计算机网络-高频面试题详细总结
目录
- 1. 简要介绍浏览器中输入一个URL,到显示页面的过程?
- 2. 简述TCP和UDP的区别?
- 3. 简要介绍TCP三次握手和四次挥手的全过程?
- 4. 为什么需要三次握手/四次挥手?
- 5. 二次握手行吗?三次挥手行吗?
- 6. TCP怎么保证数据传输的可靠性?
- 7. 简述OSI七层模型的功能?
- 8. 简要介绍HTTP和HTTPS,他们有什么区别?
- 9. HTTP1.1相比HTTP1.0,有什么主要变化?
- 10. HTTP协议包含哪些请求?
- 11. GET请求和POST请求的区别?
- 12. HTTP状态码有哪几类?并介绍下常见的状态码?
- 13. 常见的端口和对应的服务?
- 14. 简述TCP/IP四层模型的功能?
- 15. 有哪些私有/保留IP地址
- 16. 简要介绍常见的网络攻击?
- 17. URI和URL的区别?
1. 简要介绍浏览器中输入一个URL,到显示页面的过程?
- 浏览器会通过DNS服务器找输入的域名对应的IP地址。准备将向目标IP发送HTTP请求。
- 传输层将HTTP请求报文切分为报文段,并封装TCP头(包括原端口和目标端口)。
- 网络层将报文段添加IP头(包括原IP地址和目标IP地址)。
- 数据链路层使用ARP广播找局域网内有无对应的IP地址,如果没有,就将网关的MAC地址封装到帧头部。并将数据帧发送到网关路由器中。
- 当数据到达路由器时,进入输入端口,然后进入交换结构,根据转发表选择下一跳IP地址,并重写目标MAC地址,从一个输出端口输出。之后的路由选择和转发操作都是类似的。
- 直到报文送到了服务器,服务器给出响应并以同样的过程送达主机,主机一层一层拆除头部,并将HTML报文体显示在浏览器中。
2. 简述TCP和UDP的区别?
- TCP是面向连接的,即TCP传输数据之前需要建立连接,传输完毕需要释放连接。而UDP不需要建立连接。
- TCP是可靠传输协议,能提供差错检测,重传,流量控制等功能,而UDP不保证可靠传输。
- TCP消耗更多的资源,传输速度慢,UDP相对较快,所以一些即时通讯软件使用UDP效果更好。
- TCP传输单位称为报文段,UDP传输单位是数据报。
3. 简要介绍TCP三次握手和四次挥手的全过程?
三次握手
- 第一次握手,客户端给服务器发送一个SYN包,序号为x,等待服务器的响应。
- 第二次握手,服务器给客户端发送了有ACK/SYN标志的包,序号为y,确认号为x+1,并等待客户端响应。
- 第三次握手,客户端收到服务器的确认包后,给服务器发送了一个ACK包,序号为x+1,确认号为y+1。
三次握手完毕后,就可以正式传递数据了。
四次挥手
- 第一次挥手,客户端给服务器发送一个FIN包,此时客户端不会再向服务器发送数据,但客户端能接收服务器的数据。
- 第二次挥手,当服务器收到FIN包后,会给客户端发一个确认包,并传递剩下的数据。
- 第三次挥手,当服务器将剩余数据发送完后,就向发送方发一个FIN包。此时服务器也不会继续向客户端发送数据了。
- 第四次挥手,客户端收到服务器的FIN包后,就向服务器发送一个确认包。
服务端接收到后,完成四次挥手。服务器断开连接,客户端在等待一段时间后也断开连接。
4. 为什么需要三次握手/四次挥手?
三次握手的目的是建立可靠的通信信道,无论是客户端,还是服务器都需要确保自己和对方的发送/接收功能都是正常的,三次握手的过程就能保证这一点。
-
第一次握手,服务器收到客户端发来的同步包后,能确定客户端的发送功能和自己的接收功能是正常的。
-
第二次握手,客户端收到服务器发来的确认包后,能确定自己的发送/接收功能,服务器的发送/接收功能是正常的。
-
第三次握手,服务器收到客户端的确认包后,能确定自己的发送/接收功能,服务器的发送/接收功能是正常的。
如果不进行挥手操作,比如客户端直接断开与服务器的连接,那么服务器不知情,还会继续向客户端发送数据,这就造成资源浪费。
5. 二次握手行吗?三次挥手行吗?
二次握手不行,假设客户端的一个SYN包在网络中滞留了很久,这就是个失效的报文段了,如果服务器收到这个报文段,就认为这是一个连接请求,并建立连接。这样,就会浪费服务器资源,采用三次握手就能避免这种情况。
三次挥手不行,如果没有最后一次挥手,即服务器在第三次挥手,即发送完FIN包后就断开连接,如果这个包丢失了,那么客户端就会一直等待,这显然是不行的。
6. TCP怎么保证数据传输的可靠性?
- 首部校验和,提供了差错检测功能。
- 确认与序号机制,能保证接收到数据的有序性。
- 超时重传,能解决丢包问题。
- 流量控制,能控制端到端之间的数据传递速率,有效避免丢包。
- 拥塞控制,根据整个网络环境来条件传输速率,有效避免丢包。
7. 简述OSI七层模型的功能?
- 物理层:确定机械特性、电气特性、接口特性,通过媒介传输比特流。
- 数据链路层:将数据封装成帧,在链路中保证无差错传输。
- 网络层:实现数据报的路由选择和转发。
- 传输层:负责端到端的数据传输,提供差错检测、重传和流量控制机制。
- 会话层:建立、管理和终止会话。
- 表示层:数据的格式转换,如加密,压缩。
- 应用层:负责处理应用程序逻辑,直接向用户提供服务。
8. 简要介绍HTTP和HTTPS,他们有什么区别?
HTTP用于在Web浏览器和服务器之间传递数据,HTTP以明文的方式发送数据,不提供任何的加密手段。所以数据容易被窃取、篡改。
为了解决这个缺陷,于是有了HTTP+SSL组成的HTTPS协议,能通过SSL加密数据包,能够实现客户端到服务器之间的加密通信。
这个加密和解密过程需要使用密钥来实现,密钥加密方法有两种,共享密钥和公私密钥。共享密钥就是双方使用同一个密钥,但共享密钥在传递时容易被窃取,这样第三方就能使用这个密钥来解密了。所以后来就出现了公私密钥的加密方法,公钥在传递过程中不担心被窃取。同时,公钥需要对应的证书来保证其有效性。
这样,HTTPS在传递数据前就需要做一些额外的操作,如确认证书、协商密钥。传递数据过程中需要加密发送的数据和解密收到的数据。所以时间更慢,资源消耗更大。
总结一下,它们的区别是:
- HTTP明文传输,安全性较差。HTTPS使用SSL加密传输,安全性较好。
- HTTPS需要申请证书,需要花费一定费用。
- HTTP消耗更少的资源,页面响应速度更快,通常只需要3次握手建立连接。HTTPS还要加上SSL握手的9个包。
- HTTP的端口是80,HTTPS端口是443。
9. HTTP1.1相比HTTP1.0,有什么主要变化?
-
HTTP1.1 默认支持长连接,HTTP1.0需要使用keep-alive参数来建立长连接。
这是因为TCP连接建立和销毁的过程比较耗时,如果每次请求资源都新开TCP连接,对性能有很大影响。
-
带宽优化,支持断点续传。例如客户端下载了一部分大文件后网络中断,恢复后能向服务器请求指定内容,而不是全部重新下载。
-
新增了多个状态码,和HOST头域
10. HTTP协议包含哪些请求?
- GET:对服务器资源的简单请求
- POST:用于发送包含用户提交数据的请求
- PUT:用来传输文件,但是不带有验证机制,任何人都可以上传,有安全隐患。除了REST风格API会发送这种请求,一般的网站不会使用该方法
- DELETE:发出一个删除指定文档的请求,和PUT一样,有安全隐患,除了REST API一般不会发送这种请求。
- HEAD:和 GET 方法一样,只是不返回报文主体部分,只返回报头。通常用来检验url的有效性或资源更新日期。
- OPTIONS:查询服务器对给定url支持的所有请求方法
- TRACE:查询发送出去的请求是怎样被加工修改的。
- CONNECT:要求与代理服务器通信时建立隧道。使用加密协议如SSL来进行TCP通信。
11. GET请求和POST请求的区别?
最直观的区别就是GET请求把参数放到URL中,POST放到请求体中。
第二个就是参数的大小,GET传输数据的大小是2kb,而POST一般没有限制。
再就是安全性的问题,GET请求的参数在URL中,比较直观,不安全。POST请求参数在请求体内,相对安全。
12. HTTP状态码有哪几类?并介绍下常见的状态码?

200:请求成功状态码。
301:永久重定向。该资源已经分配了新的 URI,服务器返回301响应时,会自动将请求者转移到新URI。
302:临时重定向。表示请求的资源临时分配了新的 URI,希望用户(本次)能使用新的 URI 访问。
404:服务器找不到目标资源。
500:服务器内部出错,无法完成请求。
13. 常见的端口和对应的服务?
| 服务 | 端口号 |
|---|---|
| SSH | 22 |
| FTP | 20/21 |
| Tomcat | 8080 |
| MySQL | 3306 |
| Redis | 6379 |
| DNS | 53 |
| HTTP | 80 |
| HTTPS | 443 |
| SMTP | 25 |
14. 简述TCP/IP四层模型的功能?
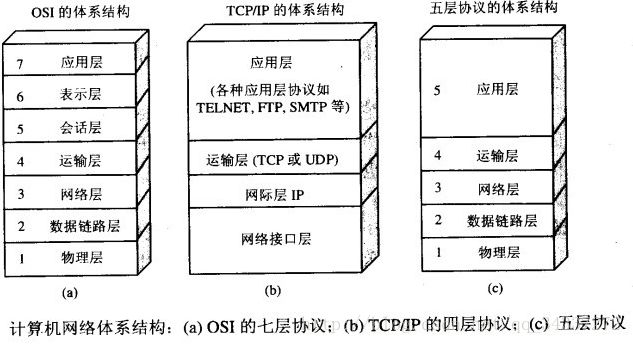
- 网络接口层:实现了网络接口程序,能处理数据在物理媒介中的传输。
- 网络层:实现数据报的路由选择和转发。
- 传输层:为两台主机提供端到端的通信,提供差错检测、重传和流量控制机制。
- 应用层:负责处理应用程序逻辑,直接向用户提供服务。
15. 有哪些私有/保留IP地址
A类:10.0.0.0 ~ 10.255.255.255
B类:172.16.0.0 ~ 172.31.255.255
C类:192.168.0.0 ~ 192.168.255.255
16. 简要介绍常见的网络攻击?
-
SQL注入
将SQL语句插入到web表单中或URL中,来让服务器执行恶意SQL语句。
解决方法是,使用参数化的SQL,不要使用拼装SQL;可以通过正则表达式对用户的输入进行校验;可以将单引号和双横杠(注释符)进行转换。
-
XSS(跨站脚本攻击)
客户端输入的恶意JavaScript代码被植入到HTML代码中,并得以执行。例如重定向到其他网站,或盗取用户cookie信息。
解决方法是,将用户提交的
<和>转义成<,>。开启cookie的HttpOnly属性。 -
CSRF(跨站请求伪造)
就是攻击者可以利用我的名义,来完成某些操作,而且对于服务器来说,这些操作都是合法的。
例如我登录了一个银行网站A,我转账给我一个朋友,服务器验证Cookie,这个操作是合法的。但是攻击者通过广告等形式引导我进去某个网站,在页面加载时就发送了一个转账到黑客的请求,此时请求携带的Cookie是我自己的,所以服务器也认为这个操作是合法的。这样,攻击者就通过我的身份来执行转账操作。
解决方法是,提交请求时携带Token,每次都是一个合法的随机数,并保证它的私密性;判断HTTP头的Referer字段,来确定这个请求是不是对应网页发出的。
17. URI和URL的区别?
URI指的是在某一规则下能把一个资源独一无二的标识出来。URL是提供某一资源的路径。
比如张三的身份证号是123456.
那么这个身份证号就是一个URI的实例,代表着张三这个人。
而URL是指向这个人的某一路径,比如:动物住址协议://地球/中国/浙江省/杭州市/西湖区/某大学/14号宿舍楼/525号寝/张三.人
这样也能代表张三这个人,所以URL是URI的子集。