Kafka 幂等性(Exactly-Once处理数据丢失和数据重复)
Kafka 幂等性
在之前的旧版本中,Kafka只能支持两种语义:At most once和At least once。At most once保证消息不会朝服,但是可能会丢失。在实践中,很有有业务会选择这种方式。At least once保证消息不会丢失,但是可能会重复,业务在处理消息需要进行去重。
Kafka在 0.11.0.0 版本支持增加了对幂等的支持。幂等是针对生产者角度的特性。幂等可以保证上生产者发送的消息,不会丢失,而且不会重复。
Kafka为啥需要幂等性?
Producer在生产发送消息时,难免会重复发送消息。Producer进行retry时会产生重试机制,发生消息重复发送。而引入幂等性后,重复发送只会生成一条有效的消息。Kafka作为分布式消息系统,它的使用场景常见与分布式系统中,比如消息推送系统、业务平台系统(如物流平台、银行结算平台等)。以银行结算平台来说,业务方作为上游把数据上报到银行结算平台,如果一份数据被计算、处理多次,那么产生的影响会很严重。
影响Kafka幂等性的因素有哪些?
在使用Kafka时,需要确保Exactly-Once语义。分布式系统中,一些不可控因素有很多,比如网络、OOM、FullGC等。在Kafka Broker确认Ack时,出现网络异常、FullGC、OOM等问题时导致Ack超时,Producer会进行重复发送。可能出现的情况如下:
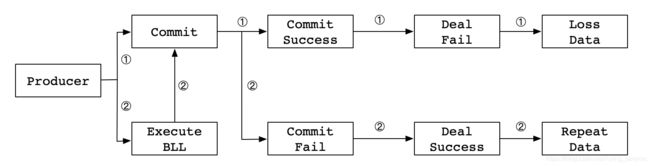
Kafka的幂等性是如何实现的?
Kafka为了实现幂等性,它在底层设计架构中引入了ProducerID和SequenceNumber。那这两个概念的用途是什么呢?
- ProducerID:在每个新的Producer初始化时,会被分配一个唯一的ProducerID,这个ProducerID对客户端使用者是不可见的。
- SequenceNumber:对于每个ProducerID,Producer发送数据的每个Topic和Partition都对应一个从0开始单调递增的SequenceNumber值。
幂等性引入之前的问题?
Kafka在引入幂等性之前,Producer向Broker发送消息,然后Broker将消息追加到消息流中后给Producer返回Ack信号值。实现流程如下:

上图的实现流程是一种理想状态下的消息发送情况,但是实际情况中,会出现各种不确定的因素,比如在Producer在发送给Broker的时候出现网络异常。比如以下这种异常情况的出现
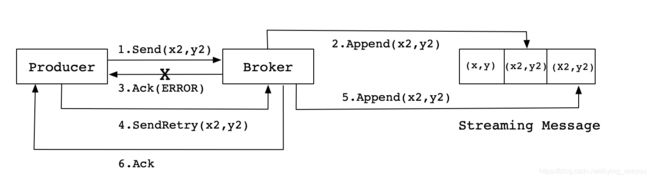
上图这种情况,当Producer第一次发送消息给Broker时,Broker将消息(x2,y2)追加到了消息流中,但是在返回Ack信号给Producer时失败了(比如网络异常) 。此时,Producer端触发重试机制,将消息(x2,y2)重新发送给Broker,Broker接收到消息后,再次将该消息追加到消息流中,然后成功返回Ack信号给Producer。这样下来,消息流中就被重复追加了两条相同的(x2,y2)的消息。
幂等性引入之后解决了什么问题?
面对这样的问题,Kafka引入了幂等性。那么幂等性是如何解决这类重复发送消息的问题的呢?下面我们可以先来看看流程图:

同样,这是一种理想状态下的发送流程。实际情况下,会有很多不确定的因素,比如Broker在发送Ack信号给Producer时出现网络异常,导致发送失败。异常情况如下图所示:

当Producer发送消息(x2,y2)给Broker时,Broker接收到消息并将其追加到消息流中。此时,Broker返回Ack信号给Producer时,发生异常导致Producer接收Ack信号失败。对于Producer来说,会触发重试机制,将消息(x2,y2)再次发送,但是,由于引入了幂等性,在每条消息中附带了PID(ProducerID)和SequenceNumber。相同的PID和SequenceNumber发送给Broker,而之前Broker缓存过之前发送的相同的消息,那么在消息流中的消息就只有一条(x2,y2),不会出现重复发送的情况。
幂等性示例
Producer 使用幂等性的示例非常简单,与正常情况下 Producer 使用相比变化不大,只需要把 Producer 的配置 enable.idempotence 设置为 true 即可,如下所示:
Properties props = new Properties();
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
props.put("acks", "all"); // 当 enable.idempotence 为 true,这里默认为 all
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer producer = new KafkaProducer(props);
producer.send(new ProducerRecord(topic, "test");
Prodcuer 幂等性对外保留的接口非常简单,其底层的实现对上层应用做了很好的封装,应用层并不需要去关心具体的实现细节,对用户非常友好。
幂等性要解决的问题
在看 Producer 是如何实现幂等性之前,首先先考虑一个问题: 幂等性是来解决什么问题的? 在 0.11.0 之前,Kafka 通过 Producer 端和 Server 端的相关配置可以做到 数据不丢 ,也就是 at least once,但是在一些情况下,可能会导致数据重复,比如:网络请求延迟等导致的重试操作,在发送请求重试时 Server 端并不知道这条请求是否已经处理(没有记录之前的状态信息),所以就会有可能导致数据请求的重复发送,这是 Kafka 自身的机制(异常时请求重试机制)导致的数据重复。
对于大多数应用而言,数据保证不丢是可以满足其需求的,但是对于一些其他的应用场景(比如支付数据等),它们是要求精确计数的,这时候如果上游数据有重复,下游应用只能在消费数据时进行相应的去重操作,应用在去重时,最常用的手段就是根据唯一 id 键做 check 去重。
在这种场景下,因为上游生产导致的数据重复问题,会导致所有有精确计数需求的下游应用都需要做这种复杂的、重复的去重处理。试想一下:如果在发送时,系统就能保证 exactly once,这对下游将是多么大的解脱。这就是幂等性要解决的问题,主要是解决数据重复的问题,正如前面所述,数据重复问题,通用的解决方案就是加唯一 id,然后根据 id 判断数据是否重复,Producer 的幂等性也是这样实现的,这一小节就让我们看下 Kafka 的 Producer 如何保证数据的 exactly once 的。
另外参考理解《kafka幂等性》