词云 pythonB站弹幕爬取
第一次搞 瞎写一下
- 前期准备
- jieba安装
- wordcloud安装
- 弹幕获取
- 代码
- 删除 增加词
- 设置背景图片
- 实现代码
- 现存的问题
这个不是边搞边记录着写的,主要靠回忆?
这个适用于conda使用者哦,当然我就是随便写写,我也是第一次搞,主要写下自己遇到的问题。
前期准备
jieba安装
jieba我早就安装了,应该是直接cmd打开后 pip install jieba,大概是上课作业需要,当时用着也还成。啊当时也把beautifulsoup啥的都安装了,所以我写这个好像真的是没有什么普适性呢。
但是这次再使用的时候总会报那个找不到jieba的那个错,当时查了大概意思就是jieba安装的位置不对,我就简单粗暴的复制了一个jieba过去了,检验可行。(当然这是不对的
wordcloud安装
同样还是那个问题,这次直接复制过去就不可以了= =
在这之前有安装的问题的话,一个是注意版本,比如我的电脑是64位的,我下wordcloud时就下了64的,但是!我的python是32位的,啊这个搞了我很长时间,是要和python版本对应!
还有就是安装好了还是不可以使用,啊过程不说了,直接说结果:conda install wordcloud+版本。意思就是说在conda进行操作,不是直接pip。
弹幕获取
我查了半天都是说cid的获取。但是这个网页它一改再改,按照指示我也没看到。但是大体上还是很管用的。
看这里。(整篇文章都很棒~)按照指示然后在附近翻翻就可以看到oid三个字母了。
最新的格式:https://api.bilibili.com/x/v1/dm/list.so?oid=xx
代码
删除 增加词
增加的话,jieba.suggest_freq()的格式即可
删除目前我还没实现
设置背景图片
实现方法我搜了很多,但是大多不太可行。这个是我实现的,注意背景的白色必须是纯白色,不然不会出现效果,有需要建议抠图。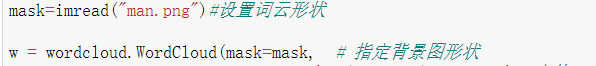
实现代码
import requests
from bs4 import BeautifulSoup
import re
from imageio import imread
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import jieba #中文分词
import wordcloud #绘制词云
url = 'https://api.bilibili.com/x/v1/dm/list.so?oid=189702747'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
response = requests.get(url,headers=headers)
html_doc = response.content.decode('utf-8')
#正则表达式的匹配模式
f=open('后浪弹幕.txt','w',encoding='utf-8')
res = re.compile('(.*?)' )
#根据模式提取网页数据
danmu = re.findall(res,html_doc)
for i in danmu:
f.write(i+" ")
f.close()
f = open('后浪弹幕.txt',encoding='utf-8')
txt = f.read()
jieba.suggest_freq('哔哩哔哩',True)
jieba.suggest_freq('奔涌吧',True)
jieba.suggest_freq('(゜-゜)つロ乾杯~',True)
#1写出不想显示的词组
stopwords = set(STOPWORDS)
stopwords.add("つロ")
stopwords.add("(゜-゜)つロ乾杯~")
stopwords.add('后浪')
txt_list = jieba.lcut(txt)
print(txt_list)
string = ' '.join((txt_list))
print(string)
mask=imread("man.png")#设置词云形状
w = wordcloud.WordCloud(mask=mask, # 指定背景图形状
font_path='C:/Windows/SIMLI.TTF',#字体
background_color='white',
width=1000,
height=700,
scale=15,
stopwords=stopwords,
contour_width=3,
contour_color='blue'
)
w.generate(txt)
plt.imshow(w)
plt.axis('off')
plt.show()
w.to_file('wordcloud.png')
效果:
现存的问题
1.哔哩哔哩干杯的那个颜表情总会被自动删除,我加了也不行。
2.删除还没实现。
3.想实现更多弹幕的获取,现在只能得到弹幕池的3000,可以手动调节弹幕日期但也不太现实。
或许有人想给我解答吗(