java.nio.ByteBuffer 类 缓冲区
一.
Buffer 类
定义了一个可以线性存放primitive type数据的容器接口。Buffer主要包含了与类型(byte, char…)无关的功能。
值得注意的是Buffer及其子类都不是线程安全的。
每个Buffer都有以下的属性:
capacity
这个Buffer最多能放多少数据。capacity一般在buffer被创建的时候指定。
limit
在Buffer上进行的读写操作都不能越过这个下标。当写数据到buffer中时,limit一般和capacity相等,当读数据时,
limit代表buffer中有效数据的长度。
position
读/写操作的当前下标。当使用buffer的相对位置进行读/写操作时,读/写会从这个下标进行,并在操作完成后,
buffer会更新下标的值。
mark
一个临时存放的位置下标。调用mark()会将mark设为当前的position的值,以后调用reset()会将position属性设
置为mark的值。mark的值总是小于等于position的值,如果将position的值设的比mark小,当前的mark值会被抛弃掉。
这些属性总是满足以下条件:
0 <= mark <= position <= limit <= capacity
limit和position的值除了通过limit()和position()函数来设置,也可以通过下面这些函数来改变:
Buffer clear()
把position设为0,把limit设为capacity,一般在把数据写入Buffer前调用。
Buffer flip()
把limit设为当前position,把position设为0,一般在从Buffer读出数据前调用。
Buffer rewind()
把position设为0,limit不变,一般在把数据重写入Buffer前调用。
Buffer对象有可能是只读的,这时,任何对该对象的写操作都会触发一个ReadOnlyBufferException。
isReadOnly()方法可以用来判断一个Buffer是否只读。
ByteBuffer 类
在Buffer的子类中,ByteBuffer是一个地位较为特殊的类,因为在java.io.channels中定义的各种channel的IO
操作基本上都是围绕ByteBuffer展开的。
ByteBuffer定义了4个static方法来做创建工作:
ByteBuffer allocate(int capacity) //创建一个指定capacity的ByteBuffer。
ByteBuffer allocateDirect(int capacity) //创建一个direct的ByteBuffer,这样的ByteBuffer在参与IO操作时性能会更好
ByteBuffer wrap(byte [] array)
ByteBuffer wrap(byte [] array, int offset, int length) //把一个byte数组或byte数组的一部分包装成ByteBuffer。
ByteBuffer定义了一系列get和put操作来从中读写byte数据,如下面几个:
byte get()
ByteBuffer get(byte [] dst)
byte get(int index)
ByteBuffer put(byte b)
ByteBuffer put(byte [] src)
ByteBuffer put(int index, byte b)
这些操作可分为绝对定位和相对定为两种,相对定位的读写操作依靠position来定位Buffer中的位置,并在操
作完成后会更新position的值。在其它类型的buffer中,也定义了相同的函数来读写数据,唯一不同的就是一
些参数和返回值的类型。
除了读写byte类型数据的函数,ByteBuffer的一个特别之处是它还定义了读写其它primitive数据的方法,如:
int getInt() //从ByteBuffer中读出一个int值。
ByteBuffer putInt(int value) // 写入一个int值到ByteBuffer中。
读写其它类型的数据牵涉到字节序问题,ByteBuffer会按其字节序(大字节序或小字节序)写入或读出一个其它
类型的数据(int,long…)。字节序可以用order方法来取得和设置:
ByteOrder order() //返回ByteBuffer的字节序。
ByteBuffer order(ByteOrder bo) // 设置ByteBuffer的字节序。
ByteBuffer另一个特别的地方是可以在它的基础上得到其它类型的buffer。如:
CharBuffer asCharBuffer()
为当前的ByteBuffer创建一个CharBuffer的视图。在该视图buffer中的读写操作会按照ByteBuffer的字节
序作用到ByteBuffer中的数据上。
用这类方法创建出来的buffer会从ByteBuffer的position位置开始到limit位置结束,可以看作是这段数据
的视图。视图buffer的readOnly属性和direct属性与ByteBuffer的一致,而且也只有通过这种方法,才可
以得到其他数据类型的direct buffer。
ByteOrder
用来表示ByteBuffer字节序的类,可将其看成java中的enum类型。主要定义了下面几个static方法和属性:
ByteOrder BIG_ENDIAN 代表大字节序的ByteOrder。
ByteOrder LITTLE_ENDIAN 代表小字节序的ByteOrder。
ByteOrder nativeOrder() 返回当前硬件平台的字节序。
MappedByteBuffer
ByteBuffer的子类,是文件内容在内存中的映射。这个类的实例需要通过FileChannel的map()方法来创建。
写到标准输出:
public class ByteBufferTest {
public static void main(String[] args) throws IOException {
// 创建一个capacity为256的ByteBuffer
ByteBuffer buf = ByteBuffer.allocate(256);
while (true) {
// 从标准输入流读入一个字符
int c = System.in.read();
// 当读到输入流结束时,退出循环
if (c == -1)
break;
// 把读入的字符写入ByteBuffer中
buf.put((byte) c);
// 当读完一行时,输出收集的字符
if (c == '\n') {
// 调用flip()使limit变为当前的position的值,position变为0,
// 为接下来从ByteBuffer读取做准备
buf.flip();
// 构建一个byte数组
byte[] content = new byte[buf.limit()];
// 从ByteBuffer中读取数据到byte数组中
buf.get(content);
// 把byte数组的内容写到标准输出
System.out.print(new String(content));
// 调用clear()使position变为0,limit变为capacity的值,
// 为接下来写入数据到ByteBuffer中做准备
buf.clear();
}
}
}
}二.
类ByteBuffer是Java nio程序经常会用到的类,也是重要类 ,我们通过源码分析该类的实现原理。
一.ByteBuffer类的继承结构
public abstract class ByteBuffer
extends Buffer
implements Comparable
ByteBuffer的核心特性来自Buffer
二. ByteBuffer和Buffer的核心特性A container for data of a specific primitive type. 用于特定基本类型数据的容器。
子类ByteBuffer支持除boolean类型以外的全部基本数据类型。
本质上,Buffer也就是由装有特定基本类型数据的一块内存缓冲区和操作数据的4个指针变量(mark标记,position位置, limit界限,capacity容量)组成。不多说,上源码:
public abstract class Buffer {
// Invariants: mark <= position <= limit <= capacity
private int mark = -1;
private int position = 0;
private int limit;
private int capacity;
......
}
public abstract class ByteBuffer
extends Buffer
implements Comparable
{
// These fields are declared here rather than in Heap-X-Buffer in order to
// reduce the number of virtual method invocations needed to access these
// values, which is especially costly when coding small buffers.
//
final byte[] hb; // Non-null only for heap buffers
final int offset;
boolean isReadOnly; // Valid only for heap buffers
......
} 其中,字节数组final byte[] hb就是所指的那块内存缓冲区。
Buffer缓冲区的主要功能特性有:
a.Transferring data 数据传输,主要指可通过get()方法和put()方法向缓冲区存取数据,ByteBuffer提供存取除boolean以为的全部基本类型数据的方法。
b.Marking and resetting 做标记和重置,指mark()方法和reset()方法;而标记,无非是保存操作中某个时刻的索引位置。
c.Invariants 各种指针变量
d.Clearing, flipping, and rewinding 清除数据,位置(position)置0(界限limit为当前位置),位置(position)置0(界限limit不变),指clear()方法, flip()方法和rewind()方法。
e.Read-only buffers 只读缓冲区,指可将缓冲区设为只读。
f.Thread safety 关于线程安全,指该缓冲区不是线程安全的,若多线程操作该缓冲区,则应通过同步来控制对该缓冲区的访问。
g.Invocation chaining 调用链, 指该类的方法返回调用它们的缓冲区,因此,可将方法调用组成一个链;例如:
b.flip();
b.position(23);
b.limit(42);
等同于
b.flip().position(23).limit(42);
三.ByteBuffer的结构
ByteBuffer主要由是由装数据的内存缓冲区和操作数据的4个指针变量(mark标记,position位置, limit界限,capacity容量)组成。
内存缓冲区:字节数组final byte[] hb;
ByteBuffer的主要功能也是由这两部分配合实现的,如put()方法,就是向数组byte[] hb存放数据。
ByteBuffer bb = ByteBuffer.allocate(10);
// 向bb装入byte数据
bb.put((byte)9);
底层源码的实现如下
class HeapByteBuffer
extends ByteBuffer
{
......
public ByteBuffer put(byte x) {
hb[ix(nextPutIndex())] = x;
return this;
}
......
final int nextPutIndex() {
if (position >= limit)
throw new BufferOverflowException();
return position++;
}
......
}
如上所述,bb.put((byte)9);执行时,先判断position 是否超过 limit,否则指针position向前移一位,将字节(byte)9存入position所指byte[] hb索引位置。
get()方法相似;
public byte get() {
return hb[ix(nextGetIndex())];
}
4个指针的涵义
position:位置指针。微观上,指向底层字节数组byte[] hb的某个索引位置;宏观上,是ByteBuffer的操作位置,如get()完成后,position指向当前(取出)元素的下一位,put()方法执行完成后,position指向当前(存入)元素的下一位;它是核心位置指针。
mark标记:保存某个时刻的position指针的值,通过调用mark()实现;当mark被置为负值时,表示废弃标记。
capacity容量:表示ByteBuffer的总长度/总容量,也即底层字节数组byte[] hb的容量,一般不可变,用于读取。
limit界限:也是位置指针,表示待操作数据的界限,它总是和读取或存入操作相关联,limit指针可以被 改变,可以认为limit<=capacity。
ByteBuffer结构如下图所示 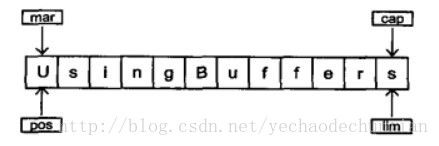
四. ByteBuffer的关键方法实现
1.取元素
public abstract byte get();
//HeapByteBuffer子类实现
public byte get() {
return hb[ix(nextGetIndex())];
}
//HeapByteBuffer子类方法
final int nextGetIndex() {
if (position >= limit)
throw new BufferUnderflowException();
return position++;
} 2.存元素
public abstract ByteBuffer put(byte b);
//HeapByteBuffer子类实现
public ByteBuffer put(byte x) {
hb[ix(nextPutIndex())] = x;
return this;
}
3.清除数据
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}
可见,对于clear()方法,ByteBuffer只是重置position指针和limit指针,废弃mark标记,并没有真正清空缓冲区/底层字节数组byte[] hb的数据;
ByteBuffer也没有提供真正清空缓冲区数据的接口,数据总是被覆盖而不是清空。
例如,对于Socket读操作,若从socket中read到数据后,需要从头开始存放到缓冲区,而不是从上次的位置开始继续/连续存放,则需要clear(),重置position指针,但此时需要注意,若read到的数据没有填满缓冲区,则socket的read完成后,不能使用array()方法取出缓冲区的数据,因为array()返回的是整个缓冲区的数据,而不是上次read到的数据。
4. 以字节数组形式返回整个缓冲区的数据/byte[] hb的数据
public final byte[] array() {
if (hb == null)
throw new UnsupportedOperationException();
if (isReadOnly)
throw new ReadOnlyBufferException();
return hb;
} 5.flip-位置重置
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
} socket的read操作完成后,若需要write刚才read到的数据,则需要在write执行前执行flip(),以重置操作位置指针,保存操作数据的界限,保证write数据准确。
6.rewind-位置重置
public final Buffer rewind() {
position = 0;
mark = -1;
return this;
} Rewinds this buffer. The position is set to zero and the mark is discarded.
和flip()相比较而言,没有执行limit = position;
7.判断剩余的操作数据或者剩余的操作空间
public final int remaining() {
return limit - position;
}
常用于判断socket的write操作中未写出的数据;
8.标记
public final Buffer mark() {
mark = position;
return this;
} 9.重置到标记
public final Buffer reset() {
int m = mark;
if (m < 0)
throw new InvalidMarkException();
position = m;
return this;
}
五.创建ByteBuffer对象的方式
1.allocate方式
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
HeapByteBuffer(int cap, int lim) { // package-private
super(-1, 0, lim, cap, new byte[cap], 0);
/*
hb = new byte[cap];
offset = 0;
*/
}
// Creates a new buffer with the given mark, position, limit, capacity,
// backing array, and array offset
//
ByteBuffer(int mark, int pos, int lim, int cap, // package-private
byte[] hb, int offset)
{
super(mark, pos, lim, cap);
this.hb = hb;
this.offset = offset;
}
// Creates a new buffer with the given mark, position, limit, and capacity,
// after checking invariants.
//
Buffer(int mark, int pos, int lim, int cap) { // package-private
if (cap < 0)
throw new IllegalArgumentException();
this.capacity = cap;
limit(lim);
position(pos);
if (mark >= 0) {
if (mark > pos)
throw new IllegalArgumentException();
this.mark = mark;
}
}
由此可见,allocate方式创建ByteBuffer对象的主要工作包括: 新建底层字节数组byte[] hb(长度为capacity),mark置为-1,position置为0,limit置为capacity,capacity为用户指定的长度。
2.wrap方式
public static ByteBuffer wrap(byte[] array) {
return wrap(array, 0, array.length);
}
public static ByteBuffer wrap(byte[] array,
int offset, int length)
{
try {
return new HeapByteBuffer(array, offset, length);
} catch (IllegalArgumentException x) {
throw new IndexOutOfBoundsException();
}
}
HeapByteBuffer(byte[] buf, int off, int len) { // package-private
super(-1, off, off + len, buf.length, buf, 0);
/*
hb = buf;
offset = 0;
*/
}
wrap方式和allocate方式本质相同,不过因为由用户指定的参数不同,参数为byte[] array,所以不需要新建字节数组,byte[] hb置为byte[] array,mark置为-1,position置为0,limit置为array.length,capacity置为array.length。
六、结论
由此可见,ByteBuffer的底层结构清晰,不复杂,源码仍是弄清原理的最佳文档。
读完此文,应该当Java nio的SocketChannel进行read或者write操作时,ByteBuffer的四个指针如何移动有了清晰的认识。