进程概念
1.几种进程的调度算法
在OS中调度的是实质是一种资源分配。
调度算法是指:根据系统资源分配策略所规定的资源分配算法。对于不同的系统或系统目标,通常采用不同的调度算法。
1.先来先服务和短作业(进程)优先调度算法
先来先服务 (FCFS,first come first served)
在所有调度算法中,最简单的是非抢占式的FCFS算法。
算法原理:进程按照它们请求CPU的顺序使用CPU.就像你买东西去排队,谁第一个排,谁就先被执行,在它执行的过程中,不会中断它。当其他人也想进入内存被执行,就要排队等着,如果在执行过程中出现一些事,他现在不想排队了,下一个排队的就补上。此时如果他又想排队了,只能站到队尾去。
算法优点:易于理解且实现简单,只需要一个队列(FIFO),且相当公平
算法缺点:比较有利于长进程,而不利于短进程,有利于CPU 繁忙的进程,而不利于I/O 繁忙的进程最短作业优先(SJF, Shortest Job First)
短作业优先(SJF, Shortest Job First)又称为“短进程优先”SPN(Shortest Process Next);这是对FCFS算法的改进,其目标是减少平均周转时间。
算法原理:对预计执行时间短的进程优先分派处理机。通常后来的短进程不抢先正在执行的进程。
算法优点:相比FCFS 算法,该算法可改善平均周转时间和平均带权周转时间,缩短进程的等待时间,提高系统的吞吐量。
算法缺点:对长进程非常不利,可能长时间得不到执行,且未能依据进程的紧迫程度来划分执行的优先级,以及难以准确估计进程的执行时间,从而影响调度性能。2.高优先权优先调度算法
优先权调度算法的类型
为了照顾紧迫型作业,使之在进入系统后便获得优先处理,引入了最高优先权优先(FPF)调度算法。此算法常被用于批处理系统中,作为作业调度算法,也作为多种操作系统中的进程调度算法,还可用于实时系统中。当把该算法用于作业调度时,系统将从后备队列中选择若干个优先权最高的作业装入内存。当用于进程调度时,该算法是把处理机分配给就绪队列中优先权最高的进程,这时,又可进一步把该算法分成如下两种。
1) 非抢占式优先权算法
在这种方式下,系统一旦把处理机分配给就绪队列中优先权最高的进程后,该进程便一直执行下去,直至完成;或因发生某事件使该进程放弃处理机时,系统方可再将处理机重 新分配给另一优先权最高的进程。这种调度算法主要用于批处理系统中;也可用于某些对实时性要求不严的实时系统中。
2) 抢占式优先权调度算法
在这种方式下,系统同样是把处理机分配给优先权最高的进程,使之执行。但在其执行期间,只要又出现了另一个其优先权更高的进程,进程调度程序就立即停止当前进程(原 优先权最高的进程)的执行,重新将处理机分配给新到的优先权最高的进程。因此,在采用这种调度算法时,是每当系统中出现一个新的就绪进程i 时,就将其优先权Pi与正在执行的进程j 的优先权Pj进行比较。如果Pi≤Pj,原进程Pj便继续执行;但如果是Pi>Pj,则立即停止Pj的执行,做进程切换,使i 进程投入执行。显然,这种抢占式的优先权调度算法能更好地满足紧迫作业的要求,故而常用于要求比较严格的实时系统中,以及对性能要求较高的批处理和分时系 统中。
3)高响应比优先调度算法
如果我们能为每个作业引入动态优先权,并使作业的优先级随着等待时间的增加而以速率a 提高,则长作业在等待一定的时间后,必然有机会分配到处理机。该优先权的变化规律可描述为:
由于等待时间与服务时间之和就是系统对该作业的响应时间,故该优先权又相当于响应比RP。据此,又可表示为:
由上式可以看出:(1) 如果作业的等待时间相同,则要求服务的时间愈短,其优先权愈高,因而该算法有利于短作业。
(2) 当要求服务的时间相同时,作业的优先权决定于其等待时间,等待时间愈长,其优先权愈高,因而它实现的是先来先服务。
(3) 对于长作业,作业的优先级可以随等待时间的增加而提高,当其等待时间足够长时,其优先级便可升到很高,从而也可获得处理机。简言之,该算法既照顾了短作 业,又考虑了作业到达的先后次序,不会使长作业长期得不到服务。因此,该算法实现了一种较好的折衷。当然,在利用该算法时,每要进行调度之前,都须先做响 应比的计算,这会增加系统开销。
最高响应比优先法(HRRN,Highest Response Ratio Next)
最高响应比优先法(HRRN,Highest Response Ratio Next)是对FCFS方式和SJF方式的一种综合平衡。FCFS方式只考虑每个作业的等待时间而未考虑执行时间的长短,而SJF方式只考虑执行时间而未考虑等待时间的长短。因此,这两种调度算法在某些极端情况下会带来某些不便。HRN调度策略同时考虑每个作业的等待时间长短和估计需要的执行时间长短,从中选出响应比最高的作业投入执行。这样,即使是长作业,随着它等待时间的增加,W / T也就随着增加,也就有机会获得调度执行。这种算法是介于FCFS和SJF之间的一种折中算法。
算法原理:响应比R定义如下: R =(W+T)/T = 1+W/T
其中T为该作业估计需要的执行时间,W为作业在后备状态队列中的等待时间。每当要进行作业调度时,系统计算每个作业的响应比,选择其中R最大者投入执行。
算法优点:由于长作业也有机会投入运行,在同一时间内处理的作业数显然要少于SJF法,从而采用HRRN方式时其吞吐量将小于采用SJF 法时的吞吐量。
算法缺点:由于每次调度前要计算响应比,系统开销也要相应增加。3.基于时间片的轮转调度算法
1)时间片轮转法
在早期的时间 片轮转法中,系统将所有的就绪进程按先来先服务的原则排成一个队列,每次调度时,把CPU 分配给队首进程,并令其执行一个时间片。时间片的大小从几ms 到几百ms。当执行的时间片用完时,由一个计时器发出时钟中断请求,调度程序便据此信号来停止该进程的执行,并将它送往就绪队列的末尾;然后,再把处理机 分配给就绪队列中新的队首进程,同时也让它执行一个时间片。这样就可以保证就绪队列中的所有进程在一给定的时间内均能获得一时间片的处理机执行时间。换言 之,系统能在给定的时间内响应所有用户的请求。
时间片轮转算法(RR,Round-Robin)
该算法采用剥夺策略。时间片轮转调度是一种最古老,最简单,最公平且使用最广的算法,又称RR调度。每个进程被分配一个时间段,称作它的时间片,即该进程允许运行的时间。
算法原理:让就绪进程以FCFS 的方式按时间片轮流使用CPU 的调度方式,即将系统中所有的就绪进程按照FCFS 原则,排成一个队列,每次调度时将CPU 分派给队首进程,让其执行一个时间片,时间片的长度从几个ms 到几百ms。在一个时间片结束时,发生时钟中断,调度程序据此暂停当前进程的执行,将其送到就绪队列的末尾,并通过上下文切换执行当前的队首进程,进程可以未使用完一个时间片,就出让CPU(如阻塞)。
算法优点:时间片轮转调度算法的特点是简单易行、平均响应时间短。
算法缺点:不利于处理紧急作业。在时间片轮转算法中,时间片的大小对系统性能的影响很大,因此时间片的大小应选择恰当
怎样确定时间片的大小:时间片大小的确定
1.系统对响应时间的要求
2.就绪队列中进程的数目
3.系统的处理能力2)多级反馈队列调度算法
前面介绍的各种用作进程调度的算法都有一定的局限性。如短进程优先的调度算法,仅照顾了短进程而忽略了长进程,而且如果并未指明进程的长度,则短进程优先和基于进程长度的抢占式调度算法都将无法 使用。而多级反馈队列调度算法则不必事先知道各种进程所需的执行时间,而且还可以满足各种类型进程的需要,因而它是目前被公认的一种较好的进程调度算法。 在采用多级反馈队列调度算法的系统中,调度算法的实施过程如下所述。
(1) 应设置多个就绪队列,并为各个队列赋予不同的优先级。第一个队列的优先级最高,第二个队列次之,其余各队列的优先权逐个降低。该算法赋予各个队列中进程执 行时间片的大小也各不相同,在优先权愈高的队列中,为每个进程所规定的执行时间片就愈小。例如,第二个队列的时间片要比第一个队列的时间片长一倍,……, 第i+1个队列的时间片要比第i个队列的时间片长一倍。
(2) 当一个新进程进入内存后,首先将它放入第一队列的末尾,按FCFS原则排队等待调度。当轮到该进程执行时,如它能在该时间片内完成,便可准备撤离系统;如 果它在一个时间片结束时尚未完成,调度程序便将该进程转入第二队列的末尾,再同样地按FCFS原则等待调度执行;如果它在第二队列中运行一个时间片后仍未 完成,再依次将它放入第三队列,……,如此下去,当一个长作业(进程)从第一队列依次降到第n队列后,在第n 队列便采取按时间片轮转的方式运行。
(3) 仅当第一队列空闲时,调度程序才调度第二队列中的进程运行;仅当第1~(i-1)队列均空时,才会调度第i队列中的进程运行。如果处理机正在第i队列中为 某进程服务时,又有新进程进入优先权较高的队列(第1~(i-1)中的任何一个队列),则此时新进程将抢占正在运行进程的处理机,即由调度程序把正在运行 的进程放回到第i队列的末尾,把处理机分配给新到的高优先权进程。
多级反馈队列(Multilevel Feedback Queue)
多级反馈队列调度算法是一种CPU处理机调度算法,UNIX操作系统采取的便是这种调度算法。
多级反馈队列调度算法描述:
1、进程在进入待调度的队列等待时,首先进入优先级最高的Q1等待。
2、首先调度优先级高的队列中的进程。若高优先级中队列中已没有调度的进程,则调度次优先级队列中的进程。例如:Q1,Q2,Q3三个队列,只有在Q1中没有进程等待时才去调度Q2,同理,只有Q1,Q2都为空时才会去调度Q3。
3、对于同一个队列中的各个进程,按照时间片轮转法调度。比如Q1队列的时间片为N,那么Q1中的作业在经历了N个时间片后若还没有完成,则进入Q2队列等待,若Q2的时间片用完后作业还不能完成,一直进入下一级队列,直至完成。
4、在低优先级的队列中的进程在运行时,又有新到达的作业,那么在运行完这个时间片后,CPU马上分配给新到达的作业(抢占式)。
在多级反馈队列调度算法中,如果规定第一个队列的时间片略大于多数人机交互所需之处理时间时,便能够较好的满足各种类型用户的需要。
2.task_struct结构体内容
(1)Linux下描述进程的结构体叫做task_struct.(很重要)。
(2)作用:用来存放进程的信息,会被装载到RAM中
(3)其中一些重要字段的含义
- 标识符:与进程相关的唯一标识符,用来区别正在执行的进程和其他进程。
- 状态:描述进程的状态,因为进程有挂起,阻塞,运行等好几个状态,所以都有个标识符来记录进程的执行状态。
- 优先级:如果有好几个进程正在执行,就涉及到进程被执行的先后顺序的问题,这和进程优先级这个标识符有关。
- 程序计数器:程序中即将被执行的下一条指令的地址。
- 内存指针:程序代码和进程相关数据的指针。
- 上下文数据:进程执行时处理器的寄存器中的数据。
- I/O状态信息:包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表等。
- 记账信息:包括处理器的时间总和,记账号等等。
(1)进程的状态
volatile long state;
state的可能取值为:
#define TASK_RUNNING 0//进程要么正在执行,要么准备执行
#define TASK_INTERRUPTIBLE 1 //可中断的睡眠,可以通过一个信号唤醒
#define TASK_UNINTERRUPTIBLE 2 //不可中断睡眠,不可以通过信号进行唤醒
#define __TASK_STOPPED 4 //进程停止执行
#define __TASK_TRACED 8 //进程被追踪
/* in tsk->exit_state */
#define EXIT_ZOMBIE 16 //僵尸状态的进程,表示进程被终止,但是父进程还没有获取它的终止信息,比如进程有没有执行完等信息。
#define EXIT_DEAD 32 //进程的最终状态,进程死亡
/* in tsk->state again */
#define TASK_DEAD 64 //死亡
#define TASK_WAKEKILL 128 //唤醒并杀死的进程
#define TASK_WAKING 256 //唤醒进程
(2)进程的唯一标识(pid)
pid_t pid;//进程的唯一标识
pid_t tgid;// 线程组的领头线程的pid成员的值
(3)进程标记符(flags)
unsigned int flags
/*
* Per process flags
*/
#define PF_EXITING 0x00000004 /* getting shut down */
#define PF_EXITPIDONE 0x00000008 /* pi exit done on shut down */
#define PF_VCPU 0x00000010 /* I'm a virtual CPU */
#define PF_WQ_WORKER 0x00000020 /* I'm a workqueue worker */
#define PF_FORKNOEXEC 0x00000040 /* forked but didn't exec */
#define PF_MCE_PROCESS 0x00000080 /* process policy on mce errors */
#define PF_SUPERPRIV 0x00000100 /* used super-user privileges */
#define PF_DUMPCORE 0x00000200 /* dumped core */
#define PF_SIGNALED 0x00000400 /* killed by a signal */
#define PF_MEMALLOC 0x00000800 /* Allocating memory */
#define PF_NPROC_EXCEEDED 0x00001000 /* set_user noticed that RLIMIT_NPROC was exceeded */
#define PF_USED_MATH 0x00002000 /* if unset the fpu must be initialized before use */
#define PF_USED_ASYNC 0x00004000 /* used async_schedule*(), used by module init */
#define PF_NOFREEZE 0x00008000 /* this thread should not be frozen */
#define PF_FROZEN 0x00010000 /* frozen for system suspend */
#define PF_FSTRANS 0x00020000 /* inside a filesystem transaction */
#define PF_KSWAPD 0x00040000 /* I am kswapd */
#define PF_MEMALLOC_NOIO 0x00080000 /* Allocating memory without IO involved */
#define PF_LESS_THROTTLE 0x00100000 /* Throttle me less: I clean memory */
#define PF_KTHREAD 0x00200000 /* I am a kernel thread */
#define PF_RANDOMIZE 0x00400000 /* randomize virtual address space */
#define PF_SWAPWRITE 0x00800000 /* Allowed to write to swap */
#define PF_NO_SETAFFINITY 0x04000000 /* Userland is not allowed to meddle with cpus_allowed */
#define PF_MCE_EARLY 0x08000000 /* Early kill for mce process policy */
#define PF_MUTEX_TESTER 0x20000000 /* Thread belongs to the rt mutex tester */
#define PF_FREEZER_SKIP 0x40000000 /* Freezer should not count it as freezable */
#define PF_SUSPEND_TASK 0x80000000 /* this thread called freeze_processes and should not be frozen
---------------------
本文来自 _stark 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/bit_clearoff/article/details/54292300?utm_source=copy 几种常用的状态
PF_FORKNOEXEC 表示进程刚被创建,但还没有执行 PF_SUPERPRIV 表示进程拥有超级用户特权 PF_SIGNALED 表示进程被信号杀出 PF_EXITING 表示进程开始关闭
(4)进程之间的亲属关系
struct task_struct *real_parent; /* real parent process */
struct task_struct *parent; /* recipient of SIGCHLD, wait4() reports */
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
struct task_struct *group_leader; /* threadgroup leader */
| 成员 | 描述 |
|---|---|
| real_parent | 指向当前操作系统执行进程的父进程,如果父进程不存在,指向pid为1的init进程 |
| parent | 指向当前进程的父进程,当当前进程终止时,需要向它发送wait4()的信号 |
| children | 位于链表的头部,链表的所有元素都是children的子进程 |
| group_leader | 指向进程组的领头进程 |
(5)进程调度信息
int prio, static_prio, normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
unsigned int policy;
policy表示进程的调度策略,目前主要有以下五种:
#define SCHED_NORMAL 0//按照优先级进行调度(有些地方也说是CFS调度器)
#define SCHED_FIFO 1//先进先出的调度算法
#define SCHED_RR 2//时间片轮转的调度算法
#define SCHED_BATCH 3//用于非交互的处理机消耗型的进程
#define SCHED_IDLE 5//系统负载很低时的调度算法
#define SCHED_RESET_ON_FORK 0x40000000
(6) 时间数据成员
关于时间,一个进程从创建到终止叫做该进程的生存期,进程在其生存期内使用CPU时间,内核都需要进行记录,进程耗费的时间分为两部分,一部分是用户模式下耗费的时间,一部分是在系统模式下耗费的时间。
cputime_t utime, stime, utimescaled, stimescaled;
cputime_t gtime;
cputime_t prev_utime, prev_stime;//记录当前的运行时间(用户态和内核态)
unsigned long nvcsw, nivcsw; //自愿/非自愿上下文切换计数
struct timespec start_time; //进程的开始执行时间
struct timespec real_start_time; //进程真正的开始执行时间
unsigned long min_flt, maj_flt;
struct task_cputime cputime_expires;//cpu执行的有效时间
struct list_head cpu_timers[3];//用来统计进程或进程组被处理器追踪的时间
struct list_head run_list;
unsigned long timeout;//当前已使用的时间(与开始时间的差值)
unsigned int time_slice;//进程的时间片的大小
int nr_cpus_allowed;
(7)信号处理信息
struct signal_struct *signal;//指向进程信号描述符
struct sighand_struct *sighand;//指向进程信号处理程序描述符
sigset_t blocked, real_blocked;//阻塞信号的掩码
sigset_t saved_sigmask; /* restored if set_restore_sigmask() was used */
struct sigpending pending;//进程上还需要处理的信号
unsigned long sas_ss_sp;//信号处理程序备用堆栈的地址
size_t sas_ss_size;//信号处理程序的堆栈的地址
(8)文件系统信息
/* filesystem information */
struct fs_struct *fs;//文件系统的信息的指针
/* open file information */
struct files_struct *files;//打开文件的信息指针
3.僵尸进程和孤儿进程
//僵尸进程:父进程没有接收到子进程的退出信息,没法回收子进程所占用的空间,子进程就会进入Z状态 /*Z-proc*/ 1#include2 #include 3 int main() 4 { 5 pid_t id=fork(); 6 if(id>0) { 7 //parent 8 printf("i am parent ,id:[%d]\n",getpid()); 9 sleep(30); 10 } 11 else{ 12 printf("i am child ,id:[%d]\n",getpid()); //child 13 sleep(3); 14 exit(0); 15 } 16 return 0; 17 } //孤儿进程:子进程还在运行,而父进程已经退出,这时子进程就成了孤儿。 //孤儿进程最后会被1号(init)进程领养 1 #include 2 #include 3 int main() 4 { 5 pid_t id = fork(); 6 if(id>0){ 7 //parent 8 printf("i am parent,id=%d\n",getpid()); 9 sleep(30); 10 } 11 else{ 12 //child 13 printf("i am child,id=%d\n",getpid()); 14 sleep(5); 15 exit(0); 16 } 17 return 0; 18 }
4.虚拟地址空间
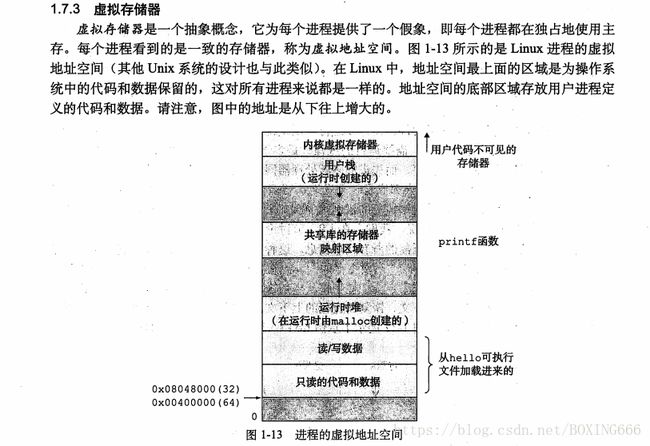

5.进程

(1)进程创建
linux下只有一个系统调用函数:fork ,用来创建一个新的进程
#include
pid_t fork(void);
返回值:子进程返回0,父进程返回子进程的id,错误返回-1 fork之前,父进程独立执行;fork之后,父子两个执行流分别执行。谁先执行完全由调度器决定
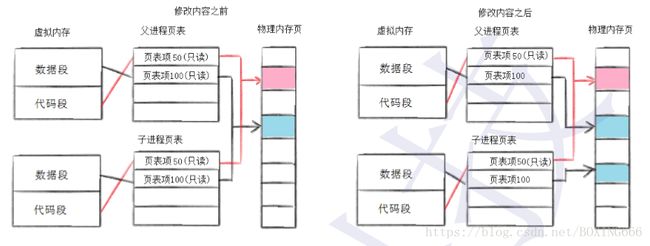
写时拷贝
通常,父子代码共享,父子不再写入时,数据也是共享的。当任意一方试图写入时,便以写时拷贝的方式各自拥有一份副本。
fork的常规用法
1】父进程等待客户端请求,生成子进程处理请求
2】一个进程要执行不同的程序,就要调用exec函数
fork调用失败的原因
1】系统中有太多进程
2】实际用户的进程数超过限制
vfork函数
创建子进程并保证子进程先运行,在它调用exec或(exit)后父进程才可能被调度
(2)进程终止
3种可能:1】代码运行完毕,结果正确 //只有一种可能,返回码为0;
2】代码运行完毕,结果不正确 //有多种可能原因,返回非0值;
3】代码异常终止
3种退出方法:1】从main函数return 退出码;
2】exit(退出码)并且刷新输出缓冲区;
3】_exit(退出码)不会刷新
(3)进程等待
父进程通过进,回收子进程资源,获取子进程退出信息。
2种方法:
1】wait方法
#include
#include
pid_t wait(int* status);
成功返回被等待进程的pid,失败返回-1.
参数:输出型参数,获取子进程的退出状态,(由操作系统填上) 注意:若有多个子进程,wait等待其中任意退出的一个子进程。
2】waitpid方法
pid_t waitpid(pid_t pid,int* status,int options);
返回值:
当正常返回的时候,waitpid收到子进程的id;
如果设置了选项WNOHANG,而调用waitpid发现没有已退出的子进程可以收集,则返回0;
如果调用出错,返回-1;
参数:
pid=-1.等待任意一个子进程,与wait等效;
pid>0,等待其进程id与pid相等的子进程;
status:
拿出子进程的退出信息;
WIFEXITED(status):若子进程正常终止,则为真(非零),即没有收到信号;
WEXITSTATUS(status):若WIFEXITED非零,提取子进程的退出码;
options:
若pid指定的进程还没有结束,则waitpid()函数返回0,不予等待。若正常结束,则返回子进程的id.
-如果子进程已经退出,调用wait/waitpid时,它们会立即返回,调用成功,释放子进程资源,获得子进程退出信息。
-如果在任意时刻调用wait/waitpid,子进程存在且正在运行,则进程可能阻塞。
-如果子进程不存在,则立即出错返回。
获取子进程status

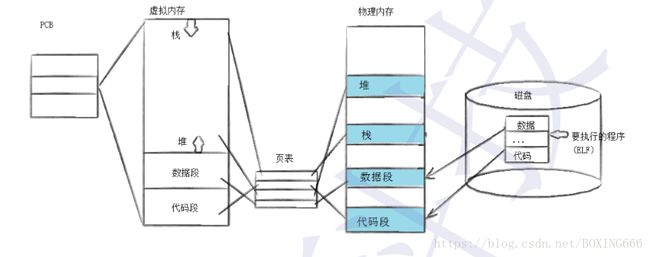
(3)进程的程序替换
原理:用fork创建子进程后,子进程要调用一种exec函数去执行另一个程序。进程调用一种exec函数时,该进程的用户空间代码和数据完全被新程序取代,从新程序的启动例程开始执行。但并不会创建新的进程,所以进程的id不会变。
替换函数
#include
int execl(const char *path,const char* arg, ...);
int execlp(const char *file,const char *arg, ...);
int execle(const char *path,const char *arg, ...,char *const envp[]);
int execv(const char *path,char *const argv[]);
int execvp(const char *file,char *const argv[]);
int execve(const char *path,char *const argv[],char *const envp[]); 函数解释
-这些函数调用成功的话,就会加载新的程序从启动代码开始执行,不再返回。
-出错返回-1。
-exec只有出错返回值,没有成功返回值

只有execve是真正的系统调用,其它5个函数最终都调用execve