风格迁移
风格迁移
导语
本节学习来源斯坦福大学cs20课程,有关本节源代码已同步只至github,欢迎大家star与转发,收藏!
cs20是一门对于深度学习研究者学习Tensorflow的课程,今天学习第八节,非常有收获,并且陆续将内容写入jupytebook notebook中,有关这个源代码及仓库地址,大家可以点击阅读原文或者直接复制下面链接!
直通车:
今日日程
TFRecord
Getting to know each other!
Style Transfer
TFRecord
TFRecord是TensorFlow数据格式,以二进制格式存储。因此,有效地使用了磁盘缓存,并且使用速度快。因为它是二进制格式,所以它也可以处理其他类型的数据(图像和标签可以放在一起)。
让我们看看如何将图像和标签保存为TFRecord文件。
转换为TFRecord格式
第一步:创建一个写入TFRecord文件的编写器
import tensorflow as tf
writer = tf.python_io.TFRecordWriter(out_file)
第二步:获得序列化的形状和图像的值
shape, binary_image = get_image_binary(image_file)
第三步:创建一个tf.train.Features对象
features = tf.train.Features(feature={'label': _int64_feature(label),
'shape': _bytes_feature(shape),
'image': _bytes_feature(binary_image)})
第四步:创建包含上面定义的功能的示例
sample = tf.train.Example(features=features)
第五步:将示例写入tfrecord文件
writer.write(sample.SerializeToString())
第六步:关闭writer
writer.close()
如何保存为TFRecord文件已结束。上述存储过程具有以不同格式存储int和byte值的优点。
函数_int64_feature和_bytes_feature将上面使用的不同数据类型转换为一个字节字符串,定义如下。
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
读TFRecord数据
使用TFRecordDataset,现在让我们看看如何使用保存的TFRecord文件。它可以使用tf.data调用。
dataset = tf.data.TFRecordDataset(tfrecord_files)
您可以按上述方式调用它。但是让我们考虑何时保存。我不得不将不同的数据格式存储为一个数据。
因此,您必须在调用后划分另一种数据类型。因此,您可以使用_parse_function_,这是一个解析函数。
def _parse_function(tfrecord_serialized):
features={'label': tf.FixedLenFeature([], tf.int64),
'shape': tf.FixedLenFeature([], tf.string),
'image': tf.FixedLenFeature([], tf.string)}
然后,您可以将定义的函数应用于数据映射函数。
dataset = dataset.map(_parse_function)
风格迁移
风格转移是一种模型,其中使用两个图像将一个图像的样式应用于一个图像。
下图是Deadpool图片:

下图是Guernica图片:

如果将这两个图像应用于风格迁移模型,则可以将毕加索的Guernica图片样式应用于Deadpool图片。也就是说,它看起来如下图所示:

在该模型中定义了两个重要的损失。这里,内容图像是上述示例中的Deadpool图像,并且样式图像是毕加索的Guernica图像。
Content loss
内容测量图像内容与生成图像内容之间的内容丢失
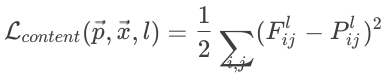
Style loss
图像风格与创建图像样式之间的样式丢失。
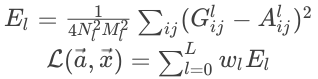
此模型的优化器可将两个损失最小化。

实现过程将描述如下。
学习输入值而不是权重。
使用相同的变量进行共享。
我们使用了预先训练过的模型(VGG-19)。
