hadoop的单机版测试和集群节点的搭建
Hadoop技术原理:
- Hdfs主要模块:NameNode、DataNode
- Yarn主要模块:ResourceManager、NodeManager
HDFS主要模块及运行原理:
1)NameNode:
- 功能:是整个文件系统的管理节点。维护整个文件系统的文件目录树,文件/目录的元数据和
每个文件对应的数据块列表。接收用户的请求。
2)DataNode:
- 功能:是HA(高可用性)的一个解决方案,是备用镜像,但不支持热备
一、hadoop单机版测试
- 建立用户,设置密码
[root@server1 ~]# useradd -u 1000 hadoop
[root@server1 ~]# passwd hadoop
- hadoop的安装配置
##切换到hadoop用户解压安装包
[root@server1 ~]# mv hadoop-3.0.3.tar.gz jdk-8u181-linux-x64.tar.gz /home/hadoop
[root@server1 ~]# su - hadoop
[hadoop@server1 ~]$ ls
hadoop-3.0.3.tar.gz jdk-8u181-linux-x64.tar.gz
[hadoop@server1 ~]$ tar zxf jdk-8u181-linux-x64.tar.gz
[hadoop@server1 ~]$ ln -s jdk1.8.0_181/ java
[hadoop@server1 ~]$ tar zxf hadoop-3.0.3.tar.gz
[hadoop@server1 ~]$ ln -s hadoop-3.0.3 hadoop
[hadoop@server1 ~]$ ls
hadoop hadoop-3.0.3.tar.gz jdk1.8.0_181
hadoop-3.0.3 java jdk-8u181-linux-x64.tar.gz
- 配置环境变量
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server1 hadoop]$ vim hadoop-env.sh
54 export JAVA_HOME=/home/hadoop/java
[hadoop@server1 ~]$ vim .bash_profile
PATH=$PATH:$HOME/.local/bin:$HOME/bin:$HOME/java/bin
[hadoop@server1 ~]$ source .bash_profile
[hadoop@server1 ~]$ jps ##配置成功可以调用
2518 Jps
- 测试
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ mkdir input
[hadoop@server1 hadoop]$ cp etc/hadoop/*.xml input/
[hadoop@server1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar grep input output 'dfs[a-z.]+'
[hadoop@server1 hadoop]$ cd output/
[hadoop@server1 output]$ ls
part-r-00000 _SUCCESS
[hadoop@server1 output]$ cat *
1 dfsadmin
二、伪分布式
- 编辑文件
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server1 hadoop]$ vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
[hadoop@server1 hadoop]$ vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value> ##自己充当节点
</property>
</configuration>
- 生成密钥做免密连接
[hadoop@server1 hadoop]$ ssh-keygen
[hadoop@server1 hadoop]$ ssh-copy-id localhost
[hadoop@server1 ~]$ exit
logout
Connection to localhost closed.
- 格式化,并开启服务
[hadoop@server1 hadoop]$ bin/hdfs namenode -format
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ cd sbin/
[hadoop@server1 sbin]$ ./start-dfs.sh
[hadoop@server1 sbin]$ jps
2675 NameNode
2787 DataNode
3114 Jps
2971 SecondaryNameNode
-
浏览器查看http://172.25.14.1:9870
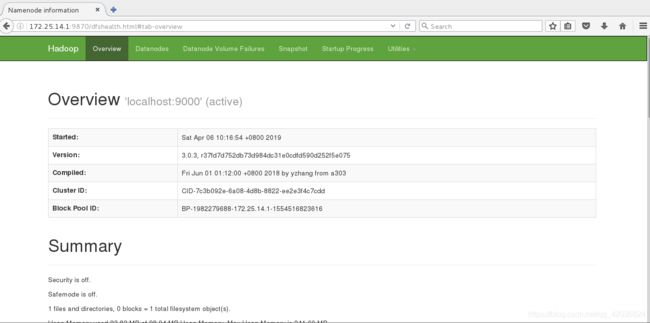
-
测试,创建目录,并上传
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir -p /user/hadoop
[hadoop@server1 hadoop]$ bin/hdfs dfs -ls
[hadoop@server1 hadoop]$
[hadoop@server1 hadoop]$ bin/hdfs dfs -put input
[hadoop@server1 hadoop]$ bin/hdfs dfs -ls
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2019-04-06 10:23 input
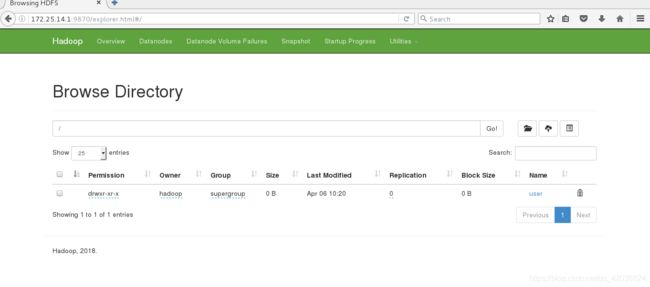
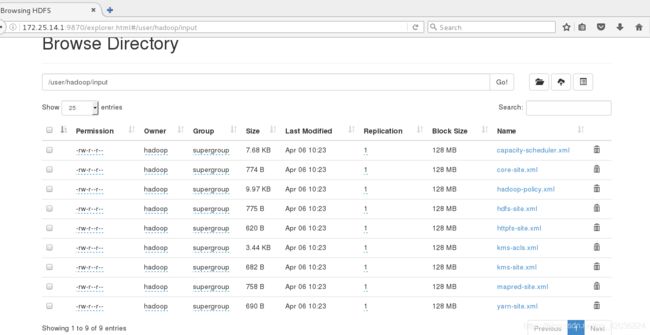
- 删除input和output文件,重新执行命令
[hadoop@server1 hadoop]$ rm -fr input/ output/
[hadoop@server1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar grep input output 'dfs[a-z.]+'
[hadoop@server1 hadoop]$ ls
bin etc include lib libexec LICENSE.txt logs NOTICE.txt README.txt sbin share
**此时input和output不会出现在当前目录下,而是上传到了分布式文件系统中,网页上可以看到**
[hadoop@server1 hadoop]$ bin/hdfs dfs -cat output/*
1 dfsadmin
[hadoop@server1 hadoop]$ bin/hdfs dfs -get output ##从分布式系统中get下来output目录
[hadoop@server1 hadoop]$ cd output/
[hadoop@server1 output]$ ls
part-r-00000 _SUCCESS
[hadoop@server1 output]$ cat *
1 dfsadmin
三、分布式
- 先停掉服务,清除原来的数据
[hadoop@server1 hadoop]$ sbin/stop-dfs.sh
[hadoop@server1 hadoo
13867 Jps
[hadoop@server1 ~]$ cd /tmp
[hadoop@server1 tmp]$ ls
hadoop hadoop-hadoop hsperfdata_hadoop
[hadoop@server1 tmp]$ rm -fr *
- 新开两个虚拟机,当做节点
##创建用户
[root@server2 ~]# useradd -u 1000 hadoop
[root@server3 ~]# useradd -u 1000 hadoop
##安装nfs-utils
[root@server1 ~]# yum install -y nfs-utils
[root@server2 ~]# yum install -y nfs-utils
[root@server3 ~]# yum install -y nfs-utils
[root@server1 ~]# systemctl start rpcbind
[root@server2 ~]# systemctl start rpcbind
[root@server3 ~]# systemctl start rpcbind
- server1开启服务,配置
[root@server1 ~]# systemctl start nfs-server
[root@server1 ~]# vim /etc/exports
/home/hadoop *(rw,anonuid=1000,anongid=1000)
[root@server1 ~]# exportfs -rv
exporting *:/home/hadoop
[root@server1 ~]# showmount -e
Export list for server1:
/home/hadoop *
- server2,3挂载
[root@server2 ~]# mount 172.25.14.1:/home/hadoop /home/hadoop
[root@server2 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/rhel-root 17811456 1097752 16713704 7% /
devtmpfs 497292 0 497292 0% /dev
tmpfs 508264 0 508264 0% /dev/shm
tmpfs 508264 13128 495136 3% /run
tmpfs 508264 0 508264 0% /sys/fs/cgroup
/dev/sda1 1038336 141508 896828 14% /boot
tmpfs 101656 0 101656 0% /run/user/0
172.25.14.1:/home/hadoop 17811456 2797184 15014272 16% /home/hadoop
[root@server3 ~]# mount 172.25.14.1:/home/hadoop /home/hadoop
- 此时发现可以免密登录(因为是挂载上的)
[root@server1 ~]# su - hadoop
Last login: Sat Apr 6 10:12:17 CST 2019 from localhost on pts/1
[hadoop@server1 ~]$ ssh 172.25.14.2
[hadoop@server2 ~]$ logout
Connection to 172.25.14.2 closed.
[hadoop@server1 ~]$ ssh 172.25.14.3
[hadoop@server3 ~]$ logout
Connection to 172.25.14.3 closed.
- 重新编辑文件
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server1 hadoop]$ vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.25.14.1:9000</value>
</property>
</configuration>
[hadoop@server1 hadoop]$ vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value> ##改为两个节点
</property>
</configuration>
[hadoop@server1 hadoop]$ vim workers
[hadoop@server1 hadoop]$ cat workers
172.25.14.2
172.25.14.3
##在一个地方编辑,其他节点都有了
[root@server2 ~]# su - hadoop
Last login: Sat Apr 6 11:32:41 CST 2019 from server1 on pts/1
[hadoop@server2 ~]$ cd hadoop/etc/hadoop/
[hadoop@server2 hadoop]$ cat workers
172.25.14.2
172.25.14.3
[root@server3 ~]# su - hadoop
Last login: Sat Apr 6 11:32:41 CST 2019 from server1 on pts/1
[hadoop@server3 ~]$ cd hadoop/etc/hadoop/
[hadoop@server3 hadoop]$ cat workers
172.25.14.2
172.25.14.3
- 格式化,并启动服务
[hadoop@server1 hadoop]$ bin/hdfs namenode -format
[hadoop@server1 hadoop]$ sbin/start-dfs.sh
Starting namenodes on [server1]
Starting datanodes
Starting secondary namenodes [server1]
[hadoop@server1 hadoop]$ jps
14085 NameNode
14424 Jps
14303 SecondaryNameNode ##出现SecondaryNameNode
##从节点可以看到datanode信息
[hadoop@server2 ~]$ jps
11959 DataNode
12046 Jps
[hadoop@server3 ~]$ jps
2616 DataNode
2702 Jps
- 测试
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir -p /user/hadoop
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir input
[hadoop@server1 hadoop]$ bin/hdfs dfs -put etc/hadoop/*.xml input
[hadoop@server1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar grep input output 'dfs[a-z.]+'
- 网页上查看,有两个节点,且数据已经上传
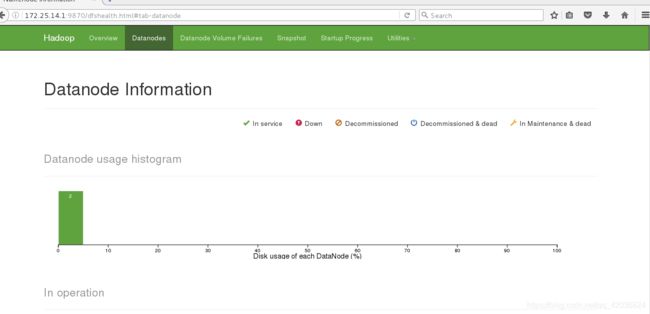
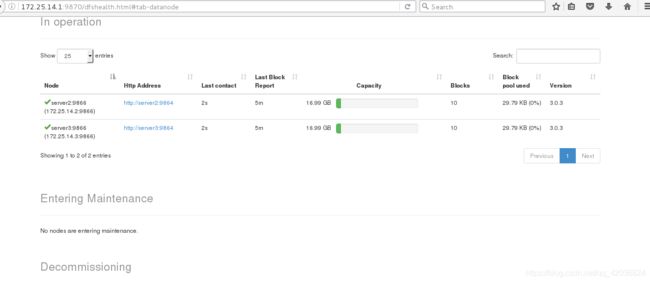
server4模拟客户端
[root@server4 ~]# useradd -u 1000 hadoop
[root@server4 ~]# yum install -y nfs-utils
[root@server4 ~]# systemctl start rpcbind
[root@server4 ~]# mount 172.25.14.1:/home/hadoop /home/hadoop
[root@server4 ~]# su - hadoop
[hadoop@server4 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server4 hadoop]$ vim workers
172.25.14.2
172.25.14.3
172.25.14.4
[hadoop@server4 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server4 hadoop]$ sbin/hadoop-daemon.sh start ##开启datanode节点服务datanode
[hadoop@server4 hadoop]$ jps
2609 Jps
2594 DataNode
- 浏览器查看,节点添加成功
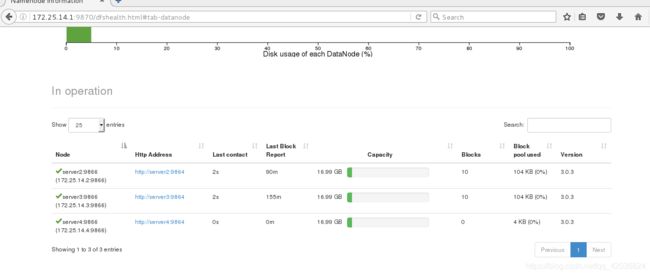
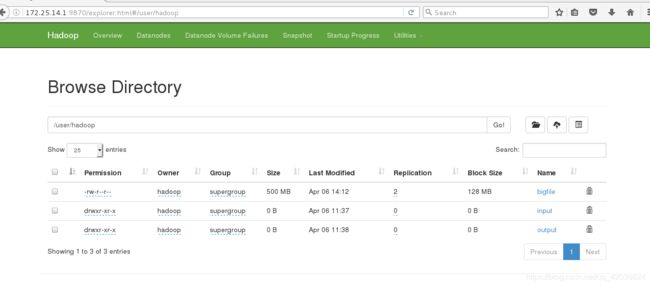
[hadoop@server4 hadoop]$ dd if=/dev/zero of=bigfile bs=1M count=500
500+0 records in
500+0 records out
524288000 bytes (524 MB) copied, 25.8653 s, 20.3 MB/s
[hadoop@server4 hadoop]$ bin/hdfs dfs -put bigfile
- 显示bigfile已经上传成功