedical
扩增子分析:图表解读 分析流程 统计绘图
16S功能预测 PICRUSt FAPROTAX Bugbase Tax4Fun
在线工具:16S预测培养基 生信绘图
科研经验:云笔记 云协作 公众号
编程模板: Shell R Perl
生物科普: 肠道细菌 人体上的生命 生命大跃进 细胞暗战 人体奥秘
写在后面
为鼓励读者交流、快速解决科研困难,我们建立了“宏基因组”专业讨论群,目前己有国内外2400+ 一线科研人员加入。参与讨论,获得专业解答,欢迎分享此文至朋友圈,并扫码加主编好友带你入群,务必备注“姓名-单位-研究方向-职称/年级”。技术问题寻求帮助,首先阅读《如何优雅的提问》学习解决问题思路,仍末解决群内讨论,问题不私聊,帮助同行。

学习16S扩增子、宏基因组科研思路和分析实战,关注“宏基因组”
 点击阅读原文,跳转最新文章目录阅读
点击阅读原文,跳转最新文章目录阅读