CVPR2020 | CentripetalNet:48.0% AP,通过获取高质量的关键点对来提升目标检测性能...
点击上方“AI算法修炼营”,选择“星标”公众号
精选作品,第一时间送达

本文是收录于CVPR2020的目标检测的新工作,从关键点检测的角度出发进行创新,提出了向心偏移和十字星可形变卷积等创新点,在COCO数据集上以48.0%的AP胜过所有现有的Anchor-free检测器,值得学习。
论文地址:https://arxiv.org/pdf/2003.09119.pdf
代码地址:https://github.com/KiveeDong/CentripetalNet
基于关键点的检测器已经取得了不错的性能。但是,错误的关键点匹配仍然广泛存在,并且极大地影响了检测器的性能。在本文中,提出了CentripetalNet,它使用向心偏移(centripetal shift)来配对来自同一实例的角corner关键点。
具体来说,CentripetalNet预测角点的位置和向心偏移,并匹配与其偏移结果对齐的角。因为联合了位置信息,本文的方法比传统的嵌入方法更准确地匹配角点。Corner pooling 将边界框内的信息提取到边界上。为了使这些信息在角落更清晰,本文设计了一个十字星形(cross-star)可变形卷积网络来进行特征自适应。此外,通过在CentripetalNet上引入一个mask预测模块,可以在在Anchor-free目标检测器上实现实例分割任务。
在MS-COCO test-dev数据集上,CentripetalNet不仅以48.0%的AP胜过所有现有的Anchor-free检测器,而且以40.2%的Mask AP达到了与最新实例分割方法相当的性能。
简介
为了改善Anchor-based目标检测器中正负样本不平衡的问题,经典的CornerNet 提出了将边界框表示为一对角点,即,左上角和右下角的想法。基于这个想法,基于角点的检测框架逐渐引领了目标检测领域的新趋势。通常,基于角点的检测框架可以分为两个步骤,包括角点预测和角点匹配。本文的方法主要关注第二部分——角点匹配。
常规的角点匹配方法主要使用关联嵌入(associative embedding )方法对角进行配对,其中要求网络学习每个角的附加embedding,以识别两个角是否属于同一边界框。这样,如果两个角来自同一边界框,则它们将具有相似的embedding,否则,它们的embedding将完全不同。基于关联embedding的检测器在目标检测中取得了相当不错的性能,但也有一些局限性。目前通常的做法是在对角线位置的所有潜在点内找到唯一的匹配点,这样对异常值高度敏感,并且在一个训练样本中有多个相似的对象时,训练难度将急剧增加。同时,embedding预测是基于外观特征而不使用位置信息,如图1所示,如果两个对象的外观相似,则即使它们相距很远,网络也倾向于为其预测相似的embedding。
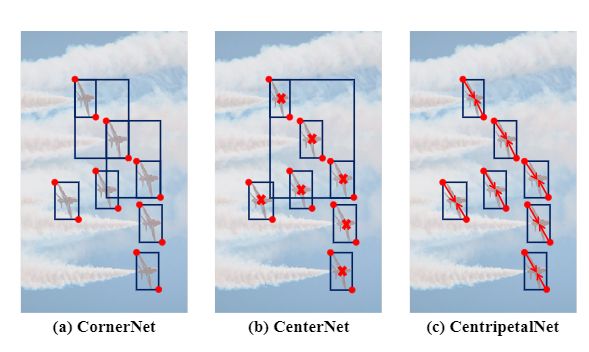
图1.(a)由于相似外观导致相似的embedding,CornerNet会生成一些错误的角点对。(b)CenterNet通过中心点预测除去了一些错误的角点对,但不能处理一些密集的情况。(c)CentripetalNet避免了CornerNet和CenterNet的缺点。
基于上述考虑,本文提出了一种基于向心偏移的角点匹配方法和十字星形可变形卷积模块,以更好地预测向心偏移,并在这基础上提出了一种新型的CentripetalNet。
针对一组角点,首先为每个角点定义了一个二维矢量,即向心偏移,用于编码从框的角到中心点的空间偏移。这样,每个角点都可以基于向心偏移生成一个中心点,因此,如果两个角属于同一边界框,则它们所生成的中心点应该是靠近的。角点匹配的质量可以由两个角点的两个中心之间的距离和几何中心来表示。结合每个角点的位置信息,与关联嵌入(associative embedding )方法相比,该方法对异常值具有鲁棒性。
此外,本文提出了一种新型的十字星可形变卷积,不仅可以学习大的感受野信息,而且可以学习“十字”的几何结构。“十字星”结构的边界包含目标对象的上下文信息,因为corner pool使用最大池化和求和运算将目标的位置信息沿“十字星”结构的边界扩展到角点上。因此,可以将目标的几何和位置信息明确地嵌入到可变形卷积的偏移字段中。与CornerNet相比,CentripetalNet模型在MS-COCO test-dev 2017上效果从42.1%AP到47.8%AP,获得了显着的性能提升。
此外,受多任务学习在目标检测中的启发,本文添加了实例分割mask分支以进一步提高准确性。将RoI Align用于量化预测出的一组感兴趣的区域(RoIs),并将其送入mask分支中以生成最终的分割预测。
CornerNet:左上角点+右下角点的检测
论文地址:https://arxiv.org/abs/1808.01244
代码地址:https://github.com/princeton-vl/CornerNet
由于Anchor会带来较多的超参数与正、负样本的不均衡,发表于ECCV 2018的CornerNet算法另辟蹊径,舍弃了传统Anchor与区域建议框的检测思路,利用关键点的检测与匹配,出色地完成了目标检测的任务。
CornerNet的思路实际是受多人体姿态估计的方法启发。在多人体姿态估计领域中,一个重要的解决思路是Bottom-Up,即先使用卷积网络检测整个图像中的关键点,然后对属于同一个人体的关键点进行拼接,形成姿态。
CornerNet将这种思想应用到了目标检测领域中,将传统的预测边框思路转化为了预测边框的左上角与右下角两个角点问题,然后再对属于同一个边框的角点进行组合,整体网络结构如下图所示。


CornerNet的主要结构主要由以下3部分组成:
沙漏结构Hourglass:特征提取的Backbone,能够为后续的网络预测提供很好的角点特征图。
角点池化Corner Pooling:作为一个特征的池化方式,角点池化可以将物体的信息整合到左上角点或者右下角点。
预测输出:传统的物体检测会预测边框的类别与位置偏移,而CornerNet则与之完全不同,其预测了角点出现的位置Heatmaps、角点的配对Embeddings及角点位置的偏移Offsets。
为了很好地理解CornerNet,下面分别详细介绍这3个模块。
1.沙漏结构:
Hourglass为了提取图像中的关键点,CornerNet使用了沙漏结构Hourglass作为网络特征提取的基础模块,其结构下图所示。
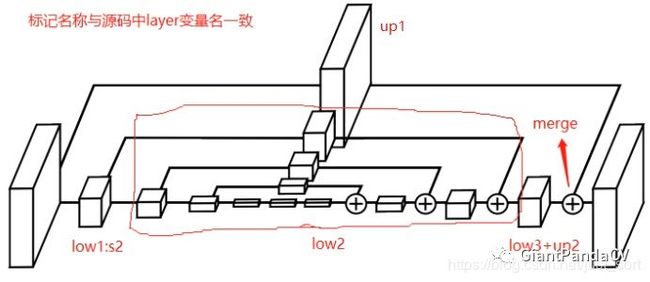
此图来自于GiantPandaCV公众号文章
从图中可以看出,Hourglass的整体形状类似于沙漏,两边大,中间小。Hourglass结构是从人体姿态估计领域中借鉴而来,通过多个Hourglass模块的串联,可以十分有效地提取人体姿态的关键点。
在图中,左半部分表示传统的卷积与池化过程,语义信息在增加,分辨率在减小。右半部分表示上采样与融合过程,深层的特征通过上采样操作与浅层的特征进行融合,在增大分辨率的同时,保留了原始的细节信息。
CornerNet首先通过一个步长为2的7×7卷积层,以及步长为2的残差模块,将图像尺寸缩小为原图的1/4,然后将得到的特征图送入两个串联的Hourglass模块。
2.角点池化:
Corner Pooling在传统卷积网络中,通常使用池化层来进行特征融合,扩大感受野,也可以起到缩小特征图尺寸的作用。以3×3的最大池化层为例,通常是以当前位置的点为中心点,融合周围共9个点的信息,取最大值输出。
然而,CornerNet的思想是利用左上与右下两个关键点进行目标检测,对于一个物体的左上点,其右下区域包含了物体的特征信息,同样对于物体的右下点,其左上区域包含了物体的特征信息,这时角点的周围只有四分之一的区域包含了物体信息,其他区域都是背景,因此传统的池化方法就显然不适用了。
为了达到想要的池化效果,CornerNet提出了Corner Pooling的方法,左上点的池化区域是其右侧与下方的特征点,右下点的池化区域是其左侧与上方的特征点,如下所示为左上点的Corner Pooling过程。

在图中,假设当前点的坐标为(x, y),特征图宽为W,高为H,则Corner Pooling的计算过程如下:
(1)计算该点到其下方所有点的最大值,即(x, y)到(x, H)所有点的最大值。
(2)计算该点到其最右侧所有点的最大值,即(x, y)到(W, y)所有点的最大值。
(3)将两个最大值相加,作为Corner Pooling的输出。
工程实现时,可以分别从下到上、从右到左计算最大值,这样效率会更高。右下点的CornerPooling过程与左上点类似。
3.预测输出
下面来看CornerNet的预测输出,以及损失的计算方式。左上角与右下角两个Corner Pooling层之后,分别接了3个预测量,这3个预测量的意义分别如下:
Heatmaps:角点热图,预测特征图中可能出现的角点,大小为C×W×H, C代表类别数,以左上角点的分支为例,坐标为(c, x, y)的预测点代表了在特征图上坐标为(x, y)的点是第c个类别物体的左上角点的分数。
Embeddings:Heatmaps中的预测角点都是独立的,而一个物体需要一对角点,因此Embeddings分支负责将左上角点的分支与右下角点的分支进行匹配,找到属于同一个物体的角点,完成检测任务,其大小为1×W×H。
Offsets:第三个预测Offsets代表在取整计算时丢失的精度,以进一步提升检测的精度。取整的丢失对于小物体检测影响很大,因此CornerNet引入了偏差的预测来修正检测框的位置,其大小为2×W×H。
CornerNet在损失计算时借鉴了Focal Loss的思想,对于不同的负样本给予了不同的权重,总体的损失公式为:

这4部分损失的含义说明如下:
Ldet:角点检测的损失,借鉴了Focal Loss权重惩罚的思想。CornerNet为了减小负样本的数量,将以标签角点为中心,半径为r区域内的点都视为正样本,因为这些点组成的边框与标签会有很大的IoU,仍有可能是我们想要的正样本。
Lpull:Embeddings中,对于属于同一物体的两个角点的惩罚。具体实现时,提取Embeddings中属于同一个物体的两个角点,然后求其均值,并希望两个角点的值与均值的差尽可能地小。
Lpush:Embeddings中,对不属于同一物体的两个角点的惩罚。具体实现时,利用Lpull中配对的角点的平均值,期望没有配对的角点与该平均值的差值尽可能地大,可以有效分离开无效的角点。
Loff:位置偏差的损失,与Faster RCNN相似的是,CornerNet使用了smoothL1损失函数来优化这部分位置偏差。
总体上,CornerNet巧妙地利用了一对关键点来实现物体检测,从而避免了Anchor带来的问题,在检测精度上相比其他单阶检测器有了一定提升。此外,CornerNet的工作也推动了一系列利用关键点做物体检测的算法的诞生。
本文方法:CentripetalNet
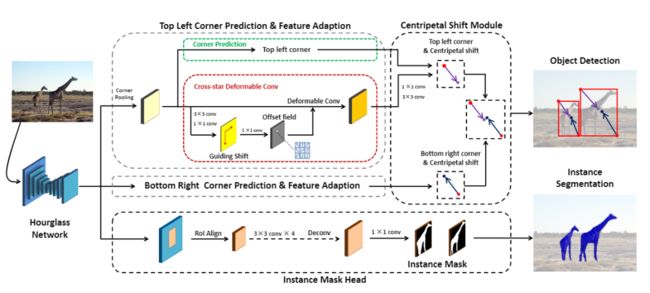
图2. CentripetalNet概述。由于左上角和右下角的角点预测和特征适应是相似的,为简单起见,仅绘制左上角模块。向心偏移模块首先通过CornerNet获取预测的角点和适应的特征,然后预测每个角点的向心偏移,并基于预测的角点和向心偏移执行角点匹配。匹配中,如果角点的位置足够接近,则它们会形成得分较高的边界框。
如图2所示,CentripetalNet模型整体由四个模块组成,即角点预测模块,向心偏移(centripetal shift)模块,十字星(cross-star)可形变卷积模块和实例分割mask模块。
首先根据CornerNet的流程生成角点候选。然后,针对所有候选角点,引入向心偏移算法,以追求高质量的角点对,并生成最终的预测边界框。具体地,向心偏移模块预测角点的向心偏移,并与其位置解码后的偏移结果对齐的角点进行匹配形成角点对。然后,提出了一种新颖的十字星形可形变卷积模块,其卷积的偏移量大小是从角点到相应中心的偏移中获得的,因此可以进行特征自适应选择并丰富角点位置的视觉特征,这对于提高向心偏移的准确性是很重要的。最后,在目标检测网络上添加了一个实例分割mask模块,以进一步提高检测性能,并扩展到实例分割领域。具体将向心偏移模块的预测边界框作为区域建议,使用RoIAlign提取区域特征并应用小型卷积网络来预测分割的mask。
一、 向心偏移模块 Centripetal Shift Module
向心偏移(Centripetal Shift)的概念:
假设边界框为:![]()
其几何中心为:![]()
则,分别定义其左上角和右下角的向心偏移为:
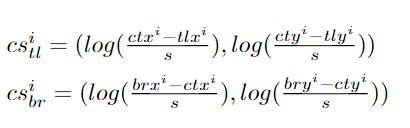
其中,使用对数函数来减小向心偏移的数值范围,并使学习过程更简单。
同时,训练时,在标签真值的角点位置应用平滑的L1损失。
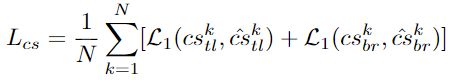
角点匹配(Corner Matching)
为了匹配角点,使用向心偏移及其位置来设计匹配方法。属于同一边界框的一对角点应该共享该框的中心是直观且合理的。由于可以从其位置和向心偏移中解码出相应的预测角中心,因此很容易比较一对角点的中心是否足够靠近并接近由角对组成的边界框的中心,如图3(c)所示。
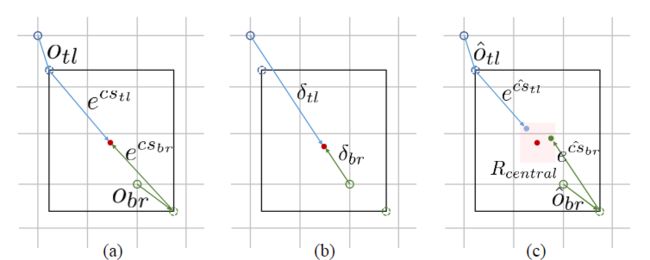
图3.(a)当将标签真值角点映射到热图时,使用局部偏移量Otl(或Obr)来补偿精度损失(b)guiding shift δ是热图上的标签真值角点到边界框中心的偏移(c)R central是本文用来匹配角点的中心区域。
基于上述观察,具体方法是:一旦角点是从corner heat map和局部偏移特征图中获得的,就将他们划分为同一类别分组并构造预测的边界框。对于每个bounding box,将其得分设置为其角点得分的几何平均值,这是通过在预测的corner heat map上应用softmax获得的。然后,如图3所示,将每个边界框的中心区域定义为下式,以比较解码后的中心与边界框中心的接近度。
![]()
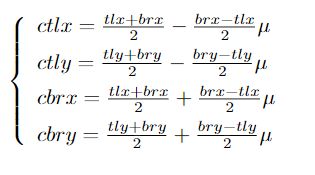
其中0 <μ≤1表示中心区域的宽度和高度是边界框的宽度和高度的μ倍。通过向心偏移,可以分别解码左上角和右下角的中心。
二、十字星形可形变卷积模块 Cross-star Deformable Convolution
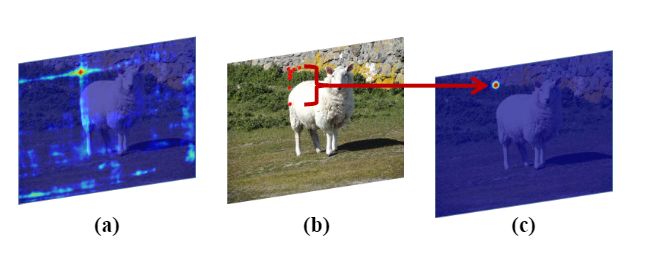
图4.(a)corner pool导致的“十字星”(b)十字星形可形变卷积在角点处的采样点。(c)角点预测模块的左上角热图。
由于corner pooling,特征图中有些“十字星Cross-star”,如图4(a)所示。“十字星”的边界保留了对象的大量上下文信息,因为corner pooling使用最大和运算将目标对象的位置信息沿“十字星”的边界扩展了到角点上。为了捕获“十字星”的上下文信息,不仅需要一个很大的感受野,而且还应该学习“十字星”的几何结构。于是,本文提出了十字星形可形变卷积,这是一种新颖的卷积运算,可增强角点处的视觉特征。
提出的十字星形可形变卷积如图2所示。首先,将corner pool的特征图输入到十字星形可形变卷积模块中。要学习“十字星”可形变卷积的几何结构,可以使用相应目标对象的大小来明确地指导偏移量,因为“十字星”的形状与边界框的形状有关。但是,因为物体外还有更多无用的信息,于是在模块中嵌入了一个guiding shift,即从角点到中心的偏移,如图3(b)所示,其中包含形状和方向信息,同时偏移了偏移量分支。
具体而言,在三个卷积层上执行偏移,前两个卷积层将corner pool输出嵌入到特征图中,并由以下损失监督:
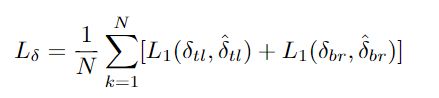
guiding shift由δ表示:
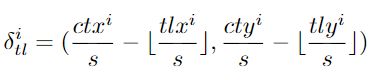
第二个卷积层将上述特征映射到偏移量中,改偏移量包含上下文和几何信息。通过可视化学习到的偏移量(如图7c所示),可以看出十字星形可形变卷积可以有效地学习“十字星形”的几何信息并提取“十字星形”边界的信息。

三、Instance Mask Head
为了获得实例分割mask,我们将soft-NMS之前的检测结果视为区域提议region proposals ,并使用全卷积神经网络来预测它们之上的mask。为了确保检测模块可以生成region,首先对CentripetalNet进行了一些预训练,然后选择top k得分的region,然后从骨干网络的特征图上执行RoIAlign以获取其特征。将RoIAlign的大小设置为14×14,并预测mask为28×28。
实验与结果
数据集: MS-COCO 2017 和 VOC
多任务学习:
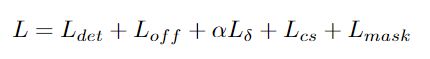
其中Ldet和Loff来自于CornerNet。将α设置为0.05,因为发现较大的α会降低网络的性能。与在CornerNet中一样,当使用Hourglass-104作为主干网络时,会添加中间监督损失。
实验配置:在16个32GB NVIDIA V100 GPU上训练模型,批处理大小为96(每个GPU 6张图像)
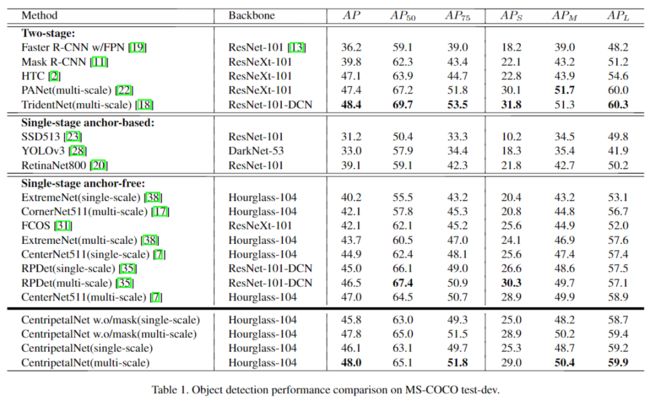
1、对比实验
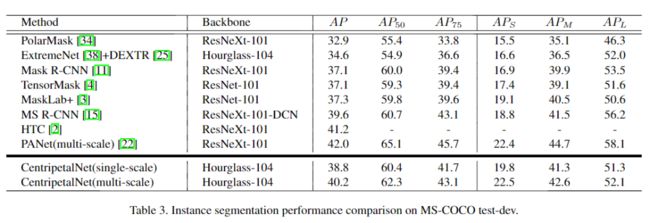
2、定性评估
如图6所示,CentripetalNet成功删除了CornerNet中错误的角点对。与CenterNet相比,CentropitalNet具有两个优点:首先,CentripetalNet不依赖于中心点检测,因此它可以保留正确的预测边界框,由于缺少中心检测,中心框被错误地删除了;其次,CenterNet无法处理目标对象中心位于目标中心的情况。这种情况通常发生在人群密集的情况下。
3、消融实验
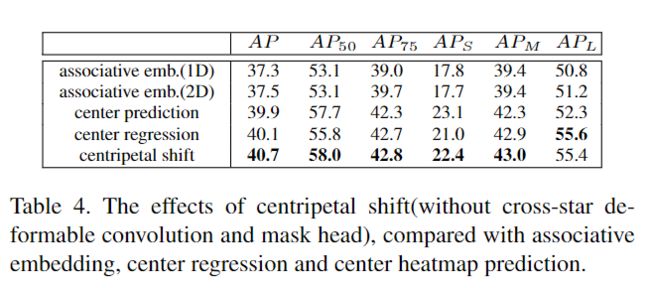
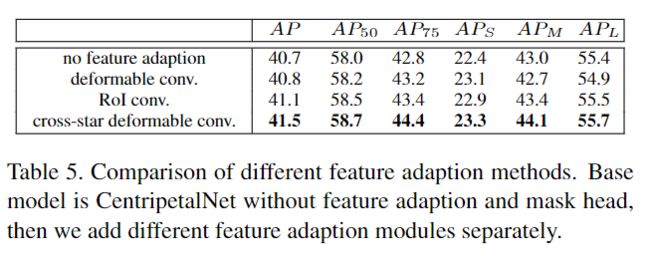
更多实验细节,可以参考原文。

