【详解】JVM——内存结构之方法区
目录
- 定义
- 组成
- 常量池、运行时常量池
- 内存溢出问题
- 可能出现的场景
- 运行时常量池
- StringTable
- 先看几道面试题:
- 演示代码
- 特点
- 面试题答案
- StringTable 位置
- StringTable 垃圾回收
- 观察下面案例
- StringTable 性能调优
- 观察下面案例
- 观察下面案例
定义
- 是所有Java虚拟机线程共享的区
- 存储了跟
类的结构相关的信息,包括方法,构造器,成员属性,运行时常量池等 在虚拟机启动时被创建- 逻辑上是堆的组成部分(并不强制所有的厂商按照这一条,1.8以前用的堆内存,1.8以后用的是系统内存)
- 方法区也会导致内存溢出
组成

1.6采用的是永久代实现了方法区,1.8采用了元空间实现方法区,在本地内存实现。
常量池、运行时常量池
常量池
- 即class文件常量池,是class文件的一部分,用于保存编译时确定的数据,如下图所示

运行时常量池
-
Java语言并不要求常量一定只能在编译期产生,
运行期间也可能产生新的常量,这些常量被放在运行时常量池中。 -
类加载后,常量池中的数据会在运行时常量池中存放!
-
这里所说的常量包括:
基本类型包装类(包装类不管理浮点型,整形只会管理-128到127)和String(也可以通过String.intern()方法可以强制将String放入常量池)
内存溢出问题
代码演示:
import jdk.internal.org.objectweb.asm.ClassWriter;
import jdk.internal.org.objectweb.asm.Opcodes;
/**
* 演示元空间内存溢出 java.lang.OutOfMemoryError: Metaspace
* -XX:MaxMetaspaceSize=8m
*/
public class Demo1_8 extends ClassLoader { // 可以用来加载类的二进制字节码
public static void main(String[] args) {
int j = 0;
try {
Demo1_8 test = new Demo1_8();
for (int i = 0; i < 10000; i++, j++) {
// ClassWriter 作用是生成类的二进制字节码
ClassWriter cw = new ClassWriter(0);
// 版本号, public, 类名, 包名, 父类, 接口
cw.visit(Opcodes.V1_8, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/Object", null);
// 返回 byte[]
byte[] code = cw.toByteArray();
// 执行了类的加载
test.defineClass("Class" + i, code, 0, code.length); // Class 对象
}
} finally {
System.out.println(j);
}
}
}

可能出现的场景
- Spring
- mybatis
运行时常量池
-
一个类执行时会先编译成字节码文件,包含类的基本信息,常量池,类方法定义,包含虚拟机指令
-
可以利用javap -v xxxx.class,反编译字节码文件
-
类方法定义区,会去常量池找对应的常量及其类型
-
常量池的作用给虚拟机指令提供各个常量的符号定义,方便类方法指令去查找
-
常量池,就是一张表,虚拟机指令根据这张**常量表**找到要执行的类名、方法名、参数类型、字面量等信息 -
运行时常量池,常量池是 *.class 文件中的,当该类被加载,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址
StringTable
先看几道面试题:
String s1 = "a";
String s2 = "b";
String s3 = "a" + "b";
String s4 = s1 + s2;
String s5 = "ab";
String s6 = s4.intern();
// 问
System.out.println(s3 == s4);
System.out.println(s3 == s5);
System.out.println(s3 == s6);
String x2 = new String("c") + new String("d");
String x1 = "cd";
x2.intern();
// 问,如果调换了【最后两行代码】的位置呢,如果是jdk1.6呢
System.out.println(x1 == x2);
演示代码
// StringTable [ "a", "b" ,"ab" ] hashtable 结构,不能扩容
public class Demo1_22 {
// 常量池中的信息,都会被加载到运行时常量池中, 这时 a b ab 都是常量池中的符号,还没有变为 java 字符串对象
// ldc #2 会把 a 符号变为 "a" 字符串对象
// ldc #3 会把 b 符号变为 "b" 字符串对象
// ldc #4 会把 ab 符号变为 "ab" 字符串对象
public static void main(String[] args) {
String s1 = "a"; // 懒惰的
String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2; // new StringBuilder().append("a").append("b").toString() 相当于new String("ab")
String s5 = "a" + "b"; // javac 在编译期间的优化,结果已经在编译期确定为ab
System.out.println(s3 == s5);
}
}
/**
* 演示字符串字面量也是【延迟】成为对象的
*/
public class TestString {
public static void main(String[] args) {
int x = args.length;
System.out.println(); // 字符串个数 2275
System.out.print("1");
System.out.print("2");
System.out.print("3");
System.out.print("4");
System.out.print("5");
System.out.print("6");
System.out.print("7");
System.out.print("8");
System.out.print("9");
System.out.print("0");
System.out.print("1"); // 字符串个数 2285,可以看出,只有当遇到时才进行创建,具有延迟加载特性
System.out.print("2");
System.out.print("3");
System.out.print("4");
System.out.print("5");
System.out.print("6");
System.out.print("7");
System.out.print("8");
System.out.print("9");
System.out.print("0");
System.out.print(x); // 字符串个数
}
}
特点
- 数据结构为哈希表,不能扩容
- 先去串池中找,如果没有就会创建该字符串
- 用到某个字符串,才会去创建它,不会提前创建
- 每一个字符串,在串池中是唯一的(key是唯一的)
- 编译期会对 “ + ”进行优化,如果结果已经在编译期确定,则可以直接提前拼接好;但是变量的拼接,无法保证变量是不可变的,则需要通过StringBuilder拼接生成
- 常量池中的字符串仅是符号,第一次用到时才变为对象,具有延迟加载特性
- 利用串池的机制,来避免重复创建字符串对象
- 字符串变量拼接的原理是 StringBuilder (1.8)
public class Demo1_23 {
// ["ab", "a", "b"]
public static void main(String[] args) {
String s = new String("a") + new String("b");
String x = "ab";
// 堆 new String("a") new String("b") new String("ab")
String s2 = s.intern(); // 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池, 会把串池中的对象返回
System.out.println( s2 == x);//true
System.out.println( s == x );//false,
}
}
通过动态拼接形成的字符串,只存在堆中,可以使用 intern 方法,主动将串池中还没有的字符串对象放入串池
1.8 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池,会把串池中的对象返回
1.6 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有会把此对象复制一份,放入串池, 会把串池中的对象返回
intern()的使用,如果串池中没有该字符串,因为串池中放的就是s的对象,则一定返回的还是s;但是如果串池中已经存在,则该对象不会放在串池中,但是返回的对象是串中的ab,则一定不相等
如果是jdk1.6,则一定返回的不是s的对象,一定不相等
面试题答案
/**
* 演示字符串相关面试题
*/
public class Demo1_21 {
public static void main(String[] args) {
String s1 = "a";
String s2 = "b";
String s3 = "a" + "b"; // ab
String s4 = s1 + s2; // new String("ab")
String s5 = "ab";
String s6 = s4.intern();
// 问
System.out.println(s3 == s4); // false
System.out.println(s3 == s5); // true
System.out.println(s3 == s6); // true
String x2 = new String("c") + new String("d"); // new String("cd")
x2.intern();
String x1 = "cd";
// 问,如果调换了【最后两行代码】的位置呢,如果是jdk1.6呢
System.out.println(x1 == x2);
}
}
注意:intern方法只是尝试入池
StringTable 位置
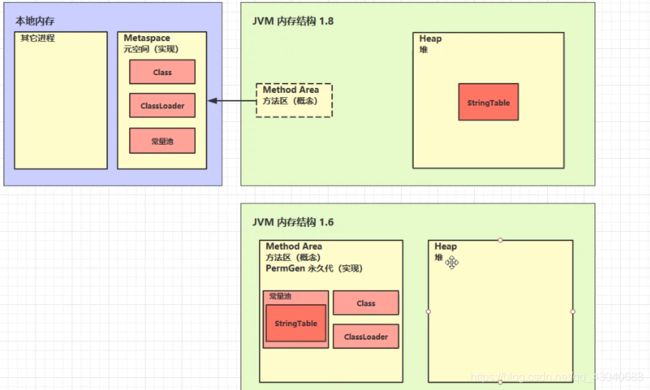 这样做的目的是因为永久代回收效率太低,而常量池使用特别频繁,容易造成永久代空间溢出。所以最后转到了堆中。
这样做的目的是因为永久代回收效率太低,而常量池使用特别频繁,容易造成永久代空间溢出。所以最后转到了堆中。
案例实验,可以根据内存溢出错误的提示判断常量池在哪个地方,如下面代码所示:
/**
* 演示 StringTable 位置
* 在jdk8下设置 -Xmx10m -XX:-UseGCOverheadLimit
* 在jdk6下设置 -XX:MaxPermSize=10m
*/
public class Demo1_6 {
public static void main(String[] args) throws InterruptedException {
List<String> list = new ArrayList<String>();
int i = 0;
try {
for (int j = 0; j < 260000; j++) {
list.add(String.valueOf(j).intern());
i++;
}
} catch (Throwable e) {
e.printStackTrace();
} finally {
System.out.println(i);
}
}
}
StringTable 垃圾回收
观察下面案例
/**
* 演示 StringTable 垃圾回收
* -Xmx10m -XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:gc
*/
public class Demo1_7 {
public static void main(String[] args) throws InterruptedException {
int i = 0;
try {
for (int j = 0; j < 100000; j++) { // j=100, j=10000
String.valueOf(j).intern();
i++;
}
} catch (Throwable e) {
e.printStackTrace();
} finally {
System.out.println(i);
}
}
}
- XX:+PrintStringTableStatistics 打印字符串表的详细信息
- -XX:+PrintGCDetails -verbose:gc 是打印垃圾回收的详细信息
StringTable statistics:
Number of buckets : 65536 = 524288 bytes, each 8
Number of entries : 28042 = 448672 bytes, each 16
Number of literals : 28042 = 969296 bytes, avg 34.000
Total footprint : = 1942256 bytes
Average bucket size : 0.428
Variance of bucket size : 0.529
Std. dev. of bucket size: 0.727
Maximum bucket size : 5
- Number of entries 存储的字符串对象
StringTable 性能调优
主要调整桶的个数
观察下面案例
/**
* 演示串池大小对性能的影响
* -Xms500m -Xmx500m -XX:+PrintStringTableStatistics -XX:StringTableSize=1009
*/
public class Demo1_24 {
public static void main(String[] args) throws IOException {
//linux.words有48万的单词
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("linux.words"), "utf-8"))) {
String line = null;
long start = System.nanoTime();
while (true) {
line = reader.readLine();
if (line == null) {
break;
}
line.intern();
}
System.out.println("cost:" + (System.nanoTime() - start) / 1000000);
}
}
}
- 调整 -XX:StringTableSize=桶个数
- 桶个数越小,效率越低,因为StringTable的数据结构实现是HashTable,桶的个数越大,会有更好hash分布,减少hash冲突
观察下面案例
/**
* 演示 intern 减少内存占用
* -XX:StringTableSize=200000 -XX:+PrintStringTableStatistics
* -Xsx500m -Xmx500m -XX:+PrintStringTableStatistics -XX:StringTableSize=200000
*/
public class Demo1_25 {
public static void main(String[] args) throws IOException {
List<String> address = new ArrayList<>();
System.in.read();
for (int i = 0; i < 10; i++) {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("linux.words"), "utf-8"))) {
String line = null;
long start = System.nanoTime();
while (true) {
line = reader.readLine();
if(line == null) {
break;
}
address.add(line.intern());
}
System.out.println("cost:" +(System.nanoTime()-start)/1000000);
}
}
System.in.read();
}
}
- 考虑将字符串是否入池
- 将字符串入池,可以将重复的字符串都保存在一个串池中的地方,再将串池中的对象返回,重复的字符串都会被垃圾回收掉