移动直播连麦实现——Server端合成
本文为《程序员》原创文章,未经允许不得转载,更多精彩文章请订阅2017年《程序员》
作者简介: 张亚伟,齐聚科技技术研究院技术总监,拥有多年跨平台直播开发经验与技术积累。
责编:屠敏,欢迎技术投稿、约稿、给文章纠错,请发送邮件至[email protected]。
导语:本文是移动直播连麦实现系列的第二篇,分享由Server端(UpServer)执行音视频合成的流程及细节。此前我们介绍了移动直播连麦实现思路的整体情况,包括音视频合成的几种实现思路,参与连麦的客户端角色和服务器角色,内容详情见《移动直播连麦实现思路:整体篇》。
本文章内容包括有UpServer音视频合成、A主播音视频合成、B主播音视频合成,以及时间戳应用介绍等小节,首先解析较为复杂的视频合成,后详解容易些的音频合成。
使用Server端(UpServer)合成音视频后,UpServer把合成好的数据流推送给DeliveryServer集群,再由DeliveryServer分发给移动直播的所有观众。DeliveryServer集群及后续的推送工作不涉及音视频合成,与连麦无关,不属于本文关注的范围,不再描述,结构图也仅绘制到DeliveryServer,望大家了解。
UpServer视频合成
视频是由分辨率、帧率、颜色空间、显示位置等基本参数定义的,在视频合成处理前,这些参数都要确定。为方便说明UpServer视频合成流程,参考当前移动直播连麦的常见情况,对视频参数预先定义如下。
- A主播视频数据的高和宽为640*360(16:9),置于底层全屏显示。
- B主播视频数据的高和宽均为160*120(4:3),显示位置都在顶层。
- 当有多个B主播视频时,B1/B2/B3主播的显示位置在右侧依次排列,每个主播间隔1像素,下部边缘保留100像素。
- 在水平方向,所有B主播都靠右侧显示,不留空隙。
- 显示顺序上既可以B1在下部,也可以B3在下部,但很多情况下只有1个B主播连麦,故一般安排B1在下部显示,好处是对A主播视频显示的影响最小。
- A主播、B主播的视频帧率都是每秒20帧,颜色空间都是I420。
以上参数不仅在UpServer合成视频时需要使用,在A主播、各B主播视频合成时也需要使用。
如A主播、B主播分辨率不符合上述定义,则需要先进行适当的缩放;如颜色空间不一致,也需要先进行转换。注意,视频数据的高和宽与显示的高和宽是不同的,在纵横比相同时,通过OpenGL自身的缩放即可实现视频图像的绘制,针对特殊屏幕分辨率的适配也有额外工作量。
视频帧率有差异,为简化操作无需插帧,可按A主播的视频帧率进行合成,即B1/B2/B3的视频都合成到A主播的视频图像上,A主播的视频帧率就是合成后的视频帧率了。以A主播视频图像为底图进行合并,若A主播没有视频数据则合成暂停,若某个B主播没有新的视频数据,则仍然复用上一帧,从效果上看就是该B主播视频卡住了。
视频图像在内存中都是按行存储的,有左下角或左上角为起点两种情况,即常说的左底结构和左顶结构,具体遇到的是哪种结构试试便知。同时还要需要注意,颜色空间I420中YUV是分成多个平面存储的,在合成图像时每个平面要单独处理,Y平面和UV平面的行数、列数也是不同的。
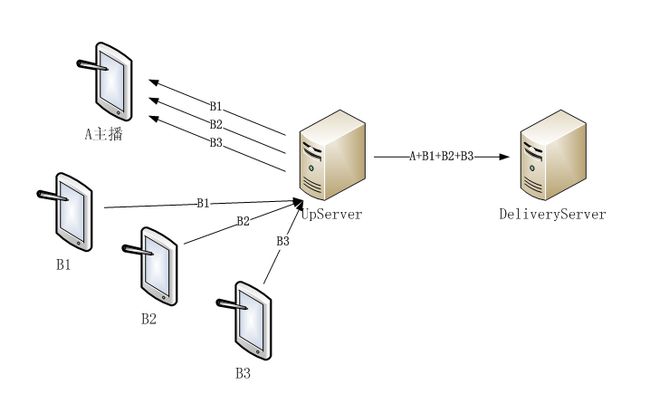
以下我们的举例中,视频图像存储以左上角为起点(左顶结构),图像缓存复用角色定义,分别用A、B1、B2、B3代表,合成后的视频图像存储在VideoMixer中。当UpServer分别收到A、B1、B2、B3的视频数据流,并解码得到每一帧图像后就可以进行视频合成了,如图1所示。

UpServer合成视频的基本流程描述如下。
- 首先根据音视频同步情况,读取A主播的视频数据作为合成底图,有成功和失败两种情况,如读取成功接第4步,失败则见第2步。
- 当读取A主播视频图像数据失败时,仍然要按音视频同步情况读取所有B主播的视频数据,若读取成功则需要丢弃该视频帧,避免后续合成时使用该帧造成的不同步现象。
- 当所有B主播视频数据都读取完成后,本轮视频合成就以失败结束了,视频合成依赖底图,无A主播视频就无法进行合成。
- 拷贝A图像上部的58行到VidoeMixer中,行数计算公式是640-160*3-1*2-100=58,各项数值的意义请参考参数定义,大家应该已理解就不单独解释了。
- 接着读取B3主播的视频数据进行合成,也有成功和失败两种情况,如成功接第7步,失败也分为两种情况,一是有上一帧,二是没有。如有也是执行第7步,如没有或不存在B3主播则见第6步。
- 如读取B3视频失败且上一帧不存在,或者不存在该主播,则直接拷贝A的视频图像161(160+1)行到VidoeMixer中。
- 如读取B3视频数据成功或有上一帧,则把B3和A主播视频图像按行进行合成,每行要分成2段进行拷贝,第一段拷贝A视频数据到VidoeMixer中,拷贝列数360-120=240;第二段拷贝B3视频数据到VidoeMixer中,120列。
- 如读取B3视频数据成功,合成之后还要备份B3的视频数据到指定位置,用于下次读取失败时复用上一帧;当B3主播停止连麦或较长时间卡顿后,还需要清除该数据缓存,避免引起歧义。
- 接下来拷贝B3、B2之间间隔部分,即A的视频数据到VidoeMixer中,1行。
- 循环5-9步过程,把B2、B2与B1间隔(A的1行)的视频数据拷贝到VidoeMixer中;再循环一次,把B1、B1下部(A的100行)的视频数据拷贝到VidoeMixer中。
- 使用上述流程,就完成了“A+B1+B2+B3”视频图像合成,合成结果已存储在VidoeMixer中。
生成“A+B1+B2+B3”视频图像后,UpServer需要把该视频数据流编码、打包,并发送给DeliveryServer,用于移动直播用户观看连麦视频。
A主播也需要观看其他B主播的视频,但是否使用“A+B1+B2+B3”的视频图像需要讨论,方法不同复杂度也不尽相同,具体将在A主播视频合成小节中说明。每个B主播也要显示A主播和其他B主播视频,个人认为使用“A+B1+B2+B3”的视频数据流就可以满足需求,具体细节在B主播视频合成小节中讲述。
A主播视频
A主播的视频数据处理分为发送、接收、显示三个部分,发送环节包括采集、编码、打包、发送,接收环节包括接收、按时间戳同步、解包、解码,显示环节包括本地视频图像和远端视频图像的合成及显示。
发送部分,由UpServer负责合成视频时,A主播需要把采集到的本地视频编码,并按指定封装格式打包,然后发送给UpServer,流程结构如图1所示。该部分与直播连麦关系不大,与单一主播直播时流程一致。
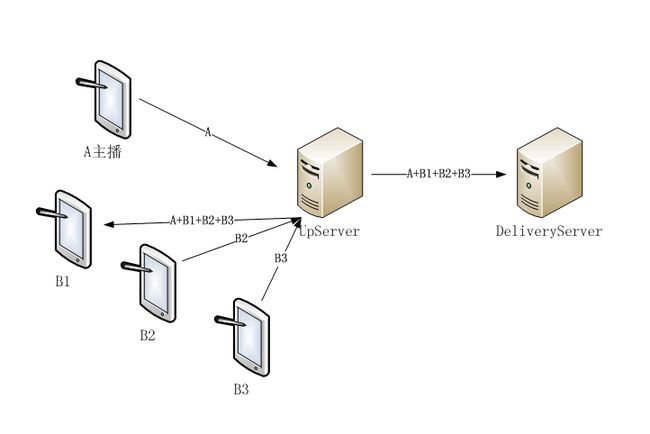
A主播接收部分,如图2所示,先接收UpServer推送的B主播视频数据,然后按时间戳同步读取、解包、解码。UpServer为A主播推送的视频数据内容可以有以下三种,若数据内容不同,合成显示部分的处理流程也不同。
- 第一种,UpServer推送合成好的所有视频数据“A+B1+B2+B3”,与推送给普通观众的视频相同;
- 第二种,B1/B2/B3视频数据流独立推送,即UpServer直接转发各B主播的视频给A主播;
- 第三种,UpServer把B1/B2/B3视频按尺寸和显示位置合成为一路视频数据流,并把该路视频数据流推送给A主播。
下面分享A主播的合成显示部分,结合上面讲到的A主播接收的3种视频数据流形式,分别描述和比较它们的优劣。
先简单介绍个人不建议的形式,由UpServer按视频尺寸和显示位置把多个B主播的视频合成一路视频流,该方式的缺点是UpServer的压力显著增加。UpServer已为每个连麦进行了视频合成工作,再为A主播另外合成一路,在视频合成和编码发送方面,承担了更多的压力,本身Server端合成最大的瓶颈就是UpServer服务器的处理能力,故任何增加其负担的行为都应该被摒弃。同时,该方式下A主播自身的解码、合成流程也没有什么变化,CPU使用基本未减少,故不建议采用。
接着介绍UpServer推送合成好的所有视频“A+B1+B2+B3”给A主播的形式,此时UpServer仅增加了一路数据流推送,而没有更多的消耗,属于可以接受的方式。但该方式对A主播的图像合成压力比较大,为保证本地视频的实时性,底图的A视频图像必须使用刚刚采集的,所以合成图像前需要先抠图。具体步骤如下:
- 把“A+B1+B2+B3”中的A扣掉,得到B1、B2、B3独立的3个视频;由于视频是按行存储的,所以获取独立视频的过程也只能是循环遍历每行,得到所需要的视频数据。
- 使用最新采集到的A主播视频,合并上面得到的B1、B2、B3视频,按第一节讲解的视频图像合成再来一次,得到 “新A+B1+B2+B3”。
该方式下,后续的显示流程差异不大,通过OpenGL把“新A+B1+B2+B3”绘制到UI即可。
最后UpServer直接转发各B主播视频给A主播的方式,该方法的问题是推送三路数据流时,A主播的网络丢包(接收丢包)、时间戳同步控制更麻烦,但在解码、合成方面则问题不大,且UpServer服务器增加的压力也非常微小。具体实现流程可以参考第一节的视频图像合成介绍。
总结,在UpServer推送B主播视频数据时,比较后建议选择第一种或第二种方法,特别是UpServer直接转发各B主播视频给A主播的方式(第二种),原因是第一种推送合成好的所有视频“A+B1+B2+B3”给A主播的形式有个瑕疵——如B2主播连麦一段时间后停止了,UpServer和A主播收到该消息的时间是有先后差异的,会出现两种情况:
- UpServer停止合成B2视频,但A主播仍然合成和显示;A主播抠取B2视频时,得到的是A主播的图像,这样在A主播合成B2区域时,使用的就是A主播自身的历史图像了。
- UpServer未停止绘制B2视频,但A主播不再绘制,则A主播会看不到B2的最后几帧视频。
以上两种情况,是由于消息接收和处理时间差异造成的,故会非常短暂,仅属于瑕疵。使用UpServer直接转发各B主播视频给A主播的方式,由于每路数据流是独立的,故不存在该瑕疵。
B主播视频
B主播视频的处理过程主要分为发送、接收显示两个部分。发送部分也是采集、编码、打包、发送,与A主播流程一致。在接收显示方面与A主播相比,B主播视频显示在合成好的所有视频顶层,故处理过程相对简单一些。以B1主播举例,有两种方式:
- 第一种,UpServer推送合成好的所有视频“A+B1+B2+B3”,与推送给普通观众的视频流相同,如图3所示;
- 第二种,A主播、B2、B3主播视频数据流独立推送,即UpServer直接转发其他主播的视频给B1主播。
先说排除的方法,A主播、B2、B3主播视频数据流独立推送,该方法没有明显优点,若音频也是独立发送,则音视频同步方面可能稍好;缺点是B1主播需要接收3路视频数据流,且都要按时间戳同步读取数据、解码和合成图像,故B1主播消耗的CPU更高一些。
其次,UpServer推送合成好的所有视频“A+B1+B2+B3”给B1的方法,该方法B1主播仅需读取一路数据和解码,之后数据合成也仅是把B1位置的远端视频替换为本地采集的,操作简单易行;在该方法下,合成视频的音视频同步可参考A主播音频完成,细节详见后续小节。
综上所述,建议选择UpServer推送合成好的所有视频数据流给B1主播的方法,实现B1观看其他连麦主播视频。B2、B3主播的实现与B1主播相同。
UpServer音频合成
音频也是由一些基本参数进行定义的,包括采样频率、采样点占位数、通道数、每帧长度等。为方便说明UpServer音频合成流程,参考移动直播连麦的常见情况,对以上参数进行定义:采样频率是48KHz,采样点占位数是16位(2字节),通道数是2(立体声),每帧长度为8192字节(便于编码),存储顺序为左右声道逐采样点交错。
音频数据流合成处理与视频相比简单一些,不区分主播类型都按以上参数采集、合成和播放,即所有主播都是一致的。
音频合成前,先介绍多人语音数据合成算法,大家知道音频合成算法有很多,如直接相加、取最大值、线性叠加后求平均、归一化混音(自适应加权混音算法)等,不同算法实现复杂度和特性各不相同,适用的场景也有很大差异。这里仅介绍较简单的音频合成算法:直接相加算法和取最大值算法,其他的算法介绍超出了本文讲解范围,请读者自行学习。
直接相加,顾名思义,是把两路音频数据直接相加到一起,由于两路数据的采样点都是16位,结果也是16位的,所以相加有数据溢出的可能,保护方法是判断数据溢出则把结果设置为最大值。该算法的缺点是容易爆音,优点是算法简单,由于数据合成导致的各路声音损失非常小。
取最大值,两路数据合成时逐采样点获取最大值,保存到合成结果中。由于数值较小的采样点被丢弃了,故该算法的缺点是声音数据失真较多;优点是算法简单,不存在溢出导致爆音的情况。
以上两种算法既适用于两路声音合成的情况,也适用于多路声音合成的情况。以下在音频数据合成时,我们默认采用直接相加算法。
各主播音频缓存复用角色定义,分别用A、B1、B2、B3代表,合成后的音频数据存储在AudioMixer中。当UpServer分别收到A、B1、B2、B3的音频数据流并解码得到每一帧数据后,就可以进行音频合成了,如图4所示。音频合成的基本流程如下。

- 先找到可以合成的音频数据,若没有就不必合成了。若只有一路音频数据,也无需合成直接拷贝其到AudioMixer中即可。
- 音频数据合成必须有两路以上,一般是先找A主播再找B1主播,依次类推,直到找到可以合成的所有音频数据。
- 通过循环遍历所有采样点,把各主播的音频数据直接相加,结果放到AudioMixer中,即完成了音频数据合成;直接相加算法需要对音频数据溢出进行保护,务必注意。
若所有主播都有声音数据,UpServer音频合成后就得到了“A+B1+B2+B3”的音频数据,之后需要把该音频数据编码、打包,并发送给DeliveryServer用于移动直播的用户收听声音。
A主播也需要听到其他B主播的声音,但不能使用“A+B1+B2+B3”的音频数据,原因在于用户体验上,A主播不希望听到自己的声音(类似回音),B主播也存在类似的问题,即所有主播都不能使用上面合成好的音频数据。
声音一旦合成,再想去除异常困难,故从“A+B1+B2+B3”的音频数据中去除A主播的声音,不进行尝试了。
为解决A主播、B主播之间收听彼此声音问题,可以使用UpServer合成指定音频数据流方法,也可以使用向每个主播独立发送音频数据,由各主播自己合成的方法。
A主播音频
下面描述下A主播音频的处理过程,由于A主播采集的声音,不必和其收听的远端声音(B1/B2/B3)进行混合,所以其处理过程与视频差异很大。
采集方面,A主播的音频采集流程相对简单,本地声音采集、编码、打包、发送给UpServer服务器即可,与移动直播是相同的。
移动直播连麦才需要的音频播放部分,接收音频数据流、解码、播放,是否需要合成取决于UpServer发送的数据流方式;大部分都是移动直播普通用户使用的环节;其中仅音频数据合成是连麦的特殊环节,这里详细讲解下。
A主播是否需要合成取决于UpServer发送的数据流方式,故先介绍UpServer推送音频数据流的可能方式:
- 方式一,合成的音频数据,即由UpServer合成“B1+B2+B3”的声音数据发送给A主播,该方式下A主播不需要合成直接播放即可;
- 方式二,独立的音频数据流,UpServer仅转发B1/B2/B3的音频数据,不进行合成,此时A主播需要合成B1/B2/B3的音频数据再进行播放,如图5所示。

方式一与移动直播用户播放时流程相同,A主播处理非常简单,但由于UpServer增加了资源消耗而不建议使用。在多个B主播连麦情况下,UpServer为A主播合成“B1+B2+B3”的音频数据,为B1主播合成“A+B2+B3”的音频数据,为B2主播合成“A+B1+B3”的音频数据,为B3主播合成“A+B1+B2”的音频数据,需要多次合成、编码和打包,复杂度上升很多,感觉得不偿失故不再介绍了。
方式二UpServer仅透明转发B1/B2/B3的音频数据,A主播需要对各B主播音频数据进行合成,合成算法复用上一节讲述的直接相加算法,合成流程也与UpServer合成音频数据的流程相同,这里不再赘述。该方式下UpServer的CPU消耗不高,但网络带宽要多用一些,考虑到音频数据流使用网络流量较低,该缺点属于可接受。
它们之间的差异,是把服务器端的合成工作,转移到主播端来做,从而降低服务器的资源使用,是个人推荐的方式。
B主播音频
在音频方面,不存在类似视频显示的主从关系,所有A主播和B主播都是平等的,故B主播音频的处理流程和逻辑,与A主播是基本一致的,差异是每个人需要接收的数据流不同,B1主播需要“A/B2/B3”的音频数据,B2主播需要“A/B1/B3”的音频数据,B3主播需要“A/B1/B2”的音频数据。
实现细节请参考上一节A主播音频合成的介绍。
时间戳
为保证接收端音视频播放时达到最好的同步效果,在使用媒体数据传输协议打包时,都需要封装上本地的毫秒级时间作为时间戳(Timestamp)。
时间戳有相对时间和绝对时间两种方式,相对时间采用4字节存储,无符号类型在50多天会发生归零和重新累计,应用时需要对这点进行保护;绝对时间采用8字节存储,不必担心归零情况,但要多使用一点网络带宽。两种方式差异不大,都可以实现音视频同步功能。
在移动直播的远端音视频播放时,时间戳具有以下几个作用:
- 为避免网络抖动产生的影响,需要对远端媒体数据先缓存后播放,而缓存数据的时间长度可以通过计算远端时间戳的差值得到。
- 音视频是否可播放的判断条件,当缓存数据时间长度达到预期,或是本地时间差值和远端时间差值达到预期,就表明可以播放音视频数据了。
- 音视频同步播放的判断条件,如以音频为基准,当音频可以播放了则比较音频时间戳和视频时间戳的偏差,在允许范围内也就该播放视频了。
由于UpServer需要先合成音视频数据,后按照媒体传输协议重新封装,故也需要再次打时间戳,而使用具体时间作为时间戳有些复杂。UpServer使用的时间戳建议有两种,分别是复用主播端时间戳,或是使用本地时间,它们各有优缺点:
本地时间,直接使用本地的毫秒级时间作为时间戳,优点是实现简单,直接获取本地时间使用即可,缺点有两个:
- 音视频数据合成、编码等会占用大量时间,如视频合成、音频不合成,由于处理速度差异,可能导致接收端音视频不同步。
- 当不需要合成数据时也需要再次修改时间戳,如音频数据仅转发时;此时网络抖动丢包等对修改时间戳可能产生严重影响。
主播时间,复用主播媒体包中封装的时间戳,优点是合成编码等处理占用的时间,不会影响接收方的音视频同步播放,缺点也有两个:
- 时间戳连续性无法保证,当音频合成时如使用A主播时间戳,但在A主播卡顿或无数据时则无法连续使用,此时其他B主播的声音仍然在不断合成中,还需要持续生成时间戳。
- 同一主播的音视频,有时需要合成数据(合成视频),有时不需要合成数据(独立发送音频),此时被合成的视频由于复用了其他主播的时间戳,与未合成的音频,两个时间戳之间没有强依赖关系了,可能造成播放时不同步。
根据以上分析,结合使用UpServer合成音视频数据流的情况,整理和总结了推荐的媒体数据传输内容及时间戳的使用情况,如表1。

表中有些是由UpServer负责合成,如“A+B1+B2+B3”,有些是UpServer透明转发的,如“B1/B2/B3”。在选择时间戳类型时存在不少困难,综合考虑后确定两种类型一起用,见时间戳列内的描述,如此选择的原因如下:
当接收方为DeliveryServer时,各主播都可能短时间没有声音数据,此时声音作为音视频同步的基准,必须要连续打时间戳,使用UpServer本地时间是最合理的;为了音视频同步,视频也就必须使用UpServer本地时间了。
当接收方是A主播时,推荐的形式是把各B主播的音视频数据直接推送给A,此时复用原时间戳是最合理和简单的;
当接收方是B主播时,推荐的形式是视频合成、音频独立;音频独立不修改时间戳比较简单,而视频合成后只能依赖A主播视频,若选择UpServer本地时间为时间戳后,音视频无法同步,由于各B主播也要收听A主播声音,故视频选择复用A主播时间戳最为恰当。
按上述建议,视频合成数据“A+B1+B2+B3”,推送给不同终端时使用的时间戳不同,给DeliveryServer的视频数据使用UpServer本地时间打时间戳,推送给各B主播时复用A主播时间戳,这样是否是最合理的选择?大家可以深入研究。
后记
针对Server端合成,笔者个人的看法是持保留态度,是否使用还请自行决定,列举已知的劣势如下。
- Server性能:UpServer需要实现音视频的解码、合成、编码,CPU使用增加较多,业务应用成本高。
- 复杂度:为了在主播、用户侧都达到最好的用户体验,各终端对数据流的要求不同,只能每个类型终端逐个适配,服务器和主播端的实现复杂度都很高。
- 时间戳:在不同数据流情况下,为实现音视频同步,不同终端需要的时间戳也是不同的,时间戳的产生和使用必须仔细推敲和详尽测试。
- 主播端性能:主播端为显示视频和播放声音也需要合成音视频,该工作要占用不少CPU资源;在A主播的性能和复杂度方面,与A主播合成相比优势微小。
了解最新移动开发相关信息和技术,请关注 mobilehub 公众微信号(ID: mobilehub)。
