后台架构、分布式学习介绍
处于浪潮之巅,互联网的发展
- 大数据时代特性
海量 volume
多样 variety
实时 velocity
- 互联网需求
高并发
高可扩
高性能
-
系统架构图
举例:

涉及到技术非常广泛,甚至可以说涵盖了整个软件生态:
如操作系统底层调用,中间件 ,数据库存储,web server,UI界面等
分布式系统架构
何为分布式:
分布式是建立在网络之上的软件系统 ;分布式系统是一组通过网络进行通信,为了完成共同的任务而协调工作的计算机节点组成的系统。
目的:利用更多的机器,处理更多的数据
- 分布式性能对比
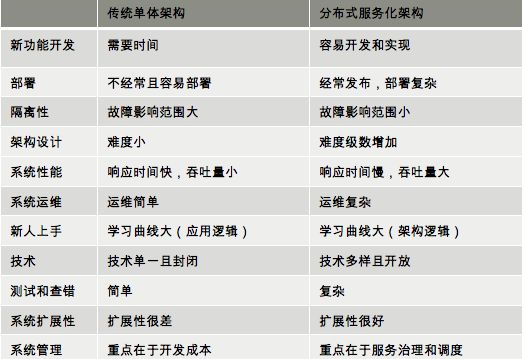
分布式系统特性,衡量标准
可扩展性:分布式系统的根本目标就是为了处理单个计算机无法处理的任务,当任务增加的时候,分布式系统的处理能力需要随之增加。简单来说,要比较方便的通过增加机器来应对数据量的增长,同时,当任务规模缩减的时候,可以撤掉一些多余的机器,达到动态伸缩的效果
可用性与可靠性:一般来说,分布式系统是需要长时间甚至7*24小时提供服务的。可用性是指系统在各种情况对外提供服务的能力,简单来说,可以通过不可用时间与正常服务时间的必知来衡量;而可靠性而是指计算结果正确、存储的数据不丢失。
高性能:不管是单机还是分布式系统,大家都非常关注性能。不同的系统对性能的衡量指标是不同的,最常见的:高并发,单位时间内处理的任务越多越好;低延迟:每个任务的平均时间越少越好。这个其实跟操作系统CPU的调度策略很像。
一致性:分布式系统为了提高可用性可靠性,一般会引入冗余(复制集)。那么如何保证这些节点上的状态一致,这就是分布式系统不得不面对的一致性问题。一致性有很多等级,一致性越强,对用户越友好,但会制约系统的可用性;一致性等级越低,用户就需要兼容数据不一致的情况,但系统的可用性、并发性很高很多。
分布式系统挑战
(1)异构的机器与网络
(2)普遍的节点故障
(3)不可靠的网络连接
-
分布式服务器图示
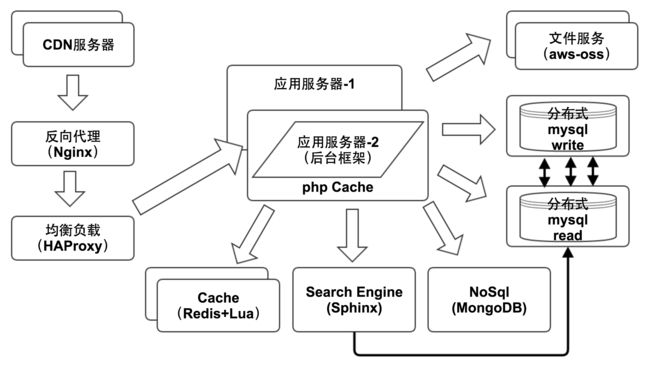
分布式实现(技术栈)
- 负载均衡
Nginx:
Nginx(发音同engine x):是异步框架的 Web服务器,也可以用作反向代理,负载平衡器 和 HTTP缓存。
高性能、高并发的web服务器;功能包括负载均衡、反向代理、静态内容缓存、访问控制;工作在应用层(1)Nginx可以部署在网络上使用FastCGI脚本、SCGI处理程序、WSGI应用服务器或Phusion乘客模块的动态HTTP内容,并可作为软件负载均衡器。
(2)Nginx使用异步事件驱动的方法来处理请求。Nginx的模块化事件驱动架构[12]可以在高负载下提供更可预测的性能。[13]
(3)Nginx是一款面向性能设计的HTTP服务器,相较于Apache、lighttpd具有占有内存少,稳定性高等优势
来自维基百科
LVS: Linux virtual server,基于集群技术和Linux操作系统实现一个高性能、高可用的服务器;工作在网络层
- webserver
Java:Tomcat,Apache,Jboss
Python:gunicorn、uwsgi、twisted、webpy、tornado
- service
SOA、微服务、spring boot,django
- 容器
docker:
Docker是一个开放源代码软件项目,让应用程序部署在软件货柜下的工作可以自动化进行,借此在Linux操作系统上,提供一个额外的软件抽象层,以及操作系统层虚拟化的自动管理机制
Docker利用Linux核心中的资源分离机制,例如cgroups,以及Linux核心名字空间(namespaces),来创建独立的容器(containers)。这可以在单一Linux实体下运作,避免引导一个虚拟机造成的额外负担[2]。Linux核心对名字空间的支持完全隔离了工作环境中应用程序的视野,包括行程树、网络、用户ID与挂载文件系统,而核心的cgroup提供资源隔离,包括CPU、存储器、block I/O与网络。从0.9版本起,Dockers在使用抽象虚拟是经由libvirt的LXC与systemd - nspawn提供界面的基础上,开始包括libcontainer库做为以自己的方式开始直接使用由Linux核心提供的虚拟化的设施,
kubernetes
- cache
memcache、redis等
- 协调中心
zookeeper、etcd等
zookeeper使用了Paxos协议Paxos是强一致性,高可用的去中心化分布式。zookeeper的使用场景非常广泛,之后细讲。
- RPC框架
grpc、dubbo、brpc
dubbo是阿里开源的Java语言开发的高性能RPC框架,在阿里系的诸多架构中,都使用了dubbo + spring boot
-
消息队列
kafka、rabbitMQ、rocketMQ、QSP
消息队列的应用场景:异步处理、应用解耦、流量削锋和消息通讯
- 实时数据平台
storm akka
- 离线数据平台
Hadoop , spark
- DB(数据库)
MySQL Oracle MongoDB HBase
- 搜索
elasticsearch solr
- 日志
rsyslog elk flume
- dbproxy
作为一个后台开发人员所应该掌握的基础知识:
基础
编程语言 C++
在具有C语言良好的编程功底下,可以进阶学习CPP语言
《C++ Primer》 CPP的百科全书,圣经级的书,C++语言的方方面面都有涉及

关于本书的学习,以下经验转自知乎
个人经验,C++ primer 第一次可以跳着看。关键是要尽快用起来,在使用中熟练,而不是在细节中迷失。以C++ Primer第五版为例,第一遍读的时候:
Part1也就是前七章,除了6.6,6.7节,都要通读。尤其是第三章初步介绍了vector和string,简直就是新手福音,搞定这两个容器就能写一些简单的程序。
Part2基本就是数据结构和算法,如果有基础读起来很轻松。9,11两章介绍的容器,以及12.1节的智能指针要通读。多用智能指针和容器,远离segment fault. 第10章里的泛型算法可以慢慢读,读完以后可以写出高逼格的函数式风格C++。12.2节讲了怎么用new和delete分配空间,题主作为新手,知道这种写法就行,写程序时尽量用容器代替原始数组,尤其是代码里最好不要有delete。Part3是块硬骨头,标题就是Tools for Class Authors. 作为一个"class user",有些部分第一次是可以略过的。13章很重要,要细读。初始化,复制,赋值,右值引用是C++里很微妙很重要的部分,别的语言对于这些概念很少有区分得这么细的。这一章不但要精读,还要完全掌握。14章的操作符重载第一次可以观其大略;14.9节第一次可以跳过。15章讲OOP,重要性不言而喻。如果之前一点概念都没有,学起来会觉得比较抽象。网上关于OOP有很多通俗有趣的文章,可以一起看看。16章讲泛型编程,第一次读16.1节,掌握最基本的函数模板和类模板就行了。Part4就更高档了,很多内容第一次就算啃下来,长久不用又忘了。第一次读推荐把18.2节读懂,命名空间简单易用效果好。别的内容可以观其大略,用时再看。17.1节的tuple是个有趣的东东,可以读一读。17.3节的正则表达式和17.4节的随机数也许有用,也可以读一读。如果需要读写文件,要读一下17.5.2节的raw I/O和17.5.3节的random I/O。最后给题主的建议是,写C++,要尽量避免C的写法。用static_cast而不是括号转换符;用vector而不是C里面的数组;用string而不是char *;用智能指针而不是原始指针。当然I/O是个例外,printf()还是比cout好用的;转换数字和字符串时sprintf()也比stringstream快
《深度探索C++对象模型》深度好书,了解CPP面向对象底层的精品之作
《STL源码剖析》C++大家侯捷著 差不多也是进阶的必读物品,书中内容涉及空间配置器,迭代器,序列式容器,关联式容器,算法等
学习此书的过程中,阅读STL源码自然是必须的:
侯捷有云:“学习过STL源码的人,用起来的虎虎生风之势绝非前两种人可比的!”
《Effective C++:改善程序与设计的55个具体做法》建议快速看一下。
算法与数据结构
需掌握的内容:
数据结构
队列
集合
链表、数组
字典、关联数组
栈
树
二叉树
完全二叉树
平衡二叉树
二叉查找树(BST)
红黑树
B,B+,B*树
LSM 树
BitSet
常用算法
排序、查找算法
选择排序
冒泡排序
插入排序
快速排序
归并排序
希尔排序
堆排序
计数排序
桶排序
基数排序
二分查找
高级算法
布隆过滤器
字符串比较
KMP 算法
深度优先、广度优先
贪心算法
回溯算法
剪枝算法
动态规划
朴素贝叶斯
推荐算法
最小生成树算法
最短路径算法