语音信号处理常识【摘抄|自用】
摘抄自:https://zhuanlan.zhihu.com/p/31193859?utm_source=qq&utm_medium=social【笔记|自用】
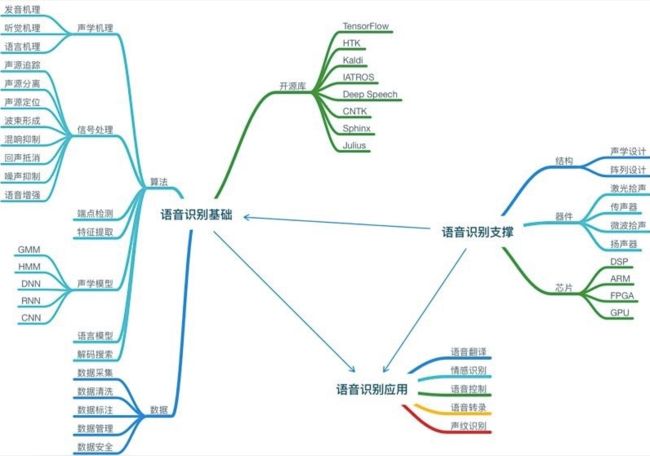
专业基础
算法基础
声学机理:
包括发音机理、听觉机理和语言机理,发音机理主要探讨人类发声器官和这些器官在发声过程中的作用,而听觉机理主要探讨人类听觉器官、听觉神经及其辨别处理声音的方式,语言机理主要探究人类语言的分布和组织方式。这些知识对于理论突破和模型生成具有重要意义。
信号处理:【任务】
包括语音增强、噪声抑制、回声抵消、混响抑制、波束形成、声源定位、声源分离、声源追踪等。具体如下:
-
语音增强:这里是狭义定义,指自动增益或者阵列增益,主要是解决拾音距离的问题,自动增益一般会增加所有信号能量,而语音增强只增加有效语音信号的能量。
-
噪声抑制:语音识别不需要完全去除噪声,相对来说通话系统中则必须完全去除噪声。这里说的噪声一般指环境噪声,比如空调噪声,这类噪声通常不具有空间指向性,能量也不是特别大,不会掩盖正常的语音,只是影响了语音的清晰度和可懂度。这种方法不适合强噪声环境下的处理,但是足以应付日常场景的语音交互。
-
混响消除:混响消除的效果很大程度影响了语音识别的效果。一般来说,当声源停止发声后,声波在房间内要经过多次反射和吸收,似乎若干个声波混合持续一段时间,这种现象叫做混响。混响会严重影响语音信号处理,并且降低测向精度。
-
回声抵消:严格来说,这里不应该叫回声,应该叫“自噪声”。回声是混响的延伸概念,这两者的区别就是回声的时延更长。一般来说,超过100毫秒时延的混响,人类能够明显区分出,似乎一个声音同时出现了两次,就叫做回声。实际上,这里所指的是语音交互设备自己发出的声音,比如Echo音箱,当播放歌曲的时候若叫Alexa,这时候麦克风阵列实际上采集了正在播放的音乐和用户所叫的Alexa声音,显然语音识别无法识别这两类声音。回声抵消就是要去掉其中的音乐信息而只保留用户的人声,之所以叫回声抵消,只是延续大家的习惯,其实是不恰当的。
-
声源测向:这里没有用声源定位,测向和定位是不太一样的,而消费级麦克风阵列做到测向就可以,定位则需要更多的成本投入。声源测向的主要作用就是侦测到与之对话人类的声音以便后续的波束形成。声源测向可以基于能量方法,也可以基于谱估计,阵列也常用TDOA技术。声源测向一般在语音唤醒阶段实现,VAD技术其实就可以包含到这个范畴,也是未来功耗降低的关键因素。
-
波束形成:波束形成是通用的信号处理方法,这里是指将一定几何结构排列的麦克风阵列的各麦克风输出信号经过处理(例如加权、时延、求和等)形成空间指向性的方法。波束形成主要是抑制主瓣以外的声音干扰,这里也包括人声,比如几个人围绕Echo谈话的时候,Echo只会识别其中一个人的声音。
端点检测:
端点检测,英语是Voice ActivityDetection,简称VAD,主要作用是区分一段声音是有效的语音信号还是非语音信号。VAD是语音识别中检测句子之间停顿的主要方法,同时也是低功耗所需要考虑的重要因素。VAD通常都用信号处理的方法来做,之所以这里单独划分,因为现在VAD的作用其实更加重要,而且通常VAD也会基于机器学习的方法来做。
特征提取:
声学模型通常不能直接处理声音的原始数据,这就需要把时域的声音原始信号通过某类方法提取出固定的特征序列,然后将这些序列输入到声学模型。事实上深度学习训练的模型不会脱离物理的规律,只是把幅度、相位、频率以及各个维度的相关性进行了更多的特征提取。
声学模型:
声学模型是语音识别中最为关键的部分,是将声学和计算机学的知识进行整合,以特征提取部分生成的特征作为输入,并为可变长的特征序列生成声学模型分数。声学模型核心要解决特征向量的可变长问题和声音信号的多变性问题。事实上,每次所提到的语音识别进展,基本上都是指声学模型的进展。声学模型迭代这么多年,已经有很多模型,我们把每个阶段应用最为广泛的模型介绍一下,其实现在很多模型都是在混用,这样可以利用各个模型的优势,对于场景的适配更加鲁棒。
-
GMM,Gaussian Mixture Model,即高斯混合模型,是基于傅立叶频谱语音特征的统计模型,可以通过不断迭代优化求取GMM中的加权系数及各个高斯函数的均值与方差。GMM模型训练速度较快,声学模型参数量小,适合离线终端应用。深度学习应用到语音识别之前,GMM-HMM混合模型一直都是优秀的语音识别模型。但是GMM不能有效对非线性或近似非线性的数据进行建模,很难利用语境的信息,扩展模型比较困难。
-
HMM,Hidden Markov Model,即隐马尔可夫模型,用来描述一个含有隐含未知参数的马尔可夫过程,从可观察的参数中确定该过程的隐含参数,然后利用这些参数来进一步分析。HMM是一种可以估计语音声学序列数据的统计学分布模型,尤其是时间特征,但是这些时间特征依赖于HMM的时间独立性假设,这样对语速、口音等因素与声学特征就很难关联起来。HMM还有很多扩展的模型,但是大部分还只适应于小词汇量的语音识别,大规模语音识别仍然非常困难。
-
DNN,Deep Neural Network,即深度神经网络,是较早用于声学模型的神经网络,DNN可以提高基于高斯混合模型的数据表示的效率,特别是DNN-HMM混合模型大幅度地提升了语音识别率。由于DNN-HMM只需要有限的训练成本便可得到较高的语音识别率,目前仍然是语音识别工业领域常用的声学模型。
-
RNN,Recurrent Neural Networks,即循环神经网络,CNN,Convolutional NeuralNetworks,即卷积神经网络,这两种神经网络在语音识别领域的应用,主要是解决如何利用可变长度语境信息的问题,CNN/RNN比DNN在语速鲁棒性方面表现的更好一些。其中,
-
-
RNN模型主要包括LSTM(多隐层长短时记忆网络)、highway LSTM、Residual LSTM、双向LSTM等。
-
CNN模型包括了时延神经网络(TDNN)、CNN-DNN、CNN-LSTM-DNN(CLDNN)、CNN-DNN-LSTM、Deep CNN等。其中有些模型性能相近,但是应用方式不同,比如双向LSTM和Deep CNN性能接近,但是双向LSTM需要等一句话结束才能识别,而Deep CNN则没有时延更适合实时语音识别。
-
语音识别数据知识
数据采集:主要是将用户与机器对话的声音信息收集起来,一般分为近场和远场两个部分,近场采集一般基于手机就可完成,远场采集一般需要麦克风阵列。数据采集同时还有关注采集环境,针对不同数据用途,语音采集的要求也很不一样,比如人群的年龄分布、性别分布和地域分布等。
数据清洗:主要是将采集的数据进行预处理,剔除不合要求的语音甚至是失效的语音,为后面的数据标注提供精确的数据。
数据标注:主要是将声音的信息翻译成对应的文字,训练一个声学模型,通常要标注数万个小时,而语音是时序信号,所以需要的人力工时相对很多,同时由于人员疲惫等因素导致标注的错误率也比较高。如何提高数据标注的成功率也是语音识别的关键问题。
数据管理:主要是对标注数据的分类管理和整理,这样更利于数据的有效管理和重复利用。
数据安全:主要是对声音数据进行安全方便的处理,比如加密等,以避免敏感信息泄露。
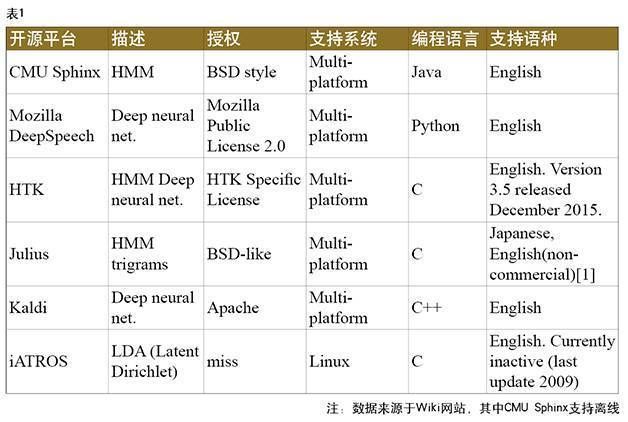
语音识别开源平台
目前主流的开源平台包括CMU Sphinx、HTK、Kaldi、Julius、iATROS、CNTK、TensorFlow等,CMU Sphinx是离线的语音识别工具,支持DSP等低功耗的离线应用场景。由于深度学习对于语音识别WER的下降具有明显的作用,所以Kaldi、CNTK、TensorFlow等支持深度学习的工具目前比较流行,Kaldi的优势就是集成了很多语音识别的工具,包括解码搜索等。具体的开源平台汇总如表1所示。