Spark _30_SparkStreaming算子操作&Driver HA
SparkStreaming算子操作
foreachRDD
- output operation算子,必须对抽取出来的RDD执行action类算子,代码才能执行。
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* SparkStreaming 注意:
* 1.需要设置local[2],因为一个线程是读取数据,一个线程是处理数据
* 2.创建StreamingContext两种方式,如果采用的是StreamingContext(conf,Durations.seconds(5))这种方式,不能在new SparkContext
* 3.Durations 批次间隔时间的设置需要根据集群的资源情况以及监控每一个job的执行时间来调节出最佳时间。
* 4.SparkStreaming所有业务处理完成之后需要有一个output operato操作
* 5.StreamingContext.start()straming框架启动之后是不能在次添加业务逻辑
* 6.StreamingContext.stop()无参的stop方法会将sparkContext一同关闭,stop(false) ,默认为true,会一同关闭
* 7.StreamingContext.stop()停止之后是不能在调用start
*/
object WordCountFromSocket {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("WordCountOnLine").setMaster("local[2]")
val ssc = new StreamingContext(conf,Durations.seconds(5))
ssc.sparkContext.setLogLevel("ERROR")
//使用new StreamingContext(conf,Durations.seconds(5)) 这种方式默认会创建SparkContext
// val sc = new SparkContext(conf)
//从ssc中获取SparkContext()
// val context: SparkContext = ssc.sparkContext
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("c7node5",9999)
val words: DStream[String] = lines.flatMap(line=>{line.split(" ")})
val pairWords: DStream[(String, Int)] = words.map(word=>{(word,1)})
val result: DStream[(String, Int)] = pairWords.reduceByKey((v1, v2)=>{v1+v2})
// result.print()
/**
* foreachRDD 注意事项:
* 1.foreachRDD中可以拿到DStream中的RDD,对RDD进行操作,但是一点要使用RDD的action算子触发执行,不然DStream的逻辑也不会执行
* 2.froeachRDD算子内,拿到的RDD算子操作外,这段代码是在Driver端执行的,可以利用这点做到动态的改变广播变量
*
*/
result.foreachRDD(wordCountRDD=>{
println("******* produce in Driver *******")
val sortRDD: RDD[(String, Int)] = wordCountRDD.sortByKey(false)
val result: RDD[(String, Int)] = sortRDD.filter(tp => {
println("******* produce in Executor *******")
true
})
result.foreach(println)
})
ssc.start()
ssc.awaitTermination()
ssc.stop(false)
}
}
transform
- transformation类算子
- 可以通过transform算子,对Dstream做RDD到RDD的任意操作。
import org.apache.spark.SparkConf
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
object TransformBlackList {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("transform")
conf.setMaster("local[2]")
val ssc = new StreamingContext(conf,Durations.seconds(5))
// ssc.sparkContext.setLogLevel("Error")
/**
* 广播黑名单
*/
val blackList: Broadcast[List[String]] = ssc.sparkContext.broadcast(List[String]("zhangsan","lisi"))
/**
* 从实时数据【"hello zhangsan","hello lisi"】中发现 数据的第二位是黑名单人员,过滤掉
*/
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("node5",9999)
val pairLines: DStream[(String, String)] = lines.map(line=>{(line.split(" ")(1),line)})
/**
* transform 算子可以拿到DStream中的RDD,对RDD使用RDD的算子操作,但是最后要返回RDD,返回的RDD又被封装到一个DStream
* transform中拿到的RDD的算子外,代码是在Driver端执行的。可以做到动态的改变广播变量
*/
val resultDStream: DStream[String] = pairLines.transform((pairRDD:RDD[(String,String)]) => {
println("++++++ Driver Code +++++++")
val filterRDD: RDD[(String, String)] = pairRDD.filter(tp => {
val nameList: List[String] = blackList.value
!nameList.contains(tp._1)
})
val returnRDD: RDD[String] = filterRDD.map(tp => tp._2)
returnRDD
})
resultDStream.print()
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
updateStateByKey
- transformation算子
- updateStateByKey作用:
- 为SparkStreaming中每一个Key维护一份state状态,state类型可以是任意类型的,可以是一个自定义的对象,更新函数也可以是自定义的。
- 通过更新函数对该key的状态不断更新,对于每个新的batch而言,SparkStreaming会在使用updateStateByKey的时候为已经存在的key进行state的状态更新。
- 使用到updateStateByKey要开启checkpoint机制和功能。
- 多久会将内存中的数据写入到磁盘一份?
如果batchInterval设置的时间小于10秒,那么10秒写入磁盘一份。如果batchInterval设置的时间大于10秒,那么就会batchInterval时间间隔写入磁盘一份。
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
/**
* UpdateStateByKey 根据key更新状态
* 1、为Spark Streaming中每一个Key维护一份state状态,state类型可以是任意类型的, 可以是一个自定义的对象,那么更新函数也可以是自定义的。
* 2、通过更新函数对该key的状态不断更新,对于每个新的batch而言,Spark Streaming会在使用updateStateByKey的时候为已经存在的key进行state的状态更新
*/
object UpdateStateByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[2]")
conf.setAppName("UpdateStateByKey")
val ssc = new StreamingContext(conf,Durations.seconds(5))
//设置日志级别
ssc.sparkContext.setLogLevel("ERROR")
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("node5",9999)
val words: DStream[String] = lines.flatMap(line=>{line.split(" ")})
val pairWords: DStream[(String, Int)] = words.map(word => {(word, 1)})
/**
* 根据key更新状态,需要设置 checkpoint来保存状态
* 默认key的状态在内存中 有一份,在checkpoint目录中有一份。
*
* 多久会将内存中的数据(每一个key所对应的状态)写入到磁盘上一份呢?
* 如果你的batchInterval小于10s 那么10s会将内存中的数据写入到磁盘一份
* 如果bacthInterval 大于10s,那么就以bacthInterval为准
*
* 这样做是为了防止频繁的写HDFS
*/
// ssc.checkpoint("./data/streamingCheckpoint")
ssc.sparkContext.setCheckpointDir("./data/streamingCheckpoint")
/**
* currentValues :当前批次某个 key 对应所有的value 组成的一个集合
* preValue : 以往批次当前key 对应的总状态值
*/
val result: DStream[(String, Int)] = pairWords.updateStateByKey((currentValues: Seq[Int], preValue: Option[Int]) => {
var totalValues = 0
if (!preValue.isEmpty) {
totalValues += preValue.get
}
for(value <- currentValues){
totalValues += value
}
Option(totalValues)
})
result.print()
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
窗口操作
- 窗口操作理解图:
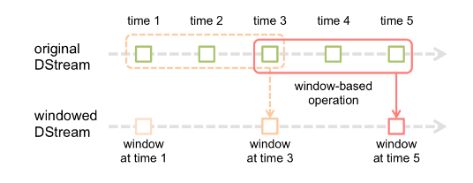
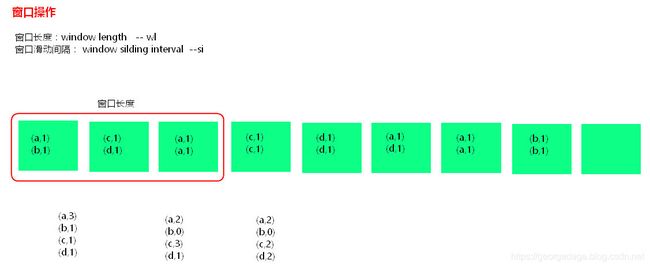
假设每隔5s 1个batch,上图中窗口长度为15s,窗口滑动间隔10s。
- 窗口长度和滑动间隔必须是batchInterval的整数倍。如果不是整数倍会检测报错。
- 优化后的window窗口操作示意图:
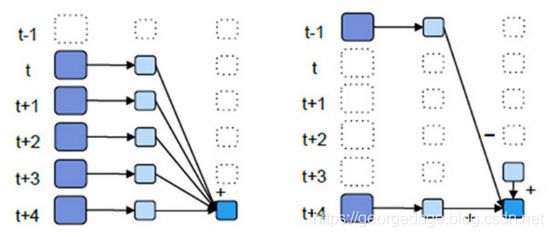
- 优化后的window操作要保存状态所以要设置checkpoint路径,没有优化的window操作可以不设置checkpoint路径。
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
import org.apache.spark.SparkConf
/**
* SparkStreaming 窗口操作
* reduceByKeyAndWindow
* 每隔窗口滑动间隔时间 计算 窗口长度内的数据,按照指定的方式处理
*/
object WindowOperator {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("windowOperator")
conf.setMaster("local[2]")
val ssc = new StreamingContext(conf,Durations.seconds(5))
ssc.sparkContext.setLogLevel("Error")
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("node5",9999)
val words: DStream[String] = lines.flatMap(line=>{line.split(" ")})
val pairWords: DStream[(String, Int)] = words.map(word=>{(word,1)})
// val ds : DStream[(String,Int)] = pairWords.window(Durations.seconds(15),Durations.seconds(5))
/**
* 窗口操作普通的机制
*
* 滑动间隔和窗口长度必须是 batchInterval 整数倍
*/
val windowResult: DStream[(String, Int)] =
pairWords.reduceByKeyAndWindow((v1:Int, v2:Int)=>{v1+v2},Durations.seconds(15),Durations.seconds(5))
/**
* 窗口操作优化的机制
*/
// ssc.checkpoint("./data/streamingCheckpoint")
// val windowResult: DStream[(String, Int)] = pairWords.reduceByKeyAndWindow(
// (v1:Int, v2:Int)=>{v1+v2},
// (v1:Int, v2:Int)=>{v1-v2},
// Durations.seconds(15),
// Durations.seconds(5))
windowResult.print()
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
Driver HA(Standalone或者Mesos)
因为SparkStreaming是7*24小时运行,Driver只是一个简单的进程,有可能挂掉,所以实现Driver的HA就有必要(如果使用的Client模式就无法实现Driver HA ,这里针对的是cluster模式)。Yarn平台cluster模式提交任务,AM(AplicationMaster)相当于Driver,如果挂掉会自动启动AM。这里所说的DriverHA针对的是Spark standalone和Mesos资源调度的情况下。实现Driver的高可用有两个步骤:
第一:提交任务层面,在提交任务的时候加上选项 --supervise,当Driver挂掉的时候会自动重启Driver。
第二:代码层面,使用JavaStreamingContext.getOrCreate(checkpoint路径,JavaStreamingContextFactory)
- Driver中元数据包括:
- 创建应用程序的配置信息。
- DStream的操作逻辑。
- job中没有完成的批次数据,也就是job的执行进度。
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Durations, StreamingContext}
/**
* Driver HA :
* 1.在提交application的时候 添加 --supervise 选项 如果Driver挂掉 会自动启动一个Driver
* 2.代码层面恢复Driver(StreamingContext)
*
*/
object SparkStreamingDriverHA {
//设置checkpoint目录
val ckDir = "./data/streamingCheckpoint"
def main(args: Array[String]): Unit = {
/**
* StreamingContext.getOrCreate(ckDir,CreateStreamingContext)
* 这个方法首先会从ckDir目录中获取StreamingContext【 因为StreamingContext是序列化存储在Checkpoint目录中,恢复时会尝试反序列化这些objects。
* 如果用修改过的class可能会导致错误,此时需要更换checkpoint目录或者删除checkpoint目录中的数据,程序才能起来。】
*
* 若能获取回来StreamingContext,就不会执行CreateStreamingContext这个方法创建,否则就会创建
*
*/
val ssc: StreamingContext = StreamingContext.getOrCreate(ckDir,CreateStreamingContext)
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
def CreateStreamingContext() = {
println("=======Create new StreamingContext =======")
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("DriverHA")
val ssc: StreamingContext = new StreamingContext(conf,Durations.seconds(5))
ssc.sparkContext.setLogLevel("Error")
/**
* 默认checkpoint 存储:
* 1.配置信息
* 2.DStream操作逻辑
* 3.job的执行进度
* * 4.offset
*/
ssc.checkpoint(ckDir)
val lines: DStream[String] = ssc.textFileStream("./data/streamingCopyFile")
val words: DStream[String] = lines.flatMap(line=>{line.trim.split(" ")})
val pairWords: DStream[(String, Int)] = words.map(word=>{(word,1)})
val result: DStream[(String, Int)] = pairWords.reduceByKey((v1:Int, v2:Int)=>{v1+v2})
// result.print()
/**
* 更改逻辑
*/
result.foreachRDD(pairRDD=>{
pairRDD.filter(one=>{
println("*********** filter *********")
true
})
pairRDD.foreach(println)
})
ssc
}
}
小练习:
import java.io.{File, FileInputStream, FileOutputStream}
import java.util.UUID
/**
* 将项目中的 ./data/copyFileWord 文件 每隔5s 复制到 ./data/streamingCopyFile 路径下
*/
object CopyFileToDirectory {
def main(args: Array[String]): Unit = {
while(true){
Thread.sleep(5000);
val uuid = UUID.randomUUID().toString();
println(uuid);
copyFile(new File("./data/copyFileWord"),new File(".\\data\\streamingCopyFile\\"+uuid+"----words.txt"));
}
}
/**
* 复制文件到文件夹目录下
*/
def copyFile(fromFile: File, toFile: File): Unit ={
val ins = new FileInputStream(fromFile);
val out = new FileOutputStream(toFile);
val buffer = new Array[Byte](1024*1024)
var size = 0
while (size != -1) {
out.write(buffer, 0, buffer.length);
size = ins.read(buffer)
}
ins.close();
out.close();
}
}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Durations, StreamingContext}
/**
* sparkStreamig监控某个文件夹时,不需要设置local[2],没有采用 receiver 接收器的模式读取数据
* 以下是监控 ./data/streamingCopyFile 目录下的文件
*
* SpakrStreaming 监控某个目录下的文件,这个文件必须是原子性的在目录中产生,已经存在的文件后面追加数据不能被监控到,被删除的文件也不能被监控到
*/
object SparkSteamingMonitorDirectory {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("monitorFile")
val ssc = new StreamingContext(conf,Durations.seconds(10))
ssc.sparkContext.setLogLevel("Error")
val lines: DStream[String] = ssc.textFileStream("./data/streamingCopyFile")
val words: DStream[String] = lines.flatMap(line=>{line.trim.split(" ")})
val pairWords: DStream[(String, Int)] = words.map(word=>{(word.trim,1)})
val result: DStream[(String, Int)] = pairWords.reduceByKey((v1:Int, v2:Int)=>{v1+v2})
result.print()
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}