字符串匹配(string matching)算法之一 (Naive and Rabin_Karp)
编辑by Touzani
http://blog.csdn.net/touzani/archive/2007/05/29/1628885.aspx
字符串匹配(String matching)
|
算法
|
预处理时间
|
匹配时间
|
|
|
||
|
朴素算法
|
0
|
O
((n - m + 1)m)
|
|
Rabin-Karp
|
Θ(m)
|
O
((n - m + 1)m)
|
|
有限自动机算法
|
O
(m |Σ|)
|
Θ(n)
|
|
KMP
算法
|
Θ(m)
|
Θ(n)
|
如果某个字符串 y ∈ Σ*,使得x=wy 。则称w是x的前缀, 记为w � x 。 如果w是x的后缀,记为w � x
可以把字符串匹配问题描述为 找出0 ≤ s ≤ n-m 并满足P � Ts+m的所有位移s
4 do if P[1 ‥ m] = T[s + 1 ‥ s + m] // 隐含着一个循环
5 then print "Pattern occurs with shift" s
因此,字符串"31415" 对应于十进制数31415
已知模式P[1..m],设p表示其相应十进制数地值,类似地, 对于给定的文本T[1..n]. 用
可以用霍纳规则(Horner’s rule) 在Θ(m) 的时间内计算p的值
p = P[m] + 10 (P[m - 1] + 10(P[m - 2] + · · · + 10(P[2] + 10P[1]) )).
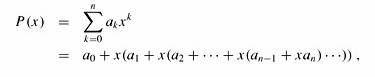
如果能在总共Θ(n - m + 1) 时间内计算出所有的ts 的值,那么通过把p值与每个ts(有n-m+1个)进行比较,就能够在Θ(m) + Θ(n - m + 1)= Θ(n) 时间内求出所有有效位移。(计算出1个ts 就跟p比较,处理结果。)
为了在Θ(n - m) 时间内计算出剩余的值t1, t2, . . . , tn-m 可以在常数的时间内根据ts计算出ts+1,先看例子,假如m = 5,ts = 31415, 我们去掉高位数字T [s + 1] = 3,然后在加入一个低位数字T [s + 5 + 1](假设为2),得到:
ts+1 = 10(31415 - 10000 • 3) + 2 = 14152.
总结出公式: 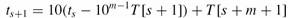 ——公式1
——公式1
因此,可以在Θ(m)时间内计算出p和t0。然后在Θ(n - m + 1)时间内计算出t1, . . . , tn-m并完成匹配。
现在来解决唯一的问题,就是计算中p和ts的值可能太大,超出计算机字长,不能方便地进行处理。如果p包含m个字符,那么, 关于在p上地每次算术运算需要“常数”时间这一假设就不合理了,幸运的是,对这一问题存在一个简单的补救方法,对一个合适的模q来计算p和ts的模,每个字符是一个十进制数,因为p和t0 以及公式1计算过程都可以对模q进行,所以可以在Θ(m)时间内计算出模q的p值,在Θ(n - m + 1)时间内计算出模q的所有ts值,通常选模q为一个素数,使得10q正好为一个计算机字长,单精度算术运算就可以执行所有必要的运算过程。 一般情况下,采用d进制的字母表{0, 1, . . . , d - 1}, 所选的q要满足d*q < 字长,调整公式1, 使其为: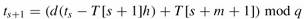
但是加入模q后,由ts ≡ p (mod q)不能说明 ts = p. 但ts � p (mod q), 可以说明 ts ≠ p,
 void
RABIN_KARP_MATCHER(
string
T,
string
P,
int
d,
int
q)
void
RABIN_KARP_MATCHER(
string
T,
string
P,
int
d,
int
q)  /*
/* 
 搜索P在T中出现的位置参数d :字母表的进制,亦即是字母表的元素个数参数q : 一个较大的素数, 只需d*q < 字长
搜索P在T中出现的位置参数d :字母表的进制,亦即是字母表的元素个数参数q : 一个较大的素数, 只需d*q < 字长 */
{ int n= T.length(); int m= P.length(); if( n < m) return ; int i, h=1; for(i=1; i<=m-1; i++) // caculate h h = h*d%q; int p=0, t=0; for(i=0; i<m; i++) // 预处理,计算p, t0
*/
{ int n= T.length(); int m= P.length(); if( n < m) return ; int i, h=1; for(i=1; i<=m-1; i++) // caculate h h = h*d%q; int p=0, t=0; for(i=0; i<m; i++) // 预处理,计算p, t0  {
{ p = (( d*p + P[i]) % q); t = (( d*t + T[i]) % q);
p = (( d*p + P[i]) % q); t = (( d*t + T[i]) % q); } int s; for(s=0; s < n-m+1; s++) // 匹配 { if( p == t ) { for(i=0; i<m; i++) // 进一步验证 if(P[i]!=T[s+i]) break; if(i==m) cout<<"Pattern ocurs with shift "<<s<<endl; } if( s < n-m ) t= ( d* (t - T[s]*h%q + q) + T[s+m]) % q; // 计算ts+1 } cout<<"string matching ends"<<endl; return ;}
} int s; for(s=0; s < n-m+1; s++) // 匹配 { if( p == t ) { for(i=0; i<m; i++) // 进一步验证 if(P[i]!=T[s+i]) break; if(i==m) cout<<"Pattern ocurs with shift "<<s<<endl; } if( s < n-m ) t= ( d* (t - T[s]*h%q + q) + T[s+m]) % q; // 计算ts+1 } cout<<"string matching ends"<<endl; return ;}
关于C++ % 运算符例子,见
用Rabin_Karp 算法解的题目:http://blog.csdn.net/touzani/archive/2007/05/15/1609265.aspx
RABIN_KARP_MATCHER预处理时间为Θ(m) 匹配时间最坏情况下为Θ((n - m + 1)m),
实际应用中,有效位移数很少(常数c个),因此期望的匹配时间为O((n - m + 1) + cm) = O(n+m), 选取的素数q比p的长度m大得多。
通常处理ASCII码字符, d=128, 素数q可选6999997。
下一篇:字符串匹配(string matching)算法之二:利用有限自动机http://blog.csdn.net/touzani/archive/2007/07/12/1687480.aspx