全序列卷积神经网络+连接时序分类语音识别
全序列卷积神经网络
DFCNN:deep fully convolutional neural network 全序列卷积神经网络
DFCNN对时域信号进行分帧、加窗、傅里叶变换、取对数得到语谱图。
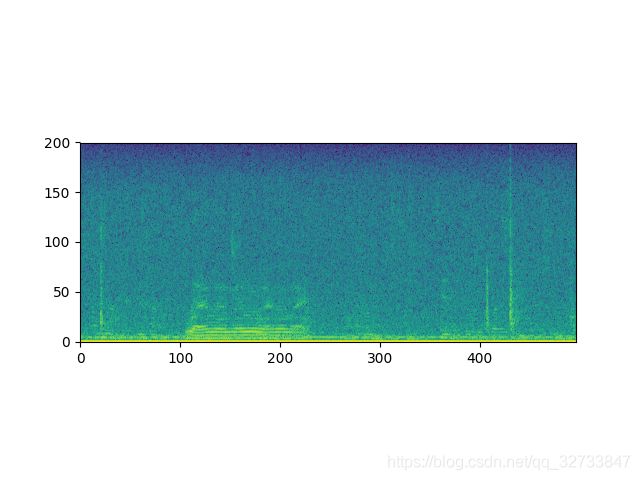
语谱图的x是时间,y轴是频率,z轴是幅度。幅度用亮色如红色表示高,用深色表示低。利用语谱图可以查看指定频率端的能量分布。
DFCNN直接将一句语音作为输入,输出单元则直接与最终的识别结果相对应(音节或汉字),DFCNN的结构中把时间和频率作为图像的两个维度,通过较多的卷积层和池化层的组合,实现对整个语句的建模。
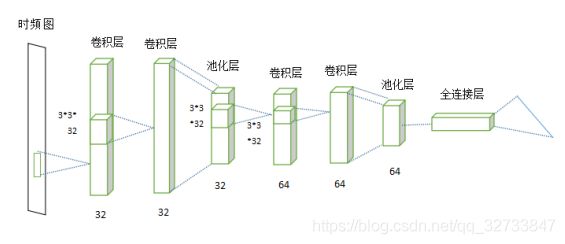
首先对音频文件的每帧进行傅里叶变换,将时间和频率做为图像的两个维度,然后使用3*3的卷积核对时频图进行卷积,卷积层(convolution layer)输出32特征,然后使用最大池化Maxpooling提取最大参数,来降低参数数量,池化层(pooling layer)输出64特征,此时数据的另两个维度减半,然后再通过一次cnn_cell,此时数据的维度减半,特征值变为128,最后接入全连接层(fully connected layers)。
卷积层的卷积核(kernel_size)大小为(3,3),提取32个特征,扩充padding为1,卷积步长为1,则经过一次卷积层后,图像的尺寸为(n+2p-f+1) x (n+2p-f+1)=(n,n)。
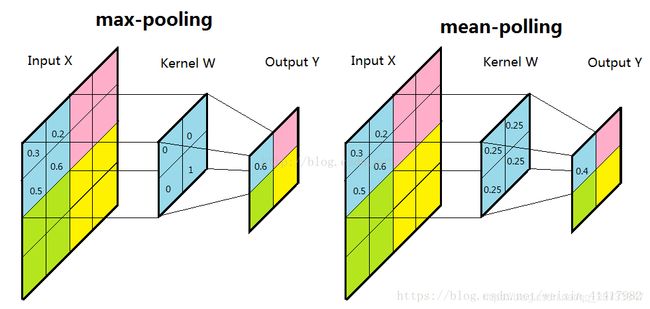
池化层(pooling)来减少尺寸,提高运算速度,降低噪声,这里使用的是Maxpooling方法,pool_size大小为(2,2),取pool_size中最大的数字,当图片经过池化层后,维度减半。
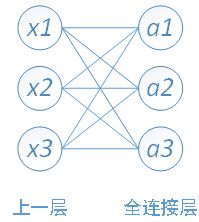
全连接层的每个神经元与前一池化层的所有神经元进行连接,全连接层整合卷积和池化层的分类特征并加以区分。每个神经元的激励函数使用ReLU函数,最后一层的输出值被传递到sotfmax逻辑回归进行分类。
更新全连接层的参数使用两种方式:前向传播和反向传播。
前向传播:
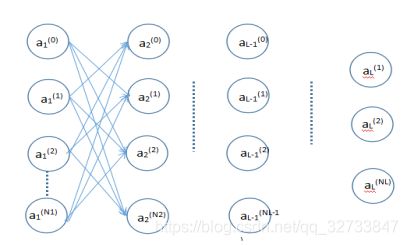
L:层数
Ni:除了偏置单元之外的第 i 层中的神经元数,其中i = 1,2,…,L
Ai(j):第 i 层中第 j 个神经元的输出,其中i = 1,2 … L | j = 0,1,2 … .N
第i+1层输入:
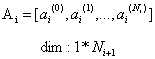
从第i层到第i+1层的权重矩阵:
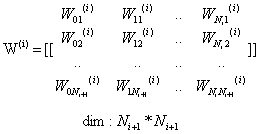
全连接层的输出:
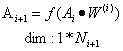
反向传播:确定输出端的损耗(或误差),然后将其传播回网络。更新权重以最小化每个神经元产生的误差。最小化误差的第一步是确定每个节点的梯度。
错误:
![]()
反向传播错误进入网络:
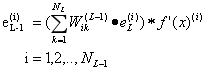
更新权重以最小化梯度:

连接时序分类
CTC:connectionist temporal classification 连接时序分类
传统的语音识别的声学模型训练,每一帧数据必须知道label才能进行训练,语音对齐需要进行反复迭代,来确保对齐,耗费时间。
CTC使用的是端到端,只需要输入输出序列,CTC会输出序列预测的概率,只关心输出序列是否接近,不关心是否对齐。
CTC引入blank(无预测值),每个预测值的分类对应一段语音中的一个尖峰(spike)其他不是尖峰的默认为blank,输出尖峰的序列,无持续时间。
序列问题可以形式化为函数:
![]()
序列目标为字符串(词表大小为n)即Nw输出为n维多项式概率分布(softmax)。
网络输出为:

1.序列建模
没有限定Nw的具体形式,假设某种神经网络(RNN)。
2.align-free变长映射
CTC引入一个特殊的blank字符(%),扩展原始词表L为L’=L U {blank},对输出字符串,定义操作B:(1)合并连续的相同符号,(2)去掉blank字符
例如:aa%bb%%cc 应用B,实际上代表abc
通过引入blank和B,可以实现映射:
![]()
注意:只能建模长度小于输入长度
3.似然计算
CTC使用最大似然标准进行计算,给定输入x,输出l的条件概率为:

CTC假设输出的概率(相对输入)条件独立的:
![]()
#4.前向算法
对音频的数字化处理
wav文件是微软公司研发的一种音频文件,支持多种压缩运算法。
此次实验中使用的音频文件被保存为wav格式,使用16kHz,单声道,8bit的形式。
在音频文件读取的过程中,使用python中的Scipy包,Scipy是数学、工程中常用包,主要用来处理一些积分、方程求解、信号处理等问题。在此次实验中,使用数据输入输出的Scipy.io模块。在画图的过程中,使用python中的matplotlib包,matplotlib是python中的图形绘制包。
然后构造汉明窗函数。原因:语音信号一般在10ms到30ms之间,为了处理语音信号,我们需要构造汉明窗,也就是一次仅处理窗内的数据,因此,构造一个函数,在一段区间内有非零值,其他区间都为零,加上窗之后,只有中间的数据体现出来,其他数据丢失,等到窗移动的时候,后面丢失的又体现出来。
汉明窗函数:
![]()
当0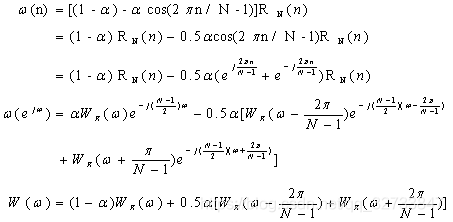
当N>>1时,N-1≈N,其频谱近似为:
![]()
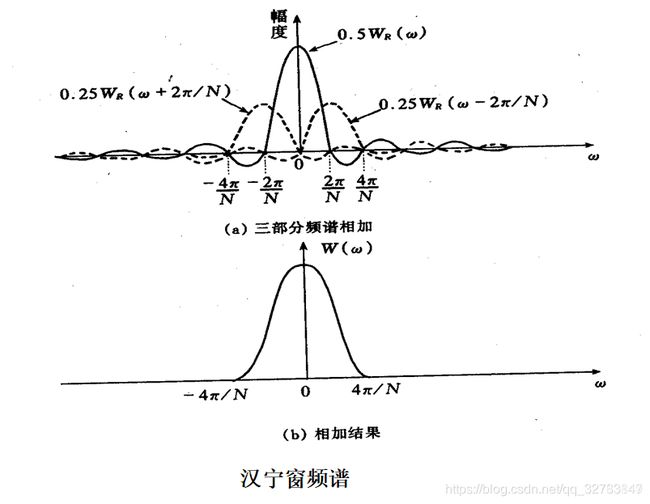
三部分矩形窗频谱相加,使旁瓣互相抵消,能量集中在主瓣,旁瓣大大减小,主瓣宽度增加1倍。
对数据进行分帧加窗,确定采样个数。
对处理完的数据进行快速傅里叶变换,将时域信号转到频域上来,此处使用Scipy.fftpack。
获取语谱图,对语音文件的数字化处理完成。