linux内存映射mmap原理分析和共享内存的两篇转载文章
内存映射,简而言之就是将用户空间的一段内存区域映射到内核空间,映射成功后,用户对这段内存区域的修改可以直接反映到内核空间,同样,内核空间对这段区域的修改也直接反映用户空间。那么对于内核空间<---->用户空间两者之间需要大量数据传输等操作的话效率是非常高的。
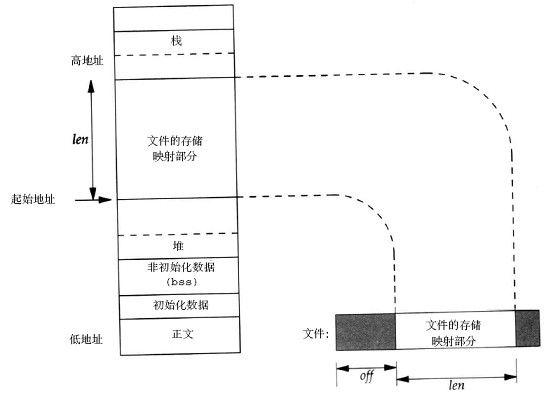
以下是一个把普遍文件映射到用户空间的内存区域的示意图。
图一:
二、基本函数
mmap函数是unix/linux下的系统调用,详细内容可参考《Unix Netword programming》卷二12.2节。
mmap系统调用并不是完全为了用于共享内存而设计的。它本身提供了不同于一般对普通文件的访问方式,进程可以像读写内存一样对普通文件的操作。而Posix或系统V的共享内存IPC则纯粹用于共享目的,当然mmap()实现共享内存也是其主要应用之一。
mmap系统调用使得进程之间通过映射同一个普通文件实现共享内存。普通文件被映射到进程地址空间后,进程可以像访问普通内存一样对文件进行访问,不必再调用read(),write()等操作。mmap并不分配空间, 只是将文件映射到调用进程的地址空间里(但是会占掉你的 virutal memory), 然后你就可以用memcpy等操作写文件, 而不用write()了.写完后,内存中的内容并不会立即更新到文件中,而是有一段时间的延迟,你可以调用msync()来显式同步一下, 这样你所写的内容就能立即保存到文件里了.这点应该和驱动相关。 不过通过mmap来写文件这种方式没办法增加文件的长度, 因为要映射的长度在调用mmap()的时候就决定了.如果想取消内存映射,可以调用munmap()来取消内存映射
[cpp] view plaincopy
mmap用于把文件映射到内存空间中,简单说mmap就是把一个文件的内容在内存里面做一个映像。映射成功后,用户对这段内存区域的修改可以直接反映到内核空间,同样,内核空间对这段区域的修改也直接反映用户空间。那么对于内核空间<---->用户空间两者之间需要大量数据传输等操作的话效率是非常高的。
原理
首先,“映射”这个词,就和数学课上说的“一一映射”是一个意思,就是建立一种一一对应关系,在这里主要是只 硬盘上文件 的位置与进程 逻辑地址空间 中一块大小相同的区域之间的一一对应,如图1中过程1所示。这种对应关系纯属是逻辑上的概念,物理上是不存在的,原因是进程的逻辑地址空间本身就是不存在的。在内存映射的过程中,并没有实际的数据拷贝,文件没有被载入内存,只是逻辑上被放入了内存,具体到代码,就是建立并初始化了相关的数据结构(struct address_space),这个过程有系统调用mmap()实现,所以建立内存映射的效率很高。
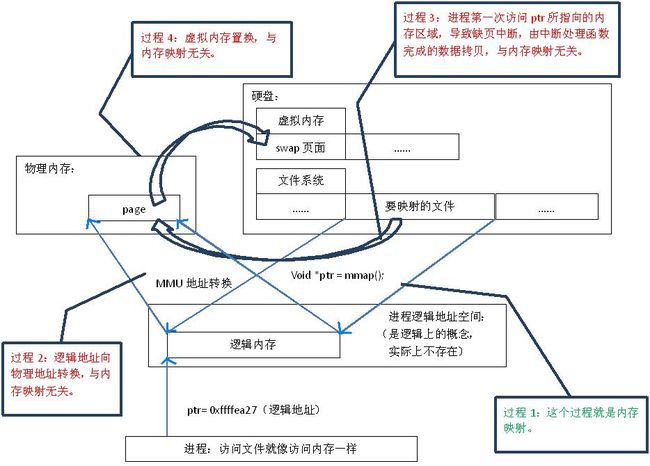
图1.内存映射原理
既然建立内存映射没有进行实际的数据拷贝,那么进程又怎么能最终直接通过内存操作访问到硬盘上的文件呢?那就要看内存映射之后的几个相关的过程了。
mmap()会返回一个指针ptr,它指向进程逻辑地址空间中的一个地址,这样以后,进程无需再调用read或write对文件进行读写,而只需要通过ptr就能够操作文件。但是ptr所指向的是一个逻辑地址,要操作其中的数据,必须通过MMU将逻辑地址转换成物理地址,如图1中过程2所示。这个过程与内存映射无关。
前面讲过,建立内存映射并没有实际拷贝数据,这时,MMU在地址映射表中是无法找到与ptr相对应的物理地址的,也就是MMU失败,将产生一个缺页中断,缺页中断的中断响应函数会在swap中寻找相对应的页面,如果找不到(也就是该文件从来没有被读入内存的情况),则会通过mmap()建立的映射关系,从硬盘上将文件读取到物理内存中,如图1中过程3所示。这个过程与内存映射无关。
如果在拷贝数据时,发现物理内存不够用,则会通过虚拟内存机制(swap)将暂时不用的物理页面交换到硬盘上,如图1中过程4所示。这个过程也与内存映射无关。
效率
从代码层面上看,从硬盘上将文件读入内存,都要经过文件系统进行数据拷贝,并且数据拷贝操作是由文件系统和硬件驱动实现的,理论上来说,拷贝数据的效率是一样的。但是通过内存映射的方法访问硬盘上的文件,效率要比read和write系统调用高,这是为什么呢?原因是read()是系统调用,其中进行了数据拷贝,它首先将文件内容从硬盘拷贝到内核空间的一个缓冲区,如图2中过程1,然后再将这些数据拷贝到用户空间,如图2中过程2,在这个过程中,实际上完成了 两次数据拷贝 ;而mmap()也是系统调用,如前所述,mmap()中没有进行数据拷贝,真正的数据拷贝是在缺页中断处理时进行的,由于mmap()将文件直接映射到用户空间,所以中断处理函数根据这个映射关系,直接将文件从硬盘拷贝到用户空间,只进行了 一次数据拷贝 。因此,内存映射的效率要比read/write效率高。
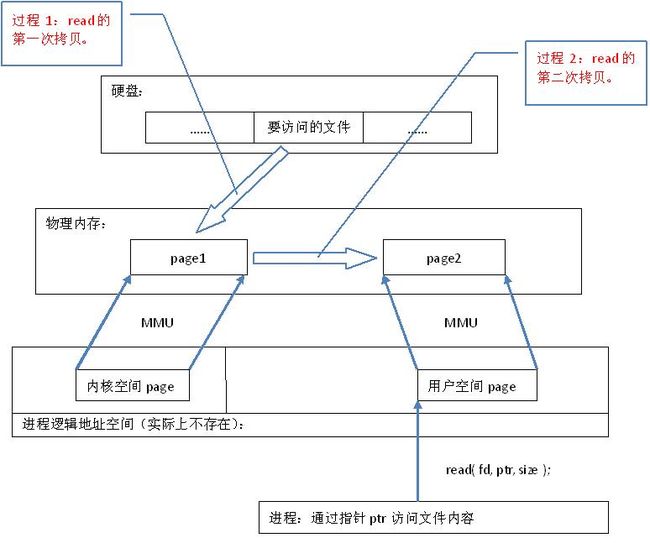
图2.read系统调用原理
下面这个程序,通过read和mmap两种方法分别对硬盘上一个名为“mmap_test”的文件进行操作,文件中存有10000个整数,程序两次使用不同的方法将它们读出,加1,再写回硬盘。通过对比可以看出,read消耗的时间将近是mmap的两到三倍。
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define MAX 10000
int main()
{
int i=0;
int count=0, fd=0;
struct timeval tv1, tv2;
int *array = (int *)malloc( sizeof(int)*MAX );
/*read*/
gettimeofday( &tv1, NULL );
fd = open( "mmap_test", O_RDWR );
if( sizeof(int)*MAX != read( fd, (void *)array, sizeof(int)*MAX ) )
{
printf( "Reading data failed.../n" );
return -1;
}
for( i=0; i ++array[ i ]; if( sizeof(int)*MAX != write( fd, (void *)array, sizeof(int)*MAX ) ) { printf( "Writing data failed.../n" ); return -1; } free( array ); close( fd ); gettimeofday( &tv2, NULL ); printf( "Time of read/write: %dms/n", tv2.tv_usec-tv1.tv_usec ); /*mmap*/ gettimeofday( &tv1, NULL ); fd = open( "mmap_test", O_RDWR ); array = mmap( NULL, sizeof(int)*MAX, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0 ); for( i=0; i ++array[ i ]; munmap( array, sizeof(int)*MAX ); msync( array, sizeof(int)*MAX, MS_SYNC ); free( array ); close( fd ); gettimeofday( &tv2, NULL ); printf( "Time of mmap: %dms/n", tv2.tv_usec-tv1.tv_usec ); return 0; } 输出结果: Time of read/write: 154ms Time of mmap: 68ms 以上内容转自鱼思故渊的专栏:linux内存映射mmap原理分析 ----------------------------------------------------------------------------------------------------------------------------------------------------------------- 以下内容为本人总结: mmap映射类似虚拟内存,也是使用了交换,把用于交换的物理地址拓展到了文件系统所在的物理空间,实现了只需复制一次(即从把文件系统中对应的一段物理空间的内容复制到了用户空间),而不用通过系统调用read命令去通过两次复制才把文件系统中的内容复制到内存中。普通的读写文件的原理,进程调用read或是write后会陷入内核,因为这两个函数都是系统调用,进入系统调用后,内核开始读写文件,假设内核在读取文件,内核首先把文件读入自己的内核空间,读完之后进程在内核回归用户态,内核把读入内核内存的数据再copy进入进程的用户态内存空间。实际上我们同一份文件内容相当于读了两次,先读入内核空间,再从内核空间读入用户空间。 而共享内存是建立在内存映射mmap上的。 页缺失(英语:Page fault,又名硬错误、硬中断、分页错误、寻页缺失、缺页中断、页故障等)指的是当软件试图访问已映射在虚拟地址空间中,但是目前并未被加载在物理内存中的一个分页时,由中央处理器的内存管理单元所发出的中断。 下面一片文章是转载的,关于共享内存的 ------------------------------------------------------------------------------------------------------------------------------------------------------------------------ mmap内存文件映射 一、传统文件访问 unix访问文件的传统方法使用open打开他们,如果有多个进程访问一个文件,则每一个进程在再记得地址空间都包含有该文件的副本,这不必要地浪费了存储空间。下面说明了两个进程同时读一个文件的同一页的情形,系统要将该页从磁盘读到高速缓冲区中,每个进程再执行一个内存期内的复制操作将数据从高速缓冲区读到自己的地址空间。 二、共享内存映射 现在考虑林一种处理方法:进程A和进程B都将该页映射到自己的地址空间,当进程A第一次访问该页中的数据时,它生成一个缺页终端,内核此时读入这一页到内存并更新页表使之指向它,以后,当进程B访问同一页面而出现缺页中断时,该页已经在内存,内核只需要将进程B的页表登记项指向次页即可。 三、mmap及其相关系统调用 mmap()系统调用使得进城之间通过映射同一个普通文件实现共享内存。普通文件被映射到进程地址空间后,进程可以像访问普通内存一样对文件进行访问,不必再调用read,write 等操作。 mmap()系统调用形式如下: mmap的作用是映射文件描述符和指定文件的(off_t off)区域至调用进程的(addr,addr *len)的内存区域,如下图所示: 参数: fd:为即将映射到进程空间的文件描述字,一般由open()返回,同时,fd可以指定为-1,此时须指定flags参数中的MAP_ANON,表明进行的是匿名映射(不涉及具体的文件名,避免了文件的创建及打开,很显然只能用于具有亲缘关系的进程间进行通信)。 len:是映射到调用进程地址空间的字节数,它从被映射文件开头offset个字节开始算起。 prot:指定空想内存的访问权限。可取如下几个值的或:PROT_READ(可读)、PROT_WRITE(可写)、PROT_EXEC(可执行)、PROT_NONE(不可访问)。 flag:由以下几个常值指定:MAP_SHARED、MAP_PRIVATE、MAP_FIXED,其中,MAP_SHARED,MAP_PRIVATE必选其一,而MAP_FIXED则不推荐使用。 offset:一般设为0,表示从文件头开始映射。 addr:指定文件应被映射到进程空间的起始地址,一般被指定一个空指针,此时选择起始地址的任务留给内核来完成。 函数的返回值为最后文件映射到进程空间的地址,进程可直接操作起始地址为该值的有效地址。 四、mmap基础用例 1、通过共享内存映射的方式修改文件 2 私有映射无法修改文件 五、使用共享内存映射实现两个进程之间的通信 两个程序映射到同一个文件到自己的地址空间,进程A先运行,每个两秒读取映射区域,看是否发生变化,进程B后运行,它修改映射区域,然后退出,此时进程A能够观察到存储映射区的变化 进程A的代码: 进程B的代码 六、通过匿名映射实现父子进程通信 七、对mmap()返回地址的访问 linux采用的是页式管理机制。对于用mmap()映射普通文件来说,进程会在自己的地址空间新增一块空间,空间大小由mmap()的len参数指定,注意,进程并不一定能够对全部新增空间都能进行有效访问。进程能够访问的有效地址大小取决于文件被映射部分的大小。简单的说,能够容纳文件被映射部分大小的最少页面个数决定了进程从mmap()返回的地址开始,能够有效访问的地址空间大小。超过这个空间大小,内核会根据超过的严重程度返回发送不同的信号给进程。可用如下图示说明: 总结一下就是,文件大小,mmap()的参数len都不能决定进程能访问的大小,而是容纳文件被映射部分的最小页面数决定进程能访问的大小,下面看一个实例: 映射到内存后通过映射的指针addr来修改内容的话是修改共享内存里的内容还是文件的内容呢?通过addr修改的内容是修改的是共享内容中的内容。至于是否修改了文件中的内容,要看文件的类型。
对于显示设备等文件来说,修改的也是文件的内容,因为他直接写到了显存中。对于普通文件,
在close文件时,kernel会将数据更新到硬盘等存储设备中。对显示设备文件(显卡)进行内存的映射,并不会在内存中新分配一块内存,
而是直接将显存地址通过addr参数传给应用程序。这样应用程序通过内存映射修改文件时,
其实就是直接修改显存中的内容(也就是改变显示内容)。

#include
1 //测试文件 data.txt 后面的程序也要用到
2 aaaaaaaaa
3 bbbbbbbbb
4 cccccccccccc
5 ddddddddd
1 #include 1 //将文件私有映射到进程的地址空间
2 if((mapped = (char *)mmap(NULL,sb.st_size,PROT_READ|
3 PROT_WRITE, MAP_PRIVATE, fd, 0))==(void *)-1){
4 perror("mmap"); 1 #include 1 #include 1 #include 
#include