Memcached源码分析 - 命令解析(2)
Memcached源码分析 - 网络模型(1)
Memcached源码分析 - 命令解析(2)
Memcached源码分析 - 数据存储(3)
Memcached源码分析 - 增删改查操作(4)
Memcached源码分析 - 内存存储机制Slabs(5)
Memcached源码分析 - LRU淘汰算法(6)
Memcached源码分析 - 消息回应(7)
开篇
这篇博文的目的主要为了讲清楚Memcached在解析命令的处理逻辑,会穿插一些Memcached的命令行操作。希望能够对大家有所帮助。另外这篇文章很多内容参考了大神前辈的文章,都一一在参考文章当中列出来了。
memcached 常用命令
memcached 包括五种基本 memcached 命令执行最简单的操作。这些命令和操作包括:set、add、replace、get、delete。
常用命令格式
command
参数说明如下:
command set/add/replace
key key 用于查找缓存值
flags 可以包括键值对的整型参数,客户机使用它存储关于键值对的额外信息
expiration time 在缓存中保存键值对的时间长度(以秒为单位,0 表示永远)
bytes 在缓存中存储的字节点
value 存储的值(始终位于第二行)
set命令
set 命令用于向缓存添加新的键值对。如果键已经存在,则之前的值将被替换。
注意以下交互,它使用了 set 命令:
set userId 0 0 5
12345
STORED
如果使用 set 命令正确设定了键值对,服务器将使用单词 STORED 进行响应。
本示例向缓存中添加了一个键值对,其键为userId,其值为12345。
并将过期时间设置为 0,这将向 memcached 通知您希望将此值存储在缓存中直到删除它为止。
add命令
仅当缓存中不存在键时,add 命令才会向缓存中添加一个键值对。如果缓存中已经存在键,则之前的值将仍然保持相同,并且您将获得响应 NOT_STORED。
下面是使用 add 命令的标准交互:
set userId 0 0 5
12345
STORED
add userId 0 0 5
55555
NOT_STORED
add companyId 0 0 3
564
STORED
replace命令
仅当键已经存在时,replace 命令才会替换缓存中的键。如果缓存中不存在键,那么您将从 memcached 服务器接受到一条 NOT_STORED 响应。
下面是使用 replace 命令的标准交互:
replace accountId 0 0 5
67890 NOT_STORED
set accountId 0 0 5
67890 STORED
replace accountId 0 0 5
55555 STOREDget命令
get 命令用于检索与之前添加的键值对相关的值。您将使用 get 执行大多数检索操作。
下面是使用 get 命令的典型交互:
set userId 0 0 5
STORED
get userId
VALUE userId 0 5
END
get bob
END
如您所见,get 命令相当简单。您使用一个键来调用 get,如果这个键存在于缓存中,则返回相应的值。如果不存在,则不返回任何内容。
delete命令
最后一个基本命令是 delete。delete 命令用于删除 memcached 中的任何现有值。您将使用一个键调用delete,
如果该键存在于缓存中,则删除该值。如果不存在,则返回一条NOT_FOUND 消息。
下面是使用 delete 命令的客户机服务器交互:
set userId 0 0 5
STORED
delete bob
NOT_FOUND
delete userId
DELETED
get userId
END
可以在 memcached 中使用的两个高级命令是 gets 和 cas。gets 和cas 命令需要结合使用。
您将使用这两个命令来确保不会将现有的名称/值对设置为新值(如果该值已经更新过)。
我们来分别看看这些命令。
gets命令
gets 命令的功能类似于基本的 get 命令。两个命令之间的差异在于,gets 返回的信息稍微多一些:64 位的整型值非常像名称/值对的 “版本” 标识符。
下面是使用 gets 命令的客户机服务器交互:
set userId 0 0 5
STORED
get userId
VALUE userId 0 5
END
gets userId
VALUE userId 0 5 4
END
考虑 get 和 gets 命令之间的差异。gets 命令将返回一个额外的值 — 在本例中是整型值 4,用于标识名称/值对。
如果对此名称/值对执行另一个set 命令,则gets 返回的额外值将会发生更改,以表明名称/值对已经被更新。显示了一个例子:
set userId 0 0 5
STORED
gets userId
VALUE userId 0 5 5
END
您看到 gets 返回的值了吗?它已经更新为 5。您每次修改名称/值对时,该值都会发生更改。
cas命令
cas(check 和 set)是一个非常便捷的 memcached 命令,用于设置名称/值对的值(如果该名称/值对在您上次执行 gets 后没有更新过)。
它使用与 set 命令相类似的语法,但包括一个额外的值:gets 返回的额外值。
注意以下使用 cas 命令的交互:
set userId 0 0 5
STORED
gets userId
VALUE userId 0 5 6
END
cas userId 0 0 5 6
STORED
命令解析过程图解

当客户端和Memcached建立TCP连接后,Memcached会基于Libevent的event事件来监听客户端是否有可以读取的数据。
当客户端有命令数据报文上报的时候,就会触发drive_machine方法中的conn_read这个Case,在进入这个状态之前经过conn_new_cmd->conn_waiting->conn_read的流程。
memcached通过try_read_network方法读取客户端的报文。如果读取失败,则返回conn_closing,去关闭客户端的连接;如果没有读取到任何数据,则会返回conn_waiting,继续等待客户端的事件到来,并且退出drive_machine的循环;如果数据读取成功,则会将状态转交给conn_parse_cmd处理,读取到的数据会存储在c->rbuf容器中。
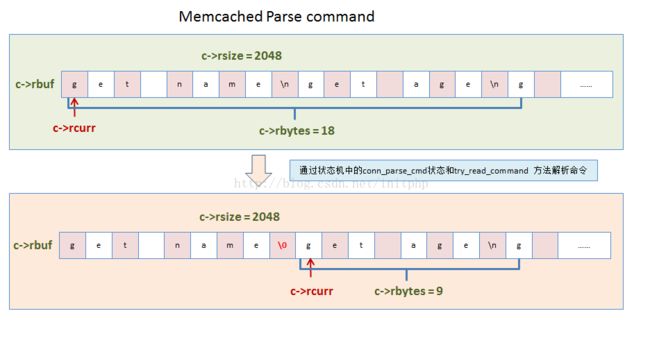
conn_parse_cmd主要的工作就是用来解析命令。主要通过try_read_command这个方法来读取c->rbuf中的命令数据,通过\n来分隔数据报文的命令。如果c->buf内存块中的数据匹配不到\n,则返回继续等待客户端的命令数据报文到来conn_waiting;否则就会转交给process_command方法,来处理具体的命令(命令解析会通过\0符号来分隔)。
process_command主要用来处理具体的命令。其中tokenize_command这个方法非常重要,将命令拆解成多个元素(KEY的最大长度250)。例如我们以get命令为例,最终会跳转到process_get_command这个命令 process_*_command这一系列就是处理具体的命令逻辑的。
我们进入process_get_command,当获取数据处理完毕之后,会转交到conn_mwrite这个状态。如果获取数据失败,则关闭连接。
进入conn_mwrite后,主要是通过transmit方法来向客户端提交数据。如果写数据失败,则关闭连接或退出drive_machine循环;如果写入成功,则又转交到conn_new_cmd这个状态。
conn_new_cmd这个状态主要是处理c->rbuf中剩余的命令。主要看一下reset_cmd_handler这个方法,这个方法会去判断c->rbytes中是否还有剩余的报文没处理,如果未处理,则转交到conn_parse_cmd(第四步)继续解析剩余命令;如果已经处理了,则转交到conn_waiting,等待新的事件到来。在转交之前,每次都会执行一次conn_shrink方法。
conn_shrink方法主要用来处理命令报文容器c->rbuf和输出内容的容器是否数据满了?是否需要扩大buffer的大小,是否需要移动内存块。接受命令报文的初始化内存块大小2048,最大8192。
命令解析过程源码分析
Memcached的状态
|----------------+-----------------------------------------------------------|
| Name | Meaning |
|----------------+-----------------------------------------------------------|
| conn_closing | Shutting down the connection. |
| conn_listening | Listening for new connections or a new UDP request. |
| conn_mwrite | Writing a complex response, e.g., to a "get" command. |
| conn_new_cmd | Connection is being prepared to accept a new command. |
| conn_nread | Reading extended data, typically for a command such as |
| | "set" or "put". |
| conn_parse_cmd | The server has received a command and is in the middle |
| | of parsing it or executing it. |
| conn_read | Reading newly-arrived command data. |
| conn_swallow | Discarding excess input, e.g., after an error has |
| | occurred. |
| conn_waiting | A partial command has been received and the server is |
| | waiting for the rest of it to arrive (note the difference |
| | between this and conn_nread). |
| conn_write | Writing a simple response (anything that doesn't involve |
| | sending back multiple lines of response data). |
|----------------+-----------------------------------------------------------|
conn_read状态转移
conn_read的第一次转移过程按照conn_new_cmd -> conn_waiting -> conn_read进行转移,按照下面顺序进行转移。
- 在worker线程第一次新增一个socket连接的时候初始状态为conn_new_cmd。
- 在conn_new_cmd状态的处理逻辑中通过reset_cmd_handler将状态设置为conn_waiting。
- 在conn_waiting状态的处理逻辑中通过conn_set_state(c, conn_read)设置为conn_read。
- 在conn_read状态下开始进入读取数据的逻辑。
static void drive_machine(conn *c) {
bool stop = false;
int sfd;
socklen_t addrlen;
struct sockaddr_storage addr;
int nreqs = settings.reqs_per_event;
int res;
const char *str;
assert(c != NULL);
while (!stop) {
switch(c->state) {
case conn_waiting:
if (!update_event(c, EV_READ | EV_PERSIST)) {
if (settings.verbose > 0)
fprintf(stderr, "Couldn't update event\n");
conn_set_state(c, conn_closing);
break;
}
conn_set_state(c, conn_read);
stop = true;
break;
case conn_read:
// 读取数据过程,暂时省略代码
break;
case conn_parse_cmd :
if (try_read_command(c) == 0) {
/* wee need more data! */
conn_set_state(c, conn_waiting);
}
break;
case conn_new_cmd:
--nreqs;
if (nreqs >= 0) {
reset_cmd_handler(c);
}
break;
}
return;
}
static void reset_cmd_handler(conn *c) {
c->cmd = -1;
c->substate = bin_no_state;
if(c->item != NULL) {
item_remove(c->item);
c->item = NULL;
}
conn_shrink(c);
if (c->rbytes > 0) {
conn_set_state(c, conn_parse_cmd);
} else {
conn_set_state(c, conn_waiting);
}
}
conn_read过程
memcached通过try_read_network方法读取客户端的报文。如果读取失败,则返回conn_closing,去关闭客户端的连接;如果没有读取到任何数据,则会返回conn_waiting,继续等待客户端的事件到来,并且退出drive_machine的循环;如果数据读取成功,则会将状态转交给conn_parse_cmd处理,读取到的数据会存储在c->rbuf容器中。
static void drive_machine(conn *c) {
bool stop = false;
int sfd;
socklen_t addrlen;
struct sockaddr_storage addr;
int nreqs = settings.reqs_per_event;
int res;
const char *str;
assert(c != NULL);
while (!stop) {
switch(c->state) {
case conn_read:
res = IS_UDP(c->transport) ? try_read_udp(c) : try_read_network(c);
switch (res) {
case READ_NO_DATA_RECEIVED:
conn_set_state(c, conn_waiting);
break;
case READ_DATA_RECEIVED:
conn_set_state(c, conn_parse_cmd);
break;
case READ_ERROR:
conn_set_state(c, conn_closing);
break;
case READ_MEMORY_ERROR: /* Failed to allocate more memory */
/* State already set by try_read_network */
break;
}
break;
}
}
return;
}
try_read_network过程
这个方法主要是读取TCP网络数据。读取到的数据会放进c->rbuf的buf中。如果buf没有空间存储更多数据的时候,就会触发内存块的重新分配。重新分配,memcached限制了4次,估计是担忧客户端的恶意攻击导致存储命令行数据报文的buf不断的realloc。
conn_set_state(c, conn_parse_cmd);在接收网络传输的数据后将状态机的状态设置为conn_parse_cmd,进入conn_parse_cmd的解析过程。
static enum try_read_result try_read_network(conn *c) {
enum try_read_result gotdata = READ_NO_DATA_RECEIVED;
int res;
int num_allocs = 0;
assert(c != NULL);
if (c->rcurr != c->rbuf) {
if (c->rbytes != 0) /* otherwise there's nothing to copy */
memmove(c->rbuf, c->rcurr, c->rbytes);
c->rcurr = c->rbuf;
}
while (1) {
if (c->rbytes >= c->rsize) {
if (num_allocs == 4) {
return gotdata;
}
++num_allocs;
char *new_rbuf = realloc(c->rbuf, c->rsize * 2);
if (!new_rbuf) {
STATS_LOCK();
stats.malloc_fails++;
STATS_UNLOCK();
if (settings.verbose > 0) {
fprintf(stderr, "Couldn't realloc input buffer\n");
}
c->rbytes = 0; /* ignore what we read */
out_of_memory(c, "SERVER_ERROR out of memory reading request");
c->write_and_go = conn_closing;
return READ_MEMORY_ERROR;
}
c->rcurr = c->rbuf = new_rbuf;
c->rsize *= 2;
}
int avail = c->rsize - c->rbytes;
res = read(c->sfd, c->rbuf + c->rbytes, avail);
if (res > 0) {
pthread_mutex_lock(&c->thread->stats.mutex);
c->thread->stats.bytes_read += res;
pthread_mutex_unlock(&c->thread->stats.mutex);
gotdata = READ_DATA_RECEIVED;
c->rbytes += res;
if (res == avail) {
continue;
} else {
break;
}
}
if (res == 0) {
return READ_ERROR;
}
if (res == -1) {
if (errno == EAGAIN || errno == EWOULDBLOCK) {
break;
}
return READ_ERROR;
}
}
return gotdata;
}
conn_parse_cmd过程
这个方法主要是用来读取rbuf中的命令的。
例如命令:set username zhuli\r\n get username \n,则会通过\n这个换行符来分隔数据报文中的命令。
因为数据报文会有粘包和拆包的特性,所以只有等到命令行完整了才能进行解析。所有只有匹配到了\n符号,才能匹配一个完整的命令。
在整个解析过程中,每次解析到\n符号就说明一个完整的命令了,然后就进入处理这个命令的过程,进行处理后返回客户端后再次解析。
case conn_parse_cmd :
if (try_read_command(c) == 0) {
conn_set_state(c, conn_waiting);
}
static int try_read_command(conn *c) {
// 省略不相关的代码,协议主要是有binary还是ascii码两种
if (c->protocol == binary_prot) {
//省略不相关的代码
} else {
char *el, *cont;
//查找以\n做分割的字符,\n表示一个命令行的结束
el = memchr(c->rcurr, '\n', c->rbytes);
if (!el) {
if (c->rbytes > 1024) {
char *ptr = c->rcurr;
while (*ptr == ' ') { /* ignore leading whitespaces */
++ptr;
}
if (ptr - c->rcurr > 100 ||
(strncmp(ptr, "get ", 4) && strncmp(ptr, "gets ", 5))) {
conn_set_state(c, conn_closing);
return 1;
}
}
return 0;
}
cont = el + 1;
if ((el - c->rcurr) > 1 && *(el - 1) == '\r') {
el--;
}
*el = '\0';
assert(cont <= (c->rcurr + c->rbytes));
c->last_cmd_time = current_time;
process_command(c, c->rcurr);
c->rbytes -= (cont - c->rcurr);
c->rcurr = cont;
assert(c->rcurr <= (c->rbuf + c->rsize));
}
return 1;
}
process_command过程
process_command的内容就是执行接收的单个命令行,内部通过tokenize_command这个方法将命令的关键字挨个进行解析,例如:set username zhuli\n,则会分解成三个元素:set和username和zhuli这三个元素。
针对不同的命令会进入不同的执行逻辑,如果process_get_command执行get命令的相关操作。
static void process_command(conn *c, char *command) {
token_t tokens[MAX_TOKENS];
size_t ntokens;
int comm;
assert(c != NULL);
MEMCACHED_PROCESS_COMMAND_START(c->sfd, c->rcurr, c->rbytes);
c->msgcurr = 0;
c->msgused = 0;
c->iovused = 0;
if (add_msghdr(c) != 0) {
out_of_memory(c, "SERVER_ERROR out of memory preparing response");
return;
}
ntokens = tokenize_command(command, tokens, MAX_TOKENS);
if (ntokens >= 3 &&
((strcmp(tokens[COMMAND_TOKEN].value, "get") == 0) ||
(strcmp(tokens[COMMAND_TOKEN].value, "bget") == 0))) {
process_get_command(c, tokens, ntokens, false, false);
} else if ((ntokens == 6 || ntokens == 7) &&
((strcmp(tokens[COMMAND_TOKEN].value, "add") == 0 && (comm = NREAD_ADD)) ||
(strcmp(tokens[COMMAND_TOKEN].value, "set") == 0 && (comm = NREAD_SET)) ||
(strcmp(tokens[COMMAND_TOKEN].value, "replace") == 0 && (comm = NREAD_REPLACE)) ||
(strcmp(tokens[COMMAND_TOKEN].value, "prepend") == 0 && (comm = NREAD_PREPEND)) ||
(strcmp(tokens[COMMAND_TOKEN].value, "append") == 0 && (comm = NREAD_APPEND)) )) {
process_update_command(c, tokens, ntokens, comm, false);
} else if ((ntokens == 7 || ntokens == 8) && (strcmp(tokens[COMMAND_TOKEN].value, "cas") == 0 && (comm = NREAD_CAS))) {
process_update_command(c, tokens, ntokens, comm, true);
}
//省略很多相关代码,不同的命令走不同的执行方法
}
这个方法主要用于分解命令。具体是将一个命令语句分解成多个元素,例如:set username zhuli\n,则会分解成三个元素:set和username和zhuli这三个元素。
tokenize_command需要分析的下一个细节就是关于最后一个元素的问题,如果解析的命令个数没有达到max_tokens,最后一个元素内容为空,如果达到了max_tokens,最后一个元素时剩余的未解析字符串。
static size_t tokenize_command(char *command, token_t *tokens, const size_t max_tokens) {
char *s, *e;
size_t ntokens = 0;
size_t len = strlen(command);
unsigned int i = 0;
assert(command != NULL && tokens != NULL && max_tokens > 1);
s = e = command;
for (i = 0; i < len; i++) {
if (*e == ' ') {
if (s != e) {
tokens[ntokens].value = s;
tokens[ntokens].length = e - s;
ntokens++;
*e = '\0';
if (ntokens == max_tokens - 1) {
e++;
s = e; /* so we don't add an extra token */
break;
}
}
s = e + 1;
}
e++;
}
if (s != e) {
tokens[ntokens].value = s;
tokens[ntokens].length = e - s;
ntokens++;
}
/*
* If we scanned the whole string, the terminal value pointer is null,
* otherwise it is the first unprocessed character.
*/
tokens[ntokens].value = *e == '\0' ? NULL : e;
tokens[ntokens].length = 0;
ntokens++;
return ntokens;
}
process_get_command
process_get_command内部主要是遍历token执行get操作获取对应的数据。这里do和while双重循环是因为我们在token分割的时候后面有一部分未分割,需要在这里进行处理。
完成后通过conn_set_state(c, conn_mwrite)设置写状态准备进入数据发回阶段。
static inline void process_get_command(conn *c, token_t *tokens, size_t ntokens, bool return_cas, bool should_touch) {
char *key;
size_t nkey;
int i = 0;
int si = 0;
item *it;
token_t *key_token = &tokens[KEY_TOKEN];
char *suffix;
int32_t exptime_int = 0;
rel_time_t exptime = 0;
bool fail_length = false;
assert(c != NULL);
if (should_touch) {
// For get and touch commands, use first token as exptime
if (!safe_strtol(tokens[1].value, &exptime_int)) {
out_string(c, "CLIENT_ERROR invalid exptime argument");
return;
}
key_token++;
exptime = realtime(exptime_int);
}
do {
while(key_token->length != 0) {
key = key_token->value;
nkey = key_token->length;
if (nkey > KEY_MAX_LENGTH) {
fail_length = true;
goto stop;
}
it = limited_get(key, nkey, c, exptime, should_touch);
if (settings.detail_enabled) {
stats_prefix_record_get(key, nkey, NULL != it);
}
if (it) {
if (_ascii_get_expand_ilist(c, i) != 0) {
item_remove(it);
goto stop;
}
/*
* Construct the response. Each hit adds three elements to the
* outgoing data list:
* "VALUE "
* key
* " " + flags + " " + data length + "\r\n" + data (with \r\n)
*/
if (return_cas || !settings.inline_ascii_response)
{
MEMCACHED_COMMAND_GET(c->sfd, ITEM_key(it), it->nkey,
it->nbytes, ITEM_get_cas(it));
int nbytes;
suffix = _ascii_get_suffix_buf(c, si);
if (suffix == NULL) {
item_remove(it);
goto stop;
}
si++;
nbytes = it->nbytes;
int suffix_len = make_ascii_get_suffix(suffix, it, return_cas, nbytes);
if (add_iov(c, "VALUE ", 6) != 0 ||
add_iov(c, ITEM_key(it), it->nkey) != 0 ||
(settings.inline_ascii_response && add_iov(c, ITEM_suffix(it), it->nsuffix - 2) != 0) ||
add_iov(c, suffix, suffix_len) != 0)
{
item_remove(it);
goto stop;
}
#ifdef EXTSTORE
if (it->it_flags & ITEM_HDR) {
if (_get_extstore(c, it, c->iovused-3, 4) != 0) {
pthread_mutex_lock(&c->thread->stats.mutex);
c->thread->stats.get_oom_extstore++;
pthread_mutex_unlock(&c->thread->stats.mutex);
item_remove(it);
goto stop;
}
} else if ((it->it_flags & ITEM_CHUNKED) == 0) {
#else
if ((it->it_flags & ITEM_CHUNKED) == 0) {
#endif
add_iov(c, ITEM_data(it), it->nbytes);
} else if (add_chunked_item_iovs(c, it, it->nbytes) != 0) {
item_remove(it);
goto stop;
}
}
else
{
MEMCACHED_COMMAND_GET(c->sfd, ITEM_key(it), it->nkey,
it->nbytes, ITEM_get_cas(it));
if (add_iov(c, "VALUE ", 6) != 0 ||
add_iov(c, ITEM_key(it), it->nkey) != 0)
{
item_remove(it);
goto stop;
}
if ((it->it_flags & ITEM_CHUNKED) == 0)
{
if (add_iov(c, ITEM_suffix(it), it->nsuffix + it->nbytes) != 0)
{
item_remove(it);
goto stop;
}
} else if (add_iov(c, ITEM_suffix(it), it->nsuffix) != 0 ||
add_chunked_item_iovs(c, it, it->nbytes) != 0) {
item_remove(it);
goto stop;
}
}
if (settings.verbose > 1) {
int ii;
fprintf(stderr, ">%d sending key ", c->sfd);
for (ii = 0; ii < it->nkey; ++ii) {
fprintf(stderr, "%c", key[ii]);
}
fprintf(stderr, "\n");
}
/* item_get() has incremented it->refcount for us */
pthread_mutex_lock(&c->thread->stats.mutex);
if (should_touch) {
c->thread->stats.touch_cmds++;
c->thread->stats.slab_stats[ITEM_clsid(it)].touch_hits++;
} else {
c->thread->stats.lru_hits[it->slabs_clsid]++;
c->thread->stats.get_cmds++;
}
pthread_mutex_unlock(&c->thread->stats.mutex);
#ifdef EXTSTORE
/* If ITEM_HDR, an io_wrap owns the reference. */
if ((it->it_flags & ITEM_HDR) == 0) {
*(c->ilist + i) = it;
i++;
}
#else
*(c->ilist + i) = it;
i++;
#endif
} else {
pthread_mutex_lock(&c->thread->stats.mutex);
if (should_touch) {
c->thread->stats.touch_cmds++;
c->thread->stats.touch_misses++;
} else {
c->thread->stats.get_misses++;
c->thread->stats.get_cmds++;
}
MEMCACHED_COMMAND_GET(c->sfd, key, nkey, -1, 0);
pthread_mutex_unlock(&c->thread->stats.mutex);
}
key_token++;
}
/*
* If the command string hasn't been fully processed, get the next set
* of tokens.
*/
if(key_token->value != NULL) {
ntokens = tokenize_command(key_token->value, tokens, MAX_TOKENS);
key_token = tokens;
}
} while(key_token->value != NULL);
stop:
c->icurr = c->ilist;
c->ileft = i;
if (return_cas || !settings.inline_ascii_response) {
c->suffixcurr = c->suffixlist;
c->suffixleft = si;
}
if (settings.verbose > 1)
fprintf(stderr, ">%d END\n", c->sfd);
if (key_token->value != NULL || add_iov(c, "END\r\n", 5) != 0
|| (IS_UDP(c->transport) && build_udp_headers(c) != 0)) {
if (fail_length) {
out_string(c, "CLIENT_ERROR bad command line format");
} else {
out_of_memory(c, "SERVER_ERROR out of memory writing get response");
}
conn_release_items(c);
}
else {
conn_set_state(c, conn_mwrite);
c->msgcurr = 0;
}
}
conn_mwrite和transmit过程
主要用于向客户端写数据。写完数据后,如果写失败,则关闭连接;如果写成功,则会将状态修改成conn_new_cmd,继续解析c->rbuf中剩余的命令。
transmit主要执行的就是发送数据到客户端,发送成功后修改状态conn_set_state(c, conn_new_cmd)。
case conn_mwrite:
switch (transmit(c)) {
case TRANSMIT_COMPLETE:
if (c->state == conn_mwrite) {
conn_release_items(c);
/* XXX: I don't know why this wasn't the general case */
if(c->protocol == binary_prot) {
conn_set_state(c, c->write_and_go);
} else {
conn_set_state(c, conn_new_cmd);
}
} else if (c->state == conn_write) {
if (c->write_and_free) {
free(c->write_and_free);
c->write_and_free = 0;
}
conn_set_state(c, c->write_and_go);
} else {
if (settings.verbose > 0)
fprintf(stderr, "Unexpected state %d\n", c->state);
conn_set_state(c, conn_closing);
}
break;
case TRANSMIT_INCOMPLETE:
case TRANSMIT_HARD_ERROR:
break; /* Continue in state machine. */
case TRANSMIT_SOFT_ERROR:
stop = true;
break;
}
break;
/*
* Transmit the next chunk of data from our list of msgbuf structures.
*
* Returns:
* TRANSMIT_COMPLETE All done writing.
* TRANSMIT_INCOMPLETE More data remaining to write.
* TRANSMIT_SOFT_ERROR Can't write any more right now.
* TRANSMIT_HARD_ERROR Can't write (c->state is set to conn_closing)
*/
static enum transmit_result transmit(conn *c) {
assert(c != NULL);
if (c->msgcurr < c->msgused &&
c->msglist[c->msgcurr].msg_iovlen == 0) {
/* Finished writing the current msg; advance to the next. */
c->msgcurr++;
}
if (c->msgcurr < c->msgused) {
ssize_t res;
struct msghdr *m = &c->msglist[c->msgcurr];
res = sendmsg(c->sfd, m, 0);
if (res > 0) {
pthread_mutex_lock(&c->thread->stats.mutex);
c->thread->stats.bytes_written += res;
pthread_mutex_unlock(&c->thread->stats.mutex);
/* We've written some of the data. Remove the completed
iovec entries from the list of pending writes. */
while (m->msg_iovlen > 0 && res >= m->msg_iov->iov_len) {
res -= m->msg_iov->iov_len;
m->msg_iovlen--;
m->msg_iov++;
}
/* Might have written just part of the last iovec entry;
adjust it so the next write will do the rest. */
if (res > 0) {
m->msg_iov->iov_base = (caddr_t)m->msg_iov->iov_base + res;
m->msg_iov->iov_len -= res;
}
return TRANSMIT_INCOMPLETE;
}
if (res == -1 && (errno == EAGAIN || errno == EWOULDBLOCK)) {
if (!update_event(c, EV_WRITE | EV_PERSIST)) {
if (settings.verbose > 0)
fprintf(stderr, "Couldn't update event\n");
conn_set_state(c, conn_closing);
return TRANSMIT_HARD_ERROR;
}
return TRANSMIT_SOFT_ERROR;
}
/* if res == 0 or res == -1 and error is not EAGAIN or EWOULDBLOCK,
we have a real error, on which we close the connection */
if (settings.verbose > 0)
perror("Failed to write, and not due to blocking");
if (IS_UDP(c->transport))
conn_set_state(c, conn_read);
else
conn_set_state(c, conn_closing);
return TRANSMIT_HARD_ERROR;
} else {
return TRANSMIT_COMPLETE;
}
}
conn_new_cmd过程
conn_new_cmd内部通过reset_cmd_handler将状态设置为conn_parse_cmd,重新进入命令解析过程。重新进行一个大循环。
case conn_new_cmd:
/* Only process nreqs at a time to avoid starving other
connections */
--nreqs;
if (nreqs >= 0) {
reset_cmd_handler(c);
} else {
pthread_mutex_lock(&c->thread->stats.mutex);
c->thread->stats.conn_yields++;
pthread_mutex_unlock(&c->thread->stats.mutex);
if (c->rbytes > 0) {
/* We have already read in data into the input buffer,
so libevent will most likely not signal read events
on the socket (unless more data is available. As a
hack we should just put in a request to write data,
because that should be possible ;-)
*/
if (!update_event(c, EV_WRITE | EV_PERSIST)) {
if (settings.verbose > 0)
fprintf(stderr, "Couldn't update event\n");
conn_set_state(c, conn_closing);
break;
}
}
stop = true;
}
break;
static void reset_cmd_handler(conn *c) {
c->cmd = -1;
c->substate = bin_no_state;
if(c->item != NULL) {
item_remove(c->item);
c->item = NULL;
}
conn_shrink(c);
if (c->rbytes > 0) {
conn_set_state(c, conn_parse_cmd);
} else {
conn_set_state(c, conn_waiting);
}
}
相关过程图解
读取客户端的数据

解析buf中的命令
命令拆分

内存块重设置

参考文章
Memcached源码分析 - Memcached源码分析之命令解析(2)
memcached 常用命令及使用说明