【飞桨】GAN:U-GAT-IT【2020 ICLR】论文研读
文章目录
- 论文简介
- 主要贡献
- 论文创新
- 论文方法
- 论文研读
- 名词解释
- 方法对比与优势
- 先前方法综述
- 新方法优势
- 网络结构与实现细节
- GENERATIVE ADVERSARIAL NETWORKS
- CycleGAN思路借鉴
- CAM思路
- Normalization思路
- 生成器GENERATOR
- 判别器DISCRIMINATOR
- 损失函数
- 网络结构
- 模型训练
- 数据集及数据处理
- 本文实验
- CAM分析CAM ANALYSIS
- ADALIN分析ADALIN ANALYSIS
- 消融研究ablation study
- 评估
- 定性评估QUALITATIVE EVALUATION
- 定量评价估QUANTITATIVE EVALUATION
- 结论与结果
- CONCLUSIONS
- 论文附录中全部效果图
- 资源文件
论文简介
本文所提出的模型属于无监督生成对抗网络模型,采用自适应归一化方式进行图像到图像的翻译任务
注:简介部分均来源于百度AI Studio 课程 百度顶会论文复现营 论文引读部分,论文的细节将在后面的论文研读部分给出
主要贡献
➢实现无监督图像到图像翻译任务,主要解决两个图像域间纹理和图像差异很大导致图像到图像翻译任务效果不好的问题
➢实现了相同网络结构和超参数同时需要保持图像中目标shape(马到斑马,horse2zebra)的图像翻译任务和需要改变图像shape(猫到狗,cat2dog)的图像任务




论文创新
➢提出新的归一化模块和新的归一化函数AdaLIN构成一种新的无监督图像到图像的转换方法
➢增加注意力机制Attention模块,增强生成器的生成能力,更好的区分源域和目标域。增强判别器的判别能力,更好的区分生成图像与原始图像
论文方法
ρ ⋅ I N + ( 1 − ρ ) ⋅ L N \rho \cdot IN + (1 - \rho ) \cdot LN ρ⋅IN+(1−ρ)⋅LN
➢LayerNorm更多的考虑输入特征通道之间的相关性,LN比IN风格转换更彻底,但是语义信息保存不足
➢InstanceNorm更多考虑单个特征通道的内容,IN比LN更好的保存原图像的语义信息,但是风格转换不彻底
➢论文中,通过上诉公式,自适应的调整 ρ \rho ρ的参数值来得到更优化的网络模型

| 方法 | 作用 |
|---|---|
| BatchNorm | batch方向做归一化,算NHW的均值,对小batchsize效果不好;BN主要缺点是对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布 |
| LayerNorm | channel方向做归一化,算CHW的均值,主要对RNN作用明显 |
| InstanceNorm | 一个channel内做归一化,算H*W的均值,用在风格化迁移;因为在图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立 |
| GroupNorm | 将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值;这样与batchsize无关,不受其约束 |
| SwitchableNorm | 是将BatchNorm、LayerNorm、InstanceNorm结合,赋予权重,让网络自己去学习归一化层应该使用什么方法 |
论文研读
名词解释
| 名词 | 释义 |
|---|---|
| baseline model | 要研究一个新的模型,在前人的模型基础上新增加了一些组件,其它工作也基本都是在这个模型上进行修改,那这个模型就叫做baseline model——基准模型,方便对比的一个标准 |
| ablation study | 消融研究通常是指删除模型或算法的一些"功能",并查看这如何影响性能。实际上ablation study就是为了研究模型中所提出的一些结构是否有效而设计的实验,类似于自然科学研究中的控制变量法 |
| LN(Layer Normalization) | 层归一化 |
| IN(Instance normalization) | 实例归一化 |
| attention map | 注意力图,与feature map类似,特征提取器提取的叫特征图,注意力模块获得的叫attention map |
| residual blocks | 残差块,残差网络中的一种结构 |
方法对比与优势
先前方法综述
2017年提出了条件生成对抗网络的图像到图像翻译的统一框架。高分辨率版本的pix2pix已经于2018年提出。通过从不成对数据集学习图像翻译的各种尝试。2017年CycleGAN首次提出循环一致性损失来实现一对一映射。UNIT假设了一个共享的潜在空间(shared-latent space)来处理无监督的图像翻译。然而,这种方法只有在两个域具有相似模式时才能表现良好。MUNIT通过将图像分解成域不变的内容代码和捕获特定域属性的风格代码,使其扩展到多对多映射成为可能。MUNIT综合分离的内容和风格以生成最终图像,其中图像质量通过使用自适应实例归一化(AdaIN)而得到改善。出于与MUNIT相同的目的,2018年提出DRIT将图像分解为内容和风格,从而使多对多映射成为可能。唯一的区别是,内容空间在两个使用权值共享和辅助分类器的内容判别器的域之间共享。然而,这些方法的性能仅限于包含源域和目标域之间对齐良好的图像的数据集。此外,2018年提出的AGGAN通过使用注意机制来区分前景和背景,提高了图像翻译的性能。然而,AGGAN中的注意模块不能帮助变换图像中对象的形状。尽管2018年提出的CartoonGAN在动画风格翻译方面表现出色,但它仅改变了图像中线条的颜色、色调和粗细。因此,它不适合图像中的形状变化。
新方法优势
先前方法的缺陷:
1.对于局部纹理(例如photo2vangogh[照片到梵高]和photo2portrait[照片到肖像])的样式转换任务是成功的,但是对于更大形状差异的图像转换任务(selfie2anime[自拍到动漫]和cat2dog[猫到狗])并不成功。这表明对于纹理差异较大的图像转换,效果欠佳。
2.先前大多数方法是用预设的网络或超参数进行训练的,除此之外,有的方法由于采用固定的网络架构和超参数,对于不同的数据集需要调整网络结构或超参数设置。
本文方法的优势:
1.提出一种新的无监督图像到图像的翻译方法。采用端到端的方式并结合一个 新的注意力模块和一个可学习的归一化函数,这个新归一化函数由不同归一化函数按比例组合而来。这样可以自适应的调整网络中各种归一化函数的比例。新提出的归一化函数AdaLIN(自适应层实例归一化)可以帮助注意力模块引导模型根据数据集已学习的方式灵活的控制形状和纹理的变化量。
2.注意力模块利用辅助分类器获得的attention map来关注区分源域和目标域的更重要的区域。我们的模型可以翻译不管应用在整体变化的图像(风格)还是巨大形状变化的图像都能获取很好的结果。
三点贡献:
1.提出新的图像到图像translation方法,基于新的注意力模块与新的归一化函数AdaLIN
2.注意模块通过基于辅助分类器获得的attention map来区分源域和目标域,从而帮助模型知道在哪里进行集中转换。
3.AdaLIN功能帮助我们的注意力导向模型灵活控制形状和纹理的变化量,而无需修改模型架构或超参数。
网络结构与实现细节
GENERATIVE ADVERSARIAL NETWORKS
生成式对抗网络(GAN, Generative Adversarial Networks)在各种图像生成方面取得了令人印象深刻的成果,图像修复、图像翻译、自动上色任务等。在训练过程中,生成器旨在生成真实图像以欺骗判别器,而判别器试图将生成的图像与真实图像区分开来。各种多阶段生成模型和更好的培训目标被提出来生成更逼真的图像。在本文中,新提出的模型在给定不成对的训练数据中,使用GAN来学习从源域到明显不同的目标域的转换。

关于GAN的基础知识参见生成时对抗网络:GAN 与 CGAN
CycleGAN思路借鉴
本文采用了 CycleGAN 网络结构的设计思路,因此可以注意到本文的网络结构拥有两个生成器与两个判别器
CycleGAN基础网络框架:使用一个对抗损失函数,学习映射 G G G: X → Y X \to Y X→Y以及其判别器 D Y {D_Y} DY,使得判别器 D Y {D_Y} DY难以区分生成的图片 G ( X ) G(X) G(X)与目标图片 Y Y Y。由于这样的单向映射收到巨大的限制,所以新添加一个相反的映射 F F F: Y → X Y \to X Y→X以及其判别器 D X {D_X} DX,使它们成对,同时加入循环一致性损失(Cycle Consistency Loss),以确保前向循环一致性损失 x → G ( x ) → F ( G ( x ) ) ≈ x x \to G(x) \to F(G(x))\approx x x→G(x)→F(G(x))≈x,反向循环一致性损失 y → F ( y ) → G ( F ( y ) ) ≈ y y \to F(y) \to G(F(y))\approx y y→F(y)→G(F(y))≈y。

本文目标是训练一个函数 G s → t {G_{s \to t}} Gs→t,该函数仅使用从每个域提取的不成对样本将图像从源域 X s {X_s} Xs映射到目标域 X t {X_t} Xt。本文框架由两个生成器 G s → t {G_{s \to t}} Gs→t, G t → s {G_{t \to s}} Gt→s和两个判别器 D s {D_s} Ds和 D t {D_t} Dt组成。本文将注意力模块集成到生成器和判别器中,判别器中的注意力模块引导生成器聚焦于对生成真实图像至关重要的区域。生成器中的注意力模块将注意力集中在另外不同的区域。【意思是判别器注意力模块已经引导生成器聚焦了一个域,那么生成器的注意力模块则聚焦其它的域】
由于论文中的两个生成器与两个判别器各自具有相同的结构,因此仅介绍生成器中从源域 Source 到目标域 Target 的 G s → t {G_{s \to t}} Gs→t以及目标域 Target 的判别器 D t {D_t} Dt

| 生成器 | 判别器 |
|---|---|
| 生成器由编码器(Encoder) E s {E_s} Es,辅助分类器(Auxiliary classifier) η s {\eta_s} ηs和解码器(Decoder) G t {G_t} Gt组成,它们之间的关系如上图所示 | 判别器由编码器(Encoder) E D t {E_{{D_t}}} EDt,辅助分类器(Auxiliary classifier) η D t {\eta_{{D_t}}} ηDt和分类器(Decoder) C D t {C_{{D_t}}} CDt组成,它们之间的关系如上图所示 |
CAM思路
2016年提出了使用全局均值池化的CAM(Class Activation Map)[类别激活图]。特定类别的CAM通过CNN显示可区分的图像区域,以确定该类别。在这项工作中,通过使用CAM方法区分两个域,我们的模型能够引起可区分图像区域的强烈变化。不但使用全局平均池化,而且还使用全局最大池化来使结果更好
Normalization思路
最近的 neural style transfer(神经统风格迁移)研究表明,CNN的特征统计,均值和方差可以作为图像风格的直接描述词。特别的,实例规范化(IN)通过直接规范化图像的特征统计,具有消除样式变化的效果,并且在样式传输中比批处理规范化(BN)或层规范化(LN)更为常用。然而,在对图像进行规范化处理时,最近的研究使用了自适应实例规范化(Adaptive Instance Normalization, AdaIN)、条件实例规范化(Conditional Instance Normalization, CIN)、批实例规范化(Batch-Instance Normalization, BIN)而不是单独的使用IN。本文提出了一个自适应层实例规范化(Layer-Instance Normalization, AdaLIN)函数,以自适应地选择IN与LN。通过AdaLIN,注意力引导模型可以灵活地控制形状和纹理的变化量
生成器GENERATOR
x ∈ { X s , X t } x \in \{ {X_s},{X_t}\} x∈{Xs,Xt}代表来自源域和目标域的样本。翻译模型 G s → t {G_{s \to t}} Gs→t由编码器 E s E_s Es,解码器 G t G_t Gt以及辅助分类器 η s \eta_s ηs。 η s ( x ) \eta_s(x) ηs(x)代表 x x x来自于 X s X_s Xs的概率。 E s k ( x ) E_s^k(x) Esk(x)是编码器第k个激活映射, E s k i j ( x ) E_s^{{k_{ij}}}(x) Eskij(x)是 E s k ( x ) E_s^k(x) Esk(x)在 ( i , j ) (i, j) (i,j)的值。训练辅助分类器来学习源域的第 k k k个特征映射的权重 w s k w_s^k wsk。通过使用全局平均池化与全局最大池化即 η s ( x ) = σ ( ∑ k w s k ∑ i j E s k i j ( x ) ) \eta_s(x)=\sigma (\sum\nolimits_k {w_s^k\sum\nolimits_{ij} {E_s^{{k_{ij}}}(x)} } ) ηs(x)=σ(∑kwsk∑ijEskij(x))。通过使用 w s k w_s^k wsk,我们可以计算一系列域特定注意的特征图 a s ( x ) = w s ∗ E s ( x ) = { w s k ∗ E s k ( x ) ∣ 1 ≤ k ≤ n } {a_s}(x) = {w_s}*{E_s}(x) = \{ w_s^k*E_s^k(x)\left| {1 \le k \le n\} } \right. as(x)=ws∗Es(x)={wsk∗Esk(x)∣1≤k≤n}。其中 n n n是编码特征的数目。然后翻译模型 G s → t = G t ( a s ( x ) ) {G_{s \to t}}=G_t{(a_s(x))} Gs→t=Gt(as(x))。我们用AdaLIN装备残差块,其参数 γ γ γ和 β β β由来自注意图的全连接层动态计算。
A d a L I N ( a , γ , β ) = γ ⋅ ( ρ ⋅ a ^ I + ( 1 − ρ ) ⋅ a ^ L ) + β , a ^ I = a − μ I σ I 2 + ε , a ^ L = a − μ L σ L 2 + ε , ρ ← c l i p [ 0 , 1 ] ( ρ − τ Δ ρ ) \begin{array}{l} {\rm{AdaLIN(}}a{\rm{,}}\gamma {\rm{,}}\beta ) = \gamma \cdot (\rho \cdot {{\hat a}_I} + (1 - \rho ) \cdot {{\hat a}_L}) + \beta ,\\ {{\hat a}_I} = \frac{{a - {\mu _I}}}{{\sqrt {\sigma _I^2 + \varepsilon } }},{{\hat a}_L} = \frac{{a - {\mu _L}}}{{\sqrt {\sigma _L^2 + \varepsilon } }},\\ \rho \leftarrow cli{p_{[0,1]}}(\rho - \tau \Delta \rho ) \end{array} AdaLIN(a,γ,β)=γ⋅(ρ⋅a^I+(1−ρ)⋅a^L)+β,a^I=σI2+εa−μI,a^L=σL2+εa−μL,ρ←clip[0,1](ρ−τΔρ)
μ I {{\mu _I}} μI, μ L {{\mu _L}} μL, σ I {{\sigma _I}} σI, σ I {{\sigma _I}} σI分别是通道级,层级的均值和标准差, γ γ γ和 β β β为全连通层生成的参数, τ \tau τ为学习速率, Δ ρ Δρ Δρ表示优化器确定的参数更新向量(如梯度)。 ρ ρ ρ的值被限制在 [ 0 , 1 ] [0,1] [0,1]的范围内,只需在参数更新步骤中设置界限即可。生成器调整该值,以便在实例规范化很重要的任务中 ρ ρ ρ的值接近 1 1 1,而在LN很重要的任务中 ρ ρ ρ的值接近 0 0 0。在解码器的残差块中, ρ ρ ρ的值初始化为 1 1 1,在解码器的上采样块中, ρ ρ ρ的值初始化为 0 0 0。
将内容特征转化成风格特征的最佳方法是应用Whitening
and Coloring Transform (WCT,白化和着色)方法,但由于协方差矩阵和逆矩阵的计算量巨大。尽管AdaIN相比于WCT要快的多,但是其效果并不如WCT好,因为AdaIN假设特征通道之间不相关。因此,传输的特征包含略微更多的内容模式。另一方面,LN并不假设通道之间的非相关。但有时它不能很好的保持原始域的内容结构,因为它只考虑了特征图的全局统计。
为了克服这个问题,我们提出的归一化技术AdaLIN结合了AdaIN和LN的优点,通过有选择地保持或改变内容信息,这有助于解决广泛的图像到图像的翻译问题。
判别器DISCRIMINATOR
使 x ∈ { X t , G s → t ( X s ) } x \in \{ {X_t},G_{s \to t}(X_s)\} x∈{Xt,Gs→t(Xs)}代表来自目标域和从源域翻译而来的样本。与其他翻译模型相似,判别器 D t D_t Dt是一个多尺度模型,由编码器 E D t E_{D_t} EDt,分类器 C D t C_{D_t} CDt和辅助分类器 η D t \eta_{D_t} ηDt组成。与其它翻译模型不同, η D t ( x ) {\eta_{D_t}}(x) ηDt(x)和 D t ( x ) D_t(x) Dt(x)都被训练来辨别 x x x是否来自 X t X_t Xt或 G s → t ( X s ) G_{s \to t}(Xs) Gs→t(Xs)。给定一个样本 x x x, D t ( x ) D_t(x) Dt(x)利用注意力特征图 a D t ( x ) = w D T ∗ E D t ( x ) a_{D_t}(x)= w_{D_T}*E_{D_t}(x) aDt(x)=wDT∗EDt(x),使用由 η D t ( x ) \eta_{D_t}(x) ηDt(x)训练的编码特征图 E D t ( x ) E_{D_t}(x) EDt(x)上的 w D t w_{D_t} wDt。然后,我们的鉴别器 D t ( x ) D_t(x) Dt(x)等于 C D t ( a D t ( x ) ) C_{D_t}(a_{D_t}(x)) CDt(aDt(x))。
损失函数
模型的全部优化目标包括四个损失函数。在这里,我们使用Least Square GAN 进行稳定训练,而不是使用 vanilla GAN
| 损失函数 | 作用 |
|---|---|
| Adversarial loss(对抗损失函数) | 采用对抗损失将翻译图像的分布与目标图像分布相匹配 L l s g a n s → t = ( E x ∼ X t [ ( D t ( x ) ) 2 ] + E x ∼ X s [ ( 1 − D t ( G s → t ( x ) ) ) 2 ] ) L_{lsgan}^{s \to t} = ({{\rm E}_{x \sim {X_t}}}[{({D_t}(x))^2}] + {{\rm E}_{x \sim {X_s}}}[{(1 - {D_t}({G_{s \to t}}(x)))^2}]) Llsgans→t=(Ex∼Xt[(Dt(x))2]+Ex∼Xs[(1−Dt(Gs→t(x)))2]) |
| Cycle loss(循环损失函数) | 为了缓解模式崩塌问题,对生成器使用了循环一致性约束。给定一个图像 x ∈ X s x∈Xs x∈Xs,在从 X s X_s Xs到 X t X_t Xt, X t X_t Xt到 X s X_s Xs一系列的翻译后,该图像应该被成功的翻译回原始域 L c y c l e s → t = E x ∼ X s [ ∥ x − G t → s ( G s → t ( x ) ) ) ∥ 1 ] L_{cycle}^{s \to t} = {{\rm E}_{x \sim {X_s}}}[\|x - {G_{t \to s}}({G_{s \to t}}(x)))\|_1] Lcycles→t=Ex∼Xs[∥x−Gt→s(Gs→t(x)))∥1] |
| Identity loss(身份损失函数) | 为了确保输入图像与输出图像的颜色分布相似,对生成器应用了身份一致性约束。给定一个图像 x ∈ X t x∈X_t x∈Xt,在使用 G s → t G_{s→t} Gs→t翻译之后,图像不应该改变 L i d e n t i t y s → t = E x ∼ X t [ ∥ x − G s → t ( x ) ∥ 1 ] L_{identity}^{s \to t} = {{\rm E}_{x \sim {X_t}}}[\|x - {G_{s \to t}}(x)\|_1] Lidentitys→t=Ex∼Xt[∥x−Gs→t(x)∥1] |
| CAM loss(Class Activation Mapping,类激活映射损失) | 通过利用来自辅助分类器 η η η和 η D t η_{D_t} ηDt的信息,给定图像 x ∈ X s , X t x∈{ X_s,X_t} x∈Xs,Xt。 G s → t G_{s→t} Gs→t和 D t D_t Dt了解他们需要改进的地方,或者在当前状态下两个领域之间最大的区别是什么 L c a m s → t = − ( E x ∼ X s [ log ( η s ( x ) ) ] + E x ∼ X t [ log ( 1 − η s ( x ) ) ] L c a m D t = E x ∼ X t [ ( η D t ( x ) ) 2 ] + E x ∼ X s [ ( 1 − η D t ( G s → t ( x ) ) 2 ] \begin{array}{l}L_{cam}^{s \to t} = - ({{\rm E}_{x \sim {X_s}}}[\log ({\eta _s}(x))] + {{\rm E}_{x \sim {X_t}}}[\log (1 - {\eta _s}(x))]\\L_{cam}^{{D_t}} = {{\rm E}_{x \sim {X_t}}}[{({\eta _{{D_t}}}(x))^2}] + {{\rm E}_{x \sim {X_s}}}[(1 - {\eta _{{D_t}}}{({G_{s \to t}}(x))^2}]\end{array} Lcams→t=−(Ex∼Xs[log(ηs(x))]+Ex∼Xt[log(1−ηs(x))]LcamDt=Ex∼Xt[(ηDt(x))2]+Ex∼Xs[(1−ηDt(Gs→t(x))2] |
最后,联合训练编码器、解码器、判别器和辅助分类器以优化最终目标函数
min G s → t , G t → s , η s , η t max D s , D t , η D s , η D t λ 1 L l s g a n + λ 2 L c y c l e + λ 3 L i d e n t i t y + λ 4 L c a m \mathop {\min }\limits_{{G_{s \to t}},{G_{t \to s}},{\eta _s},{\eta _t}} \mathop {\max }\limits_{{D_s},{D_t},{\eta _{{D_s}}},{\eta _{{D_t}}}} {\lambda _1}{L_{lsgan}} + {\lambda _2}{L_{cycle}} + {\lambda _3}{L_{identity}} + {\lambda _4}{L_{cam}} Gs→t,Gt→s,ηs,ηtminDs,Dt,ηDs,ηDtmaxλ1Llsgan+λ2Lcycle+λ3Lidentity+λ4Lcam
其中 λ 1 = 1 , λ 1 = 1 , λ 2 = 10 , λ 3 = 10 , λ 4 = 1000 \lambda_1=1, \lambda_1=1,\lambda_2=10,\lambda_3=10,\lambda_4=1000 λ1=1,λ1=1,λ2=10,λ3=10,λ4=1000 L l s g a n = L l s g a n s → t + L l s g a n t → s , L c y c l e = L c y c l e s → t + L c y c l e t → s , L i d e n t i t y = L i d e n t i t y s → t + L i d e n t i t y t → s , L c a m = L c a m s → t + L c a m t → s {L_{lsgan}}={L_{lsgan}^{s \to t}}+{L_{lsgan}^{t \to s}},{L_{cycle}}={L_{cycle}^{s \to t}}+{L_{cycle}^{t \to s}},{L_{identity}}={L_{identity}^{s \to t}}+{L_{identity}^{t \to s}},{L_{cam}}={L_{cam}^{s \to t}}+{L_{cam}^{t \to s}} Llsgan=Llsgans→t+Llsgant→s,Lcycle=Lcycles→t+Lcyclet→s,Lidentity=Lidentitys→t+Lidentityt→s,Lcam=Lcams→t+Lcamt→s
网络结构
U-GAT-IT 的网络架构如下表所示。该生成器的编码器由2个下采样步长的卷积层和4个残差块组成。生成器的解码器由四个残差块和两个步长为1的上采样卷积层组成。注意,我们分别为编码器和解码器使用实例规范化(LN)。一般来说,LN在分类问题上的表现并不比批次标准化(BN)好。由于辅助分类器是从生成器中的编码器连接而来的,为了提高辅助分类器的精度,我们使用实例规范化(LN, 最小批大小为1的批规范化,batch normalization)而不是AdaLIN。光谱归一化(Spectral normalization)用于鉴别器。对于判别器网络我们采用了两种不同比例的PatchGAN,它将局部(70 x 70)和全局(286 x 286)图像补丁进行真假分类。对于激活函数,我们在发生器中使用ReLU,在判别器中使用斜率为0.2的leaky-ReLU

The detail of generator architecture.

The detail of local discriminator.

The detail of global discriminator.
模型训练
所有模型均使用Adam优化器进行训练,β1=0.5,β2=0.999。对于数据增强,我们以0.5的概率水平翻转图像,将其调整为286×286,然后随机裁剪为256×256。所有实验的batch size都设置为1。以0.0001的固定学习率训练所有模型,直到500000次迭代,然后使用线性衰减学习率训练到1000000次迭代。我们还使用了0.0001的weight decay。权重从零中心正态分布初始化,标准偏差为0.02
数据集及数据处理
我们用五个不成对的图像数据集评估了每种方法的性能,包括四个有代表性的图像翻译数据集和一个新创建的由真实照片和动画作品组成的数据集,即selfie2anime。所有图像都被调整到256 x 256进行训练
| 数据集 | 处理 |
|---|---|
| selfie2anime | selfie(自拍)数据集包含46836张自拍图像,用36种不同的属性进行注释。我们只使用女性照片作为训练数据和测试数据。训练数据集的大小为3400,测试数据集的大小为100,图像大小为256×256。对于anime(动画)数据集,我们首先从anime-Planet1中检索到69926幅动画角色图像。在这些图像中,使用动画面部检测器2来提取27023个人脸图像。在只选择女性角色图像和手动去除单色图像后,我们采集了两组女性动漫人脸图像数据集,其大小分别为3400和100作为训练和测试数据,与自拍数据集的数量相同。最后,通过应用基于CNN的图像超分辨率算法,所有动画人脸图像的大小都被调整为256×256 |
| horse2zebra and photo2vangogh | 这些数据集曾被用于Cycle GAN。每类训练数据集数量如下:1067(马)、1334(斑马)、6287(照片)、400(梵高)。测试数据集包括120(马)、140(斑马)、751(照片)和400(梵高)。请注意,梵高类的训练数据和测试数据是相同的。 训练:1,067 (horse), 1,334 (zebra), 6,287 (photo), 400 (vangogh). 测试:120 (horse), 140 (zebra), 751 (photo), 400 (vangogh). |
| cat2dog and photo2portrait | 这些数据集曾被用于DRIT。每类数据集的数量如下: 871 (cat), 1,364 (zebra), 6,452 (photo), and 1,811 (vangogh).我们分别随机选择120幅(马)、140幅(斑马)、751幅(照片)和400幅(梵高)图像作为测试数据。 |
本文实验
此篇论文做了非常丰富的实验,使用了多个数据集,并自定义了部分数据集进行测试。对比了多个方法的效果,并且进行了 ablation 实验以及 CAM 分析等。
➢其所对比的模型包含 CycleGAN、UNIT、MUNIT、DRIT、AGGAN 以及 CartoonGAN。这些所有的 baseline 方法均采用作者的源码实现
➢其使用的数据集包括selfie2anime、horse2zebra、cat2dog、photo2portrait、photo2vangogh
CAM分析CAM ANALYSIS
本文进行了一项 ablation study,以确认在发生器和判别器中使用注意模块的益处。如图下图(b)所示,注意力特征图有助于生成器将注意力集中在与目标域更有区别的源图像区域,例如眼睛和嘴巴。与此同时,我们可以看到判别器集中注意力的区域,通过可视化辨别器的局部和全局注意力图分别确定目标图像是真实的还是假的,如图(c)和(d)所示
Visualization of the attention maps and their effects shown in the ablation experiments: (a) Source images, (b) Attention map of the generator, (c-d) Local and global attention maps of the discriminator, respectively. (e) Our results with CAM, (f) Results without CAM.
生成器可以通过这些 attention map 微调判别器关注的区域。注意到本文结合了来自具有不同感受野大小的两个判别器的全局和局部 attention map 。这些 map 可以帮助生成器捕捉全局结构(例如,面部区域和眼睛附近)以及局部区域。有了这些信息,一些地区的翻译就更加小心了。图中(e)所示注意力模块的实验结果验证了在图像翻译任务中利用注意力特征映射的有利效果。另一方面,图中(f)未使用注意力模块,可以看到眼睛明显错位了。或者根本不能完成翻译结果
ADALIN分析ADALIN ANALYSIS
如前面网络结构所述,本文仅将AdaLIN应用于生成器中的解码器。解码器中残差块的作用是嵌入特征,解码器中上采样卷积块的作用是从嵌入的特征生成目标域图像。如果gate参数ρ的学习值接近1,这意味着相应的层更多地依赖于IN而不是LN。同样,如果ρ的学习值更接近于0,这意味着相应的层更多地依赖于LN而不是IN。如下图(c)所示,在解码器中仅使用IN的情况下,源域的特征(例如,耳环和颧骨周围的阴影)由于在残差块中使用通道级的归一化特征统计而被很好地保留。然而,由于全局样式不能被上采样卷积块的IN捕获,所以到目标域样式的翻译有些不足。另一方面,如图(d)所示,如果在解码器中仅使用LN,则目标域样式可以在上采样卷积中利用层级归一化特征统计的优点达到充分转移。但是,在残差块中使用LN,源域图像的特征将被更少的保留。对两种极端情况的分析可知,在特征表示层中更多地依赖于IN而不是LN来保持源域的语义特征是有益的,而对于从特征嵌入生成图像的上采样层,情况正好相反。因此,在无监督的图像到图像的翻译任务中,根据源域和目标域分布来调整解码器中IN和LN的比例,我们所提出的AdaLIN是更优选的。此外,图中(e)、(f)分别是使用AdaIN和组归一化(GN)的结果,与这些相比,本文方法显示出更好的结果
Comparison of the results using each normalization function: (a) Source images, (b) Our results, (c) Results only using IN in decoder with CAM, (d) Results only using LN in decoder with CAM, (e) Results only using AdaIN in decoder with CAM, (f) Results only using GN in decoder with CAM.
消融研究ablation study
如下表所示,本文通过使用核初始距离(Kernel Inception Distance, KID)的ablation study展示了selfie2anime数据集中注意模块和AdaLIN的性能。本文中的模型实现了最低的KID值。即使注意力模块和AdaLIN分开使用,本文的模型比其它模型表现得更好。并且,当一起使用时,性能甚至更好
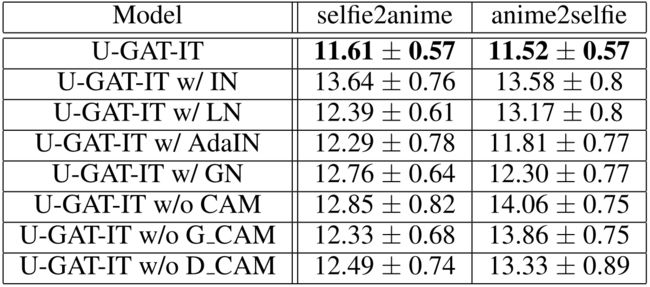
Kernel Inception Distance×100±std.×100 for ablation our model. Lower is better. There are some notations; GN: Group Normalization, G CAM: CAM of generator, D CAM: CAM of discriminator
评估
定性评估QUALITATIVE EVALUATION
对于定性评价,本文也做了perceptual study。通过向135名参与者展示来自不同方法的翻译结果,包括所提出的具有源图像的方法,并要求他们选择到目标域的最佳翻译图像。我们只告知参与者目标域名,即动画、狗和斑马。但是,对于肖像和梵高数据集提供了目标域的一些示例图像作为确保正确判断的最小信息。下表中显示,所提出的方法除了photo2vangogh外均显著获得了更高分数。但与其他方法相比,在人类感知研究中具更具有可比性。在下图中,我们展示了每种方法的图像转换结果,以进行性能比较

Preference score on translated images by user study.
Visual comparisons on the five datasets. From top to bottom: selfie2anime, horse2zebra, cat2dog, photo2portrait, and photo2vangogh. (a)Source images, (b)U-GAT-IT, (c)CycleGAN, (d)UNIT, (e)MUNIT, (f)DRIT, (g)AGGAN
通过利用注意力模块,U-GAT-IT 可以通过将更多的注意力集中在源域和目标域之间的不同区域来生成未失真的图像。注意到在 CycleGAN 的结果中,两只斑马头部周围的区域或狗的眼睛是扭曲的。此外,使用 U-GAT-IT 的翻译结果在视觉上优于其他方法,同时保留了源域的语义特征。值得注意的是,MUNIT 和 DRIT 的结果与源图像有很大不同,因为它们使用随机风格代码生成图像具以实现多样性。此外,最应强调的是,U-GAT-IT 是采用相同的网络架构和超参数对所有五个不同的数据集进行了应用,而其它算法是用预设的网络或超参数进行训练的。通过用户研究的结果,表明attention模块和AdaLIN的结合能够使模型更加灵活。
定量评价估QUANTITATIVE EVALUATION
对于定量评估,本文使用了最近提出的KID,它计算真实图像和生成图像特征表示之间的最大均方误差。特征表示从Inception网络中提取。与Frchet Inception Distance相比,KID具有无偏估计量,这使得它更加可靠,尤其是当测试图像少于初始特征的维数时。较低的KID表示真实图像和生成图像之间的视觉相似性越大。因此,如果翻译得好,KID在几个数据集中的值会很小。下表表示除了 photo2vangogh 和 photo2portrait 这样的风格迁移任务之外,所提出的方法均获得了最低的KID分数。但是本文所生成的结果与最低分并无太大区别。另外,与UNIT和MUNIT不同,本文的方法在源→目标,目标→源的翻译都是稳定的。它比最近的 attention-based 方法——AGGAN——表现得更低。与我们方法相比,AGGAN在形状处理上获得的效果很差,比如 dog2cat 和 anime2selfie,而本文的方法不存在这样的现象。注意力模块的重点是不区分背景和前景,而是区分两个域之间的差异。

Kernel Inception Distance×100±std.×100 for difference image translation mode. Lower is better.
如下图所示,CartoonGAN只是将图像的整体颜色改变为动画风格,但与自拍相比,眼睛这一动画的最大特点却没有任何改变。因此,CartoonGAN有更高的KID。
Visual comparisons of the selfie2anime with attention features maps. (a) Source images, (b) Attention map of the generator, (c-d) Local and global attention maps of the discriminators, (e) Our results, (f) CycleGAN (Zhu et al. (2017)), (g) UNIT (Liu et al. (2017)), (h) MUNIT (Huang et al. (2018)), (i) DRIT (Lee et al. (2018)), (j) AGGAN (Mejjati et al. (2018)), (k) CartoonGAN (Chen et al. (2018)).
结论与结果
CONCLUSIONS
本篇文章提出了无监督的图像到图像的翻译(U-GAT-IT),它带有注意模块和AdaLIN,在具有固定网络结构和超参数的各种数据集上能够产生更令人满意的视觉效果。对各种实验结果的详细分析都验证了这种假设,即由辅助分类器获得的注意图可以引导生成器更多地关注源域和目标域之间的不同区域。此外,本文还发现自适应层实例规范化(AdaLIN)对于翻译包含不同几何量和样式变化的各种数据集是必不可少的。通过实验,我们已经展示了所提出方法与现有基于GAN的最先进模型的对比,对于无监督的图像到图像翻译任务的优越性。
论文附录中全部效果图
除了本文给出的结果,下面列出论文附录中五个数据集的全部补充生成结果
Visual comparisons of the selfie2anime with attention features maps. (a) Source images, (b) Attention map of the generator, (c-d) Local and global attention maps of the discriminators, (e) Our results, (f) CycleGAN (Zhu et al. (2017)), (g) UNIT (Liu et al. (2017)), (h) MUNIT (Huang et al. (2018)), (i) DRIT (Lee et al. (2018)), (j) AGGAN (Mejjati et al. (2018)), (k) CartoonGAN (Chen et al. (2018)).
Visual comparisons of the anime2selfie with attention features maps. (a) Source images, (b) Attention map of the generator, (c-d) Local and global attention maps of the discriminators, (e) Our results, (f) CycleGAN (Zhu et al. (2017)), (g) UNIT (Liu et al. (2017)), (h) MUNIT (Huang et al. (2018)), (i) DRIT (Lee et al. (2018)), (j) AGGAN (Mejjati et al. (2018)).
Visual comparisons of the horse2zebra with attention features maps. (a) Source images, (b) Attention map of the generator, (c-d) Local and global attention maps of the discriminators, (e) Our results, (f) CycleGAN (Zhu et al. (2017)), (g) UNIT (Liu et al. (2017)), (h) MUNIT (Huang et al. (2018)), (i) DRIT (Lee et al. (2018)), (j) AGGAN (Mejjati et al. (2018)).
Visual comparisons of the zebra2horse with attention features maps. (a) Source images, (b) Attention map of the generator, (c-d) Local and global attention maps of the discriminators, (e) Our results, (f) CycleGAN (Zhu et al. (2017)), (g) UNIT (Liu et al. (2017)), (h) MUNIT (Huang et al. (2018)), (i) DRIT (Lee et al. (2018)), (j) AGGAN (Mejjati et al. (2018)).
Visual comparisons of the cat2dog with attention features maps. (a) Source images, (b) Attention map of the generation, (c-d) Local and global attention maps of the discriminators, (e) Our results, (f) CycleGAN (Zhu et al. (2017)), (g) UNIT (Liu et al. (2017)), (h) MUNIT (Huang et al. (2018)), (i) DRIT (Lee et al. (2018)), (j) AGGAN (Mejjati et al. (2018)).
Visual comparisons of the dog2cat with attention features maps. (a) Source images, (b) Attention map of the generation, (c-d) Local and global attention maps of the discriminators, (e) Our results, (f) CycleGAN (Zhu et al. (2017)), (g) UNIT (Liu et al. (2017)), (h) MUNIT (Huang et al. (2018)), (i) DRIT (Lee et al. (2018)), (j) AGGAN (Mejjati et al. (2018)).
Visual comparisons of the photo2vangogh with attention features maps. (a) Source images, (b) Attention map of the generation, (c-d) Local and global attention maps of the discriminators, respectively, (e) Our results, (f) CycleGAN (Zhu et al. (2017)), (g) UNIT (Liu et al. (2017)), (h) MUNIT (Huang et al. (2018)), (i) DRIT (Lee et al. (2018)), (j) AGGAN (Mejjati et al. (2018)).
Visual comparisons of the photo2portrait with attention features maps. (a) Source images, (b) Attention map of the generator, (c-d) Local and global attention maps of the discriminators, respectively, (e) Our results,(f) CycleGAN (Zhu et al. (2017)), (g) UNIT (Liu et al. (2017)), (h) MUNIT (Huang et al. (2018)), (i) DRIT (Lee et al. (2018)), (j) AGGAN (Mejjati et al. (2018)).
资源文件
论文下载地址U-GAT-IT Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation
Pytorch代码实现UGATIT-pytorch
TensorFlow代码实现UGATIT
PaddlePaddle代码实现[UGATIT-paddle]——待定