dlib 15 dlib自带demo 基于DNN的车辆检测
01 资源
代码:dlib\examples\dnn_mmod_find_cars_ex.cpp
工程名:dnn_mmod_find_cars_ex
测试图像文件:
dlib\examples\mmod_cars_test_image.jpg
从代码注释中可以获得model数据文件:
http://dlib.net/files/mmod_rear_end_vehicle_detector.dat.bz2
把上面获得的压缩包内容分别解压到Release/Debug目录下:
mmod_rear_end_vehicle_detector.dat
02 项目设置
把examples解决方案中的dnn_mmod_find_cars_ex工程设置为启动项。
如需调试,使用debug。使用release运行速度会快很多。
配置属性==>调试==>工作目录==>$(OutDir)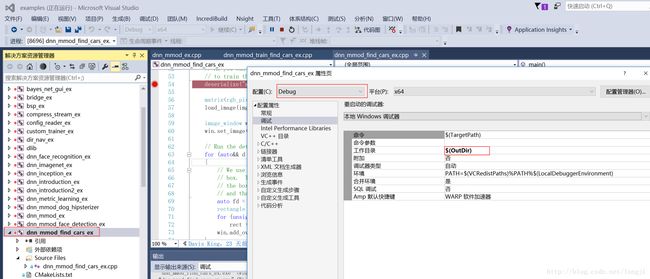
根据dnn_mmod_find_cars_ex.cpp代码所示
load_image(img, "../mmod_cars_test_image.jpg");,把dlib\examples\mmod_cars_test_image.jpg拷贝到D:\git\dlib\build\x64_19.6_examples目录下。
03 检测结果
# output window
Hit enter to view the intermediate processing steps
44
jet color mapping range: lower=-2.5 upper=0
Number of channels in final tensor image: 3
Hit enter to end program
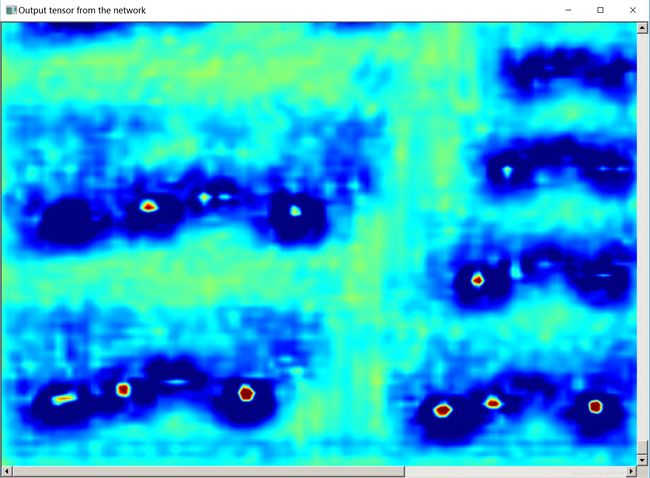

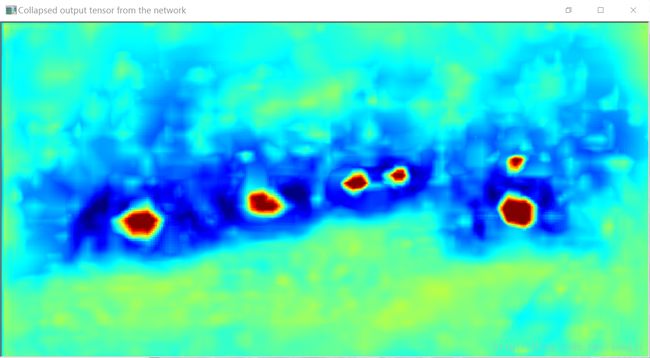

04 代码
dlib\examples\dnn_mmod_find_cars_ex.cpp
// The contents of this file are in the public domain. See LICENSE_FOR_EXAMPLE_PROGRAMS.txt
/*
This example shows how to run a CNN based vehicle detector using dlib. The
example loads a pretrained model and uses it to find the rear ends of cars in
an image. We will also visualize some of the detector's processing steps by
plotting various intermediate images on the screen. Viewing these can help
you understand how the detector works.
The model used by this example was trained by the dnn_mmod_train_find_cars_ex.cpp
example. Also, since this is a CNN, you really should use a GPU to get the
best execution speed. For instance, when run on a NVIDIA 1080ti, this
detector runs at 39fps when run on the provided test image. That's about an
order of magnitude faster than when run on the CPU.
Users who are just learning about dlib's deep learning API should read
the dnn_introduction_ex.cpp and dnn_introduction2_ex.cpp examples to learn
how the API works. For an introduction to the object detection method you
should read dnn_mmod_ex.cpp.
You can also see some videos of this vehicle detector running on YouTube:
https://www.youtube.com/watch?v=4B3bzmxMAZU
https://www.youtube.com/watch?v=bP2SUo5vSlc
*/
#include 5,5,2,2,SUBNET>;
template <long num_filters, typename SUBNET> using con5 = con5,5,1,1,SUBNET>;
template <typename SUBNET> using downsampler = relu32, relu32, relu16,SUBNET>>>>>>>>>;
template <typename SUBNET> using rcon5 = relu55,SUBNET>>>;
using net_type = loss_mmod1,9,9,1,1,rcon56>>>>>>>>;
// ----------------------------------------------------------------------------------------
int main() try
{
net_type net;
shape_predictor sp;
// You can get this file from http://dlib.net/files/mmod_rear_end_vehicle_detector.dat.bz2
// This network was produced by the dnn_mmod_train_find_cars_ex.cpp example program.
// As you can see, it also includes a shape_predictor. To see a generic example of how
// to train those refer to train_shape_predictor_ex.cpp.
deserialize("mmod_rear_end_vehicle_detector.dat") >> net >> sp;
matrix img;
load_image(img, "../mmod_cars_test_image.jpg");
image_window win;
win.set_image(img);
// Run the detector on the image and show us the output.
for (auto&& d : net(img))
{
// We use a shape_predictor to refine the exact shape and location of the detection
// box. This shape_predictor is trained to simply output the 4 corner points of
// the box. So all we do is make a rectangle that tightly contains those 4 points
// and that rectangle is our refined detection position.
auto fd = sp(img,d);
rectangle rect;
for (unsigned long j = 0; j < fd.num_parts(); ++j)
rect += fd.part(j);
win.add_overlay(rect, rgb_pixel(255,0,0));
}
cout << "Hit enter to view the intermediate processing steps" << endl;
cin.get();
// Now let's look at how the detector works. The high level processing steps look like:
// 1. Create an image pyramid and pack the pyramid into one big image. We call this
// image the "tiled pyramid".
// 2. Run the tiled pyramid image through the CNN. The CNN outputs a new image where
// bright pixels in the output image indicate the presence of cars.
// 3. Find pixels in the CNN's output image with a value > 0. Those locations are your
// preliminary car detections.
// 4. Perform non-maximum suppression on the preliminary detections to produce the
// final output.
//
// We will be plotting the images from steps 1 and 2 so you can visualize what's
// happening. For the CNN's output image, we will use the jet colormap so that "bright"
// outputs, i.e. pixels with big values, appear in red and "dim" outputs appear as a
// cold blue color. To do this we pick a range of CNN output values for the color
// mapping. The specific values don't matter. They are just selected to give a nice
// looking output image.
const float lower = -2.5;
const float upper = 0.0;
cout << "jet color mapping range: lower="<< lower << " upper="<< upper << endl;
// Create a tiled pyramid image and display it on the screen.
std::vector tiled_img;
// Get the type of pyramid the CNN used
using pyramid_type = std::remove_reference<decltype(input_layer(net))>::type::pyramid_type;
// And tell create_tiled_pyramid to create the pyramid using that pyramid type.
create_tiled_pyramid(img, tiled_img, rects,
input_layer(net).get_pyramid_padding(),
input_layer(net).get_pyramid_outer_padding());
image_window winpyr(tiled_img, "Tiled pyramid");
// This CNN detector represents a sliding window detector with 3 sliding windows. Each
// of the 3 windows has a different aspect ratio, allowing it to find vehicles which
// are either tall and skinny, squarish, or short and wide. The aspect ratio of a
// detection is determined by which channel in the output image triggers the detection.
// Here we are just going to max pool the channels together to get one final image for
// our display. In this image, a pixel will be bright if any of the sliding window
// detectors thinks there is a car at that location.
cout << "Number of channels in final tensor image: " << net.subnet().get_output().k() << endl;
matrix<float> network_output = image_plane(net.subnet().get_output(),0,0);
for (long k = 1; k < net.subnet().get_output().k(); ++k)
network_output = max_pointwise(network_output, image_plane(net.subnet().get_output(),0,k));
// We will also upsample the CNN's output image. The CNN we defined has an 8x
// downsampling layer at the beginning. In the code below we are going to overlay this
// CNN output image on top of the raw input image. To make that look nice it helps to
// upsample the CNN output image back to the same resolution as the input image, which
// we do here.
const double network_output_scale = img.nc()/(double)network_output.nc();
resize_image(network_output_scale, network_output);
// Display the network's output as a color image.
image_window win_output(jet(network_output, upper, lower), "Output tensor from the network");
// Also, overlay network_output on top of the tiled image pyramid and display it.
for (long r = 0; r < tiled_img.nr(); ++r)
{
for (long c = 0; c < tiled_img.nc(); ++c)
{
dpoint tmp(c,r);
tmp = input_tensor_to_output_tensor(net, tmp);
tmp = point(network_output_scale*tmp);
if (get_rect(network_output).contains(tmp))
{
float val = network_output(tmp.y(),tmp.x());
// alpha blend the network output pixel with the RGB image to make our
// overlay.
rgb_alpha_pixel p;
assign_pixel(p , colormap_jet(val,lower,upper));
p.alpha = 120;
assign_pixel(tiled_img(r,c), p);
}
}
}
// If you look at this image you can see that the vehicles have bright red blobs on
// them. That's the CNN saying "there is a car here!". You will also notice there is
// a certain scale at which it finds cars. They have to be not too big or too small,
// which is why we have an image pyramid. The pyramid allows us to find cars of all
// scales.
image_window win_pyr_overlay(tiled_img, "Detection scores on image pyramid");
// Finally, we can collapse the pyramid back into the original image. The CNN doesn't
// actually do this step, since it's enough to threshold the tiled pyramid image to get
// the detections. However, it makes a nice visualization and clearly indicates that
// the detector is firing for all the cars.
matrix<float> collapsed(img.nr(), img.nc());
resizable_tensor input_tensor;
input_layer(net).to_tensor(&img, &img+1, input_tensor);
for (long r = 0; r < collapsed.nr(); ++r)
{
for (long c = 0; c < collapsed.nc(); ++c)
{
// Loop over a bunch of scale values and look up what part of network_output
// corresponds to the point(c,r) in the original image, then take the max
// detection score over all the scales and save it at pixel point(c,r).
float max_score = -1e30;
for (double scale = 1; scale > 0.2; scale *= 5.0/6.0)
{
// Map from input image coordinates to tiled pyramid coordinates.
dpoint tmp = center(input_layer(net).image_space_to_tensor_space(input_tensor,scale, drectangle(dpoint(c,r))));
// Now map from pyramid coordinates to network_output coordinates.
tmp = point(network_output_scale*input_tensor_to_output_tensor(net, tmp));
if (get_rect(network_output).contains(tmp))
{
float val = network_output(tmp.y(),tmp.x());
if (val > max_score)
max_score = val;
}
}
collapsed(r,c) = max_score;
// Also blend the scores into the original input image so we can view it as
// an overlay on the cars.
rgb_alpha_pixel p;
assign_pixel(p , colormap_jet(max_score,lower,upper));
p.alpha = 120;
assign_pixel(img(r,c), p);
}
}
image_window win_collapsed(jet(collapsed, upper, lower), "Collapsed output tensor from the network");
image_window win_img_and_sal(img, "Collapsed detection scores on raw image");
cout << "Hit enter to end program" << endl;
cin.get();
}
catch(image_load_error& e)
{
cout << e.what() << endl;
cout << "The test image is located in the examples folder. So you should run this program from a sub folder so that the relative path is correct." << endl;
}
catch(serialization_error& e)
{
cout << e.what() << endl;
cout << "The model file can be obtained from: http://dlib.net/files/mmod_rear_end_vehicle_detector.dat.bz2 Don't forget to unzip the file." << endl;
}
catch(std::exception& e)
{
cout << e.what() << endl;
}