python dlib学习(六):训练模型
前言
前面的博客都是使用dlib官方提供的训练好的模型,进行目标识别。
- python dlib学习(一):人脸检测
- python dlib学习(二):人脸特征点标定
- python dlib学习(三):调用cnn人脸检测
- python dlib学习(四):单目标跟踪
- python dlib学习(五):比对人脸
直接进入主题吧,这次我们要自己训练一个模型。使用dlib训练一个基于HOG的物体识别器。
准备数据集
首当其冲地就是数据集,这里提供一个很方便的工具imglab。
dlib官方源码中提供了这个工具,想要的可以去下载。
1. 在从github上下载的源码中,文件路径为:dlib/tools/imglab。
2. 这里我再提供一个下载链接,提取出了这个工具包供下载。http://download.csdn.net/download/hongbin_xu/10103900
(推荐到官网自行下载)
默认已经下载好了这个文件。
进入目录,输入以下指令:
mkdir build
cd build
cmake ..
cmake --build . --config Release
编译好了再:
sudo make install安装完成之后可以直接在console里使用imglab指令调用。
接下来使用imglab给数据集打标签。
我自己在网上收集了一些猫的照片,用于训练。打标签在猫的脸上,所以这里相当于对猫脸进行识别(笑)。数据集需要自己事先收集好,这里我用的数据集会在文章的最后附上,需要的请自行下载。
使用imglab先创建我们要用来记录标签的xml文件。
进入到当前目录下:
imglab -c mydata.xml ./mydata.xml:这个是xml文件的名字,随便取一个就是了
./:这个是你的数据集的目录,我是直接在数据集文件夹中创建的,所以直接指定当前文件夹
之后文件夹中会生成两个文件:一个xml文件,一个xsl文件。如下图所示:
接下来,打开这个xml文件:
imglab mydata.xml
随后会启动工具软件。
接下来一张一张图片打标签吧。
操作很简单,按下shift键后,鼠标左键拖动就会画出框;先松开左键,就会记录这个框,若先松开shift键,则不记录操作。
最后,打开你的xml文件,里面已经标注好了标签的信息:
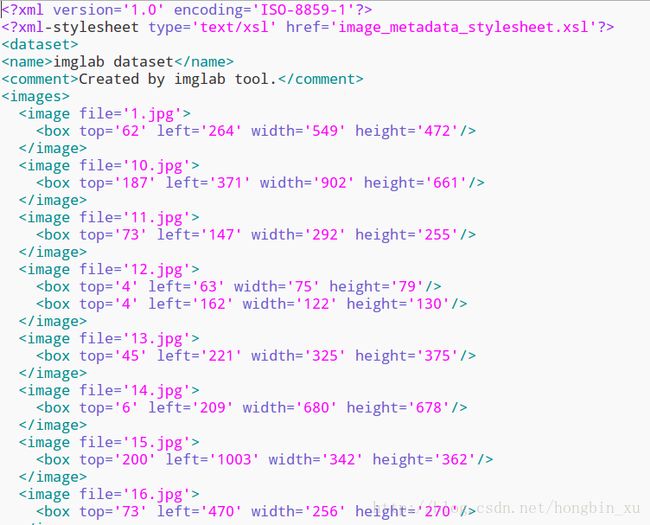
程序和结果
训练模型
# -*- coding: utf-8 -*-
import os
import sys
import glob
import dlib
import cv2
# options用于设置训练的参数和模式
options = dlib.simple_object_detector_training_options()
# Since faces are left/right symmetric we can tell the trainer to train a
# symmetric detector. This helps it get the most value out of the training
# data.
options.add_left_right_image_flips = True
# 支持向量机的C参数,通常默认取为5.自己适当更改参数以达到最好的效果
options.C = 5
# 线程数,你电脑有4核的话就填4
options.num_threads = 4
options.be_verbose = True
# 获取路径
current_path = os.getcwd()
train_folder = current_path + '/cats_train/'
test_folder = current_path + '/cats_test/'
train_xml_path = train_folder + 'cat.xml'
test_xml_path = test_folder + 'cats.xml'
print("training file path:" + train_xml_path)
# print(train_xml_path)
print("testing file path:" + test_xml_path)
# print(test_xml_path)
# 开始训练
print("start training:")
dlib.train_simple_object_detector(train_xml_path, 'detector.svm', options)
print("") # Print blank line to create gap from previous output
print("Training accuracy: {}".format(
dlib.test_simple_object_detector(train_xml_path, "detector.svm")))
print("Testing accuracy: {}".format(
dlib.test_simple_object_detector(test_xml_path, "detector.svm")))运行程序:
开始训练

接下来等待一小会儿,我用的数据集并不大,在我的笔记本上跑了没多久就好了。

可以看到准确率差不多7成。模型保存到了detector.svm中。
测试模型
# -*- coding: utf-8 -*-
import os
import sys
import dlib
import cv2
import glob
detector = dlib.simple_object_detector("detector.svm")
current_path = os.getcwd()
test_folder = current_path + '/cats_test/'
for f in glob.glob(test_folder+'*.jpg'):
print("Processing file: {}".format(f))
img = cv2.imread(f, cv2.IMREAD_COLOR)
b, g, r = cv2.split(img)
img2 = cv2.merge([r, g, b])
dets = detector(img2)
print("Number of faces detected: {}".format(len(dets)))
for index, face in enumerate(dets):
print('face {}; left {}; top {}; right {}; bottom {}'.format(index, face.left(), face.top(), face.right(), face.bottom()))
left = face.left()
top = face.top()
right = face.right()
bottom = face.bottom()
cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0), 3)
cv2.namedWindow(f, cv2.WINDOW_AUTOSIZE)
cv2.imshow(f, img)
k = cv2.waitKey(0)
cv2.destroyAllWindows()代码很简单,不做赘述。
识别的结果:
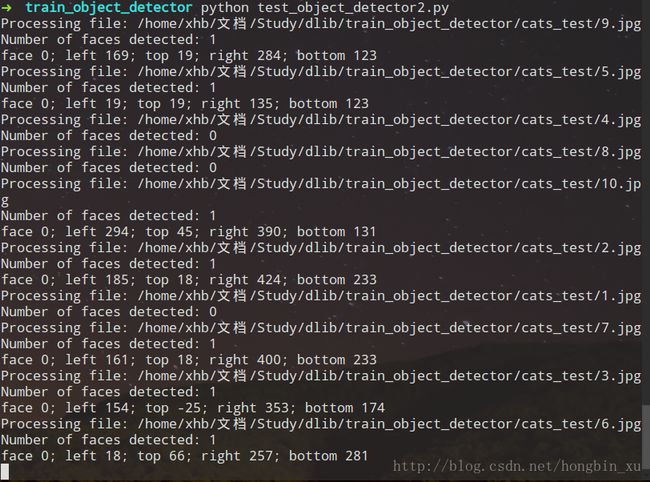
由于光照、角度等等的因素,训练结果还是需要改进的。我放的数据集很小,加大数据集可以一定程度上改进这个问题。
吐槽:
话说这个不应该叫做“猫”脸识别吗?
( ̄_ ̄ )
我用到的数据集下载链接:
http://download.csdn.net/download/hongbin_xu/10103946