零基础入门NLP- 新闻文本分类 TASK2数据读取与数据分析
2.1 数据读取与数据分析
本章主要内容为数据读取和数据分析,具体使用Pandas库完成数据读取操作,并对赛题数据进行分析构成。
2.1.1 学习目标
1.学习使用Pandas读取赛题数据
2.分析赛题数据的分布规律
2.1.2 数据读取
train_pd = pd.read_csv('myspace/dataset/train_set.csv',sep='\t')

数据由label和text两部分组成,label是新闻文本对应的类别,text是加密后的新闻文本。
2.1.3 数据分析
在完成数据集的读取后,我们可以对数据集进行数据分析操作。我们可以对赛题数据进行如下几点的分析:
1.赛题数据中,新闻文本的长度是多少?
2.赛题数据的类别分布是怎么样的,哪种类别比价多?
3.塞梯数据中,字符分布是怎么样的?
句子长度分析
在数据集中,每一条新闻中的单词使用空格进行隔开,所以可以通过统计单词的数据来获得句子的长度
train_pd['len_text'] = [len(train_pd['text'][k].split(' ')) for k in range(len(train_pd))]
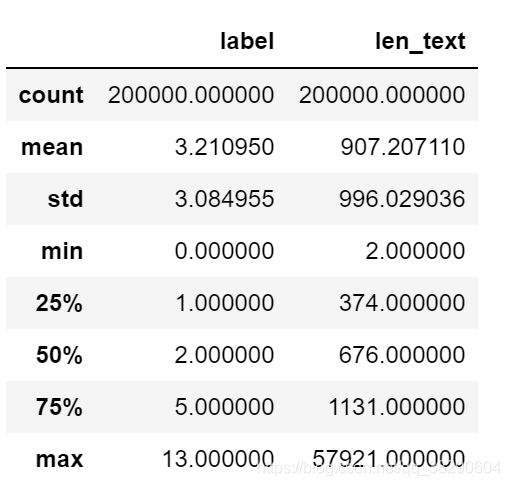
通过统计得到,赛题数据中平均每个句子由907个字符组成,最短的句子两个字符,最长的句子57921个字符。
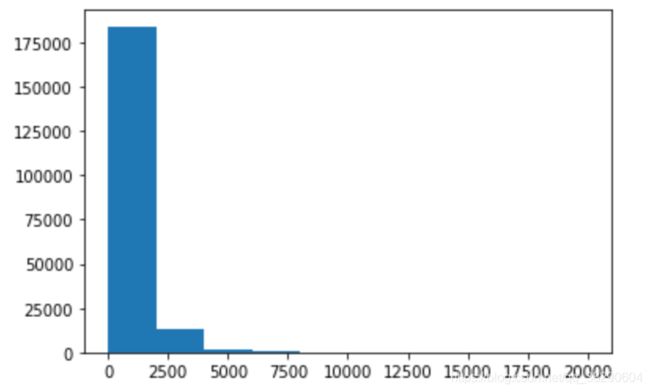
对句子的长度绘制直方图,可以发现大部分句子的长度在2500内。
_ = plt.hist(train_pd['len_text'],range=(0,20000))
新闻类别分布
接下来对数据集的类别进行分布统计,具体统计每类新闻的样本个数。
train_pd['label'].value_counts().plot(kind='bar')
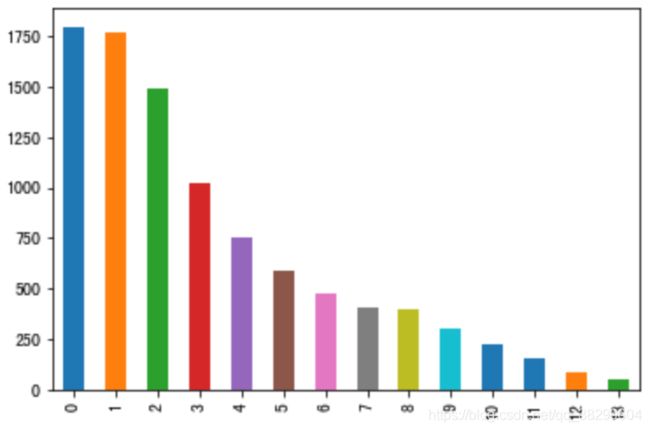
从统计结果可以看出,0类别的新闻最多,赛题数据集新闻类别分布较为不均匀。
字符分布统计
接下来统计每个字符出现的次数,将训练集中所有的文本进行拼接进而对每个字符出现的次数进行统计。
all_list = ' '.join(list(train_pd['text']))
word_count = Counter(all_list.split(' '))
word_count = sorted(word_count.items(), key=lambda d:d[1], reverse = True)

可以看出,‘3750’,‘648’,‘900’这几种字符出现的次数最多,推测可能是标点符号。
新闻文本分行
由于赛题数据中新闻文本过长,所以考虑将其进行分行。前边推测‘3750’,‘648’,‘900’这几种字符可能是标点符号,所以以他们作为分隔符进行文本分行。
import re
len(re.split('3750|900|648',train_pd['text'][0]))
train_pd['len_one'] = [len(re.split('3750|900|648',train_pd['text'][x])) for x in range(len(train_pd['text']))]
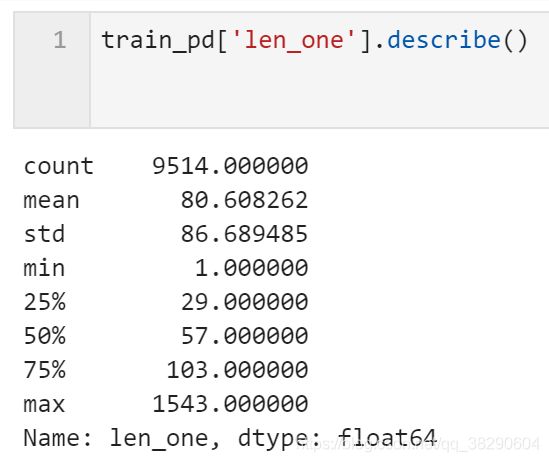
平均每条新闻文本由80行组成。
统计每一类新闻出现次数最多的字符
首先统计每一条新闻出现次数最多的字符
train_pd['max_word'] = [max(Counter(train_pd['text'][x].split())) for x in range(len(train_pd['text']))]

对每一个类别出现次数最多的字符进行统计
word_dict = {}
for i in range(len(train_pd)):
word_dict[train_pd['label'][i]] = []
for i in range(len(train_pd['text'])):
word_dict[train_pd['label'][i]].append(train_pd['max_word'][i])
for i in range(len(word_dict)):
word_dict[i] = max(Counter(word_dict[i]))

2.1.4 数据分析结论
通过上述的数据分析,可以得出以下结论:
1.赛题中每个新闻包含的字符个数平均1000,还有一些更长;
2.赛题的新闻类别分布不均匀,科技类新闻数量接近4w,星座类不到1k;
3.赛题总共包含7000-8000个字符;