Flink实战(七) - Time & Windows编程
0 相关源码
掌握Flink中三种常用的Time处理方式,掌握Flink中滚动窗口以及滑动窗口的使用,了解Flink中的watermark。
Flink 在流处理工程中支持不同的时间概念。
1 处理时间(Processing time)
执行相应算子操作的机器的系统时间.
当流程序在处理时间运行时,所有基于时间的 算子操作(如时间窗口)将使用运行相应算子的机器的系统时钟。每小时处理时间窗口将包括在系统时钟指示整个小时之间到达特定算子的所有记录。
例如,如果应用程序在上午9:15开始运行,则第一个每小时处理时间窗口将包括在上午9:15到上午10:00之间处理的事件,下一个窗口将包括在上午10:00到11:00之间处理的事件
处理时间是最简单的时间概念,不需要流和机器之间的协调
它提供最佳性能和最低延迟。但是,在分布式和异步环境中,处理时间不提供确定性,因为它容易受到记录到达系统的速度(例如从消息队列)到记录在系统内的算子之间流动的速度的影响。和停电(调度或其他)。
2 事件时间(Event time)
每个单独的事件在其生产设备上发生的时间.
此时间通常在进入Flink之前内置在记录中,并且可以从每个记录中提取该事件时间戳。
在事件时间,时间的进展取决于数据,而不是任何挂钟。
事件时间程序必须指定如何生成事件时间水印,这是表示事件时间进度的机制.
在一个完美的世界中,事件时间处理将产生完全一致和确定的结果,无论事件何时到达,或者顺序.
但是,除非事件已知按顺序到达(按时间戳),否则事件时间处理会在等待无序事件时产生一些延迟。由于只能等待一段有限的时间,因此限制了确定性事件时间应用程序的可能性。
假设所有数据都已到达,算子操作将按预期运行,即使在处理无序或延迟事件或重新处理历史数据时也会产生正确且一致的结果。
例如,每小时事件时间窗口将包含带有落入该小时的事件时间戳的所有记录,无论它们到达的顺序如何,或者何时处理它们。(有关更多信息,请参阅有关迟发事件的部分。)
请注意,有时当事件时间程序实时处理实时数据时,它们将使用一些处理时间 算子操作,以确保它们及时进行。
3 摄取时间(Ingestion time)
事件进入Flink的时间.
在源算子处,每个记录将源的当前时间作为时间戳,并且基于时间的算子操作(如时间窗口)引用该时间戳。
在概念上位于事件时间和处理时间之间。
- 与处理时间相比 ,它成本稍微高一些,但可以提供更可预测的结果。因为使用稳定的时间戳(在源处分配一次),所以对记录的不同窗口 算子操作将引用相同的时间戳,而在处理时间中,每个窗口算子可以将记录分配给不同的窗口(基于本地系统时钟和任何运输延误)
- 与事件时间相比,无法处理任何无序事件或后期数据,但程序不必指定如何生成水印。
在内部,摄取时间与事件时间非常相似,但具有自动时间戳分配和自动水印生成函数

4 设置时间特性
Flink DataStream程序的第一部分通常设置基本时间特性

- 显然,在Flink的流式处理环境中,默认使用处理时间

该设置定义了数据流源的行为方式(例如,它们是否将分配时间戳),以及窗口 算子操作应该使用的时间概念,比如
KeyedStream.timeWindow(Time.seconds(30))。
以下示例显示了一个Flink程序,该程序在每小时时间窗口中聚合事件。窗口的行为适应时间特征。
- Java
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
// 可选的:
// env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
// env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream stream = env.addSource(new FlinkKafkaConsumer09(topic, schema, props));
stream
.keyBy( (event) -> event.getUser() )
.timeWindow(Time.hours(1))
.reduce( (a, b) -> a.add(b) )
.addSink(...);
- Scala
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
// alternatively:
// env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime)
// env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val stream: DataStream[MyEvent] = env.addSource(new FlinkKafkaConsumer09[MyEvent](topic, schema, props))
stream
.keyBy( _.getUser )
.timeWindow(Time.hours(1))
.reduce( (a, b) => a.add(b) )
.addSink(...)
请注意,为了在事件时间运行此示例,程序需要使用直接为数据定义事件时间的源并自行发出水印,或者程序必须在源之后注入时间戳分配器和水印生成器。这些函数描述了如何访问事件时间戳,以及事件流表现出的无序程度。
5 Windows
5.1 简介
Windows是处理无限流的核心。Windows将流拆分为有限大小的“桶”,我们可以在其上应用计算。我们重点介绍如何在Flink中执行窗口,以及程序员如何从其提供的函数中获益最大化。
窗口Flink程序的一般结构如下所示
- 第一个片段指的是被Keys化流
- 而第二个片段指的是非被Keys化流
正如所看到的,唯一的区别是keyBy(…)呼吁Keys流和window(…)成为windowAll(…)非被Key化的数据流。这也将作为页面其余部分的路线图。
Keyed Windows

Non-Keyed Windows

在上面,方括号([…])中的命令是可选的。这表明Flink允许您以多种不同方式自定义窗口逻辑,以便最适合您的需求。
5.2 窗口生命周期
简而言之,只要应该属于此窗口的第一个数据元到达,就会创建一个窗口,当时间(事件或处理时间)超过其结束时间戳加上用户指定 时,窗口将被完全删除allowed lateness(请参阅允许的延迟))。Flink保证仅删除基于时间的窗口而不是其他类型,例如全局窗口(请参阅窗口分配器)。例如,使用基于事件时间的窗口策略,每5分钟创建一个非重叠(或翻滚)的窗口,并允许延迟1分钟,Flink将创建一个新窗口,用于间隔12:00和12:05当具有落入此间隔的时间戳的第一个数据元到达时,当水印通过12:06 时间戳时它将删除它。
此外,每个窗口将具有Trigger和一个函数(ProcessWindowFunction,ReduceFunction, AggregateFunction或FoldFunction)连接到它。该函数将包含要应用于窗口内容的计算,而Trigger指定窗口被认为准备好应用该函数的条件。
触发策略可能类似于“当窗口中的数据元数量大于4”时,或“当水印通过窗口结束时”。
触发器还可以决定在创建和删除之间的任何时间清除窗口的内容。在这种情况下,清除仅指窗口中的数据元,而不是窗口元数据。这意味着仍然可以将新数据添加到该窗口。
除了上述内容之外,您还可以指定一个Evictor,它可以在触发器触发后以及应用函数之前和/或之后从窗口中删除数据元。
5.3 被Keys化与非被Keys化Windows
要指定的第一件事是您的流是否应该键入。必须在定义窗口之前完成此 算子操作。使用the keyBy(…)将您的无限流分成逻辑被Key化的数据流。如果keyBy(…)未调用,则表示您的流不是被Keys化的。
对于被Key化的数据流,可以将传入事件的任何属性用作键(此处有更多详细信息)。拥有被Key化的数据流将允许您的窗口计算由多个任务并行执行,因为每个逻辑被Key化的数据流可以独立于其余任务进行处理。引用相同Keys的所有数据元将被发送到同一个并行任务。
在非被Key化的数据流的情况下,您的原始流将不会被拆分为多个逻辑流,并且所有窗口逻辑将由单个任务执行,即并行度为1。
6 窗口分配器
指定流是否已键入后,下一步是定义一个窗口分配器.
窗口分配器定义如何将数据元分配给窗口,这是通过WindowAssigner 在window(…)(对于被Keys化流)或windowAll()(对于非被Keys化流)调用中指定您的选择来完成的

WindowAssigner负责将每个传入数据元分配给一个或多个窗口
Flink带有预定义的窗口分配器,用于最常见的用例,即
- 滚动窗口
- 滑动窗口
- 会话窗口
- 全局窗口
还可以通过扩展WindowAssigner类来实现自定义窗口分配器。所有内置窗口分配器(全局窗口除外)都根据时间为窗口分配数据元,这可以是处理时间或事件时间。请查看我们关于活动时间的部分,了解处理时间和事件时间之间的差异以及时间戳和水印的生成方式。
基于时间的窗口具有开始时间戳(包括)和结束时间戳(不包括),它们一起描述窗口的大小。
在代码中,Flink在使用TimeWindow基于时间的窗口时使用,该窗口具有查询开始和结束时间戳的方法maxTimestamp()返回给定窗口的最大允许时间戳

下图显示了每个分配者的工作情况。紫色圆圈表示流的数据元,这些数据元由某个键(在这种情况下是用户1,用户2和用户3)划分。x轴显示时间的进度。
6.1 滚动窗口
一个滚动窗口分配器的每个数据元分配给指定的窗口的窗口大小。滚动窗口具有固定的尺寸,不重叠.
例如,如果指定大小为5分钟的翻滚窗口,则将评估当前窗口,并且每五分钟将启动一个新窗口,如下图所示

以下代码段显示了如何使用滚动窗口。
- Java
DataStream input = ...;
// tumbling event-time windows
input
.keyBy()
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.();
// tumbling processing-time windows
input
.keyBy()
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.();
// daily tumbling event-time windows offset by -8 hours.
input
.keyBy()
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.();
- Scala
val input: DataStream[T] = ...
// tumbling event-time windows
input
.keyBy()
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.()
// tumbling processing-time windows
input
.keyBy()
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.()
// daily tumbling event-time windows offset by -8 hours.
input
.keyBy()
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.()
- Scala

- Java

6.2 滑动窗口
该滑动窗口分配器分配元件以固定长度的窗口。与滚动窗口分配器类似,窗口大小由窗口大小参数配置
附加的窗口滑动参数控制滑动窗口的启动频率。因此,如果幻灯片小于窗口大小,则滑动窗口可以重叠。在这种情况下,数据元被分配给多个窗口。
例如,您可以将大小为10分钟的窗口滑动5分钟。有了这个,你每隔5分钟就会得到一个窗口,其中包含过去10分钟内到达的事件,如下图所示。
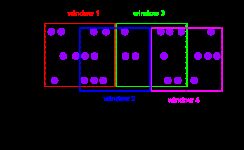
以下代码段显示了如何使用滑动窗口
- Java
DataStream input = ...;
// 滑动 事件时间 窗口
input
.keyBy()
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.();
// 滑动 处理时间 窗口
input
.keyBy()
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.();
// daily tumbling event-time windows offset by -8 hours.
input
.keyBy()
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.();
- Scala
val input: DataStream[T] = ...
// tumbling event-time windows
input
.keyBy()
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.()
// tumbling processing-time windows
input
.keyBy()
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.()
// daily tumbling event-time windows offset by -8 hours.
input
.keyBy()
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.()
7 窗口函数
定义窗口分配器后,我们需要指定要在每个窗口上执行的计算。这是窗口函数的职责,窗口函数用于在系统确定窗口准备好进行处理后处理每个(可能是被Keys化的)窗口的数据元
的窗函数可以是一个ReduceFunction,AggregateFunction,FoldFunction或ProcessWindowFunction。前两个可以更有效地执行,因为Flink可以在每个窗口到达时递增地聚合它们的数据元.
ProcessWindowFunction获取Iterable窗口中包含的所有数据元以及有关数据元所属窗口的其他元信息。
具有ProcessWindowFunction的窗口转换不能像其他情况一样有效地执行,因为Flink必须在调用函数之前在内部缓冲窗口的所有数据元。这可以通过组合来减轻ProcessWindowFunction与ReduceFunction,AggregateFunction或FoldFunction以获得两个窗口元件的增量聚合并且该附加元数据窗口 ProcessWindowFunction接收。我们将查看每个变体的示例。
7.1 ReduceFunction
指定如何组合输入中的两个数据元以生成相同类型的输出数据元.
Flink使用ReduceFunction来递增地聚合窗口的数据元.
定义和使用
- Java
DataStream> input = ...;
input
.keyBy()
.window()
.reduce(new ReduceFunction> {
public Tuple2 reduce(Tuple2 v1, Tuple2 v2) {
return new Tuple2<>(v1.f0, v1.f1 + v2.f1);
}
});
- Scala
val input: DataStream[(String, Long)] = ...
input
.keyBy()
.window()
.reduce { (v1, v2) => (v1._1, v1._2 + v2._2) }
原来传递进来的数据是字符串,此处我们就使用数值类型,通过数值类型来演示增量的效果
这里不是等待窗口所有的数据进行一次性处理,而是数据两两处理

- 输入

- 增量输出

- Java

7.2 聚合函数
An AggregateFunction是一个通用版本,ReduceFunction它有三种类型:输入类型(IN),累加器类型(ACC)和输出类型(OUT)。输入类型是输入流中数据元的类型,并且AggregateFunction具有将一个输入数据元添加到累加器的方法。该接口还具有用于创建初始累加器的方法,用于将两个累加器合并到一个累加器中以及用于OUT从累加器提取输出(类型)。我们将在下面的示例中看到它的工作原理。
与之相同ReduceFunction,Flink将在窗口到达时递增地聚合窗口的输入数据元。
一个AggregateFunction可以被定义并这样使用:
/**
* The accumulator is used to keep a running sum and a count. The {@code getResult} method
* computes the average.
*/
private static class AverageAggregate
implements AggregateFunction, Tuple2, Double> {
@Override
public Tuple2 createAccumulator() {
return new Tuple2<>(0L, 0L);
}
@Override
public Tuple2 add(Tuple2 value, Tuple2 accumulator) {
return new Tuple2<>(accumulator.f0 + value.f1, accumulator.f1 + 1L);
}
@Override
public Double getResult(Tuple2 accumulator) {
return ((double) accumulator.f0) / accumulator.f1;
}
@Override
public Tuple2 merge(Tuple2 a, Tuple2 b) {
return new Tuple2<>(a.f0 + b.f0, a.f1 + b.f1);
}
}
DataStream> input = ...;
input
.keyBy()
.window()
.aggregate(new AverageAggregate());
- Scala
/**
* The accumulator is used to keep a running sum and a count. The [getResult] method
* computes the average.
*/
class AverageAggregate extends AggregateFunction[(String, Long), (Long, Long), Double] {
override def createAccumulator() = (0L, 0L)
override def add(value: (String, Long), accumulator: (Long, Long)) =
(accumulator._1 + value._2, accumulator._2 + 1L)
override def getResult(accumulator: (Long, Long)) = accumulator._1 / accumulator._2
override def merge(a: (Long, Long), b: (Long, Long)) =
(a._1 + b._1, a._2 + b._2)
}
val input: DataStream[(String, Long)] = ...
input
.keyBy()
.window()
.aggregate(new AverageAggregate)
7.3 ProcessWindowFunction
ProcessWindowFunction获取包含窗口的所有数据元的Iterable,以及可访问时间和状态信息的Context对象,这使其能够提供比其他窗口函数更多的灵活性。这是以性能和资源消耗为代价的,因为数据元不能以递增方式聚合,而是需要在内部进行缓冲,直到窗口被认为已准备好进行处理。
ProcessWindowFunction外观签名如下:
public abstract class ProcessWindowFunction implements Function {
/**
* Evaluates the window and outputs none or several elements.
*
* @param key The key for which this window is evaluated.
* @param context The context in which the window is being evaluated.
* @param elements The elements in the window being evaluated.
* @param out A collector for emitting elements.
*
* @throws Exception The function may throw exceptions to fail the program and trigger recovery.
*/
public abstract void process(
KEY key,
Context context,
Iterable elements,
Collector out) throws Exception;
/**
* The context holding window metadata.
*/
public abstract class Context implements java.io.Serializable {
/**
* Returns the window that is being evaluated.
*/
public abstract W window();
/** Returns the current processing time. */
public abstract long currentProcessingTime();
/** Returns the current event-time watermark. */
public abstract long currentWatermark();
/**
* State accessor for per-key and per-window state.
*
* NOTE:If you use per-window state you have to ensure that you clean it up
* by implementing {@link ProcessWindowFunction#clear(Context)}.
*/
public abstract KeyedStateStore windowState();
/**
* State accessor for per-key global state.
*/
public abstract KeyedStateStore globalState();
}
}
abstract class ProcessWindowFunction[IN, OUT, KEY, W <: Window] extends Function {
/**
* Evaluates the window and outputs none or several elements.
*
* @param key The key for which this window is evaluated.
* @param context The context in which the window is being evaluated.
* @param elements The elements in the window being evaluated.
* @param out A collector for emitting elements.
* @throws Exception The function may throw exceptions to fail the program and trigger recovery.
*/
def process(
key: KEY,
context: Context,
elements: Iterable[IN],
out: Collector[OUT])
/**
* The context holding window metadata
*/
abstract class Context {
/**
* Returns the window that is being evaluated.
*/
def window: W
/**
* Returns the current processing time.
*/
def currentProcessingTime: Long
/**
* Returns the current event-time watermark.
*/
def currentWatermark: Long
/**
* State accessor for per-key and per-window state.
*/
def windowState: KeyedStateStore
/**
* State accessor for per-key global state.
*/
def globalState: KeyedStateStore
}
}
该key参数是通过KeySelector为keyBy()调用指定的Keys提取的Keys。在元组索引键或字符串字段引用的情况下,此键类型始终是Tuple,您必须手动将其转换为正确大小的元组以提取键字段。
A ProcessWindowFunction可以像这样定义和使用:
DataStream> input = ...;
input
.keyBy(t -> t.f0)
.timeWindow(Time.minutes(5))
.process(new MyProcessWindowFunction());
/* ... */
public class MyProcessWindowFunction
extends ProcessWindowFunction, String, String, TimeWindow> {
@Override
public void process(String key, Context context, Iterable> input, Collector out) {
long count = 0;
for (Tuple2 in: input) {
count++;
}
out.collect("Window: " + context.window() + "count: " + count);
}
}
val input: DataStream[(String, Long)] = ...
input
.keyBy(_._1)
.timeWindow(Time.minutes(5))
.process(new MyProcessWindowFunction())
/* ... */
class MyProcessWindowFunction extends ProcessWindowFunction[(String, Long), String, String, TimeWindow] {
def process(key: String, context: Context, input: Iterable[(String, Long)], out: Collector[String]): () = {
var count = 0L
for (in <- input) {
count = count + 1
}
out.collect(s"Window ${context.window} count: $count")
}
}
该示例显示了ProcessWindowFunction对窗口中的数据元进行计数的情况。此外,窗口函数将有关窗口的信息添加到输出。
注意注意,使用ProcessWindowFunction简单的聚合(例如count)是非常低效的
8 水印
- 推荐阅读
Flink流计算编程–watermark(水位线)简介
参考
Event Time
Windows