【卷积网络模型系列】轻量级卷积网络SqueezeNet的介绍与实现(Pytorch,Tensorflow)
一、背景介绍
在2012年AlexNet问世以为,卷积神经网络在图像分类识别,目标检测,图像分割等方面得到广泛应用,后续大牛们也提出了很多更优越的模型,比 如VGG, GoogLeNet系列,ResNet, DenseNet等。
伴随着精度的提升,对应模型的深度也随着增加,从AlexNet的7层,到16 层 VGG,再到GoogLeNet 的 22 层,再到 152 层 ResNet,更有上千层的 ResNet 和 DenseNet,从而带来了效率问题。因此,后面又提出来了在保持一定精度的前提下的轻量级卷积网路架构,SqueezeNet就是其中之一。
对于相同的正确率水平,轻量级的CNN架构可以提供如下的优势:
1. 在分布式训练中,与服务器通信需求更小
2. 参数更少,从云端下载模型的数据量小
3. 更适合在FPGA和嵌入式硬件设备上部署。
SqeezeNet在ImageNet上实现了和AlexNet相同的正确率,但是只使用了1/50的参数。更进一步,使用模型压缩技术,可以将SqueezeNet压缩到0.5MB,这是AlexNet的1/510。
二、SqueezeNet介绍
SqueezeNet所做的主要工作如下:
1. 提出了新的网络架构Fire Module,通过减少参数来进行模型压缩
2. 使用其它方法对提出的SqeezeNet模型进行进一步压缩
3. 对参数空间进行了探索,主要研究了压缩比和3×3卷积比例的影响
SqueezeNet中提出了 Fire Module结构作为网络的基础模块,具体结构如下图:

Fire module 由两层构成,分别是 squeeze 层+expand 层,如上图所示,squeeze 层是一个 1*1 卷积核的卷积层,expand 层是 1*1 和 3*3 卷积核的卷积层,expand 层中,把 1*1 和 3*3 得到的 feature map 进行 concat。
具体操作如下图所示:

s1 是 Squeeze层 1*1卷积核的数量, e1 是Expand层1*1卷积核的数量, e3是Expand层3*3卷积核的数量,在文中提出的 SqueezeNet 结构中,e1=e3=4s1。
SqueezeNet网络的整体结构如下图:

SqueezeNet以卷积层(conv1)开始,接着使用8个Fire modules (fire2-9),最后以卷积层(conv10)结束。每个fire module中的filter数量逐渐增加,并且在conv1, fire4, fire8, 和 conv10这几层之后使用步幅为2的最大池化。
模型具体参数情况如下图:

在Imagenet数据集上,和AlexNet对比如下图:
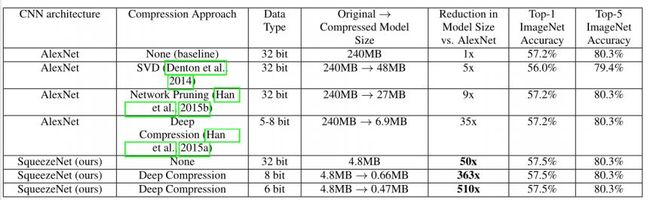
可以看到,在统一不使用模型压缩的情况下,模型大小相比于AlexNet,缩小了50倍,但是精度却和AlexNet一样。
三、SqueezeNet具体实现(Pytorch, Tensorflow)
1.Pytorch实现
import torch
import torch.nn as nn
from torchvision.models import squeezenet1_0
from torchvision import transforms
from PIL import Image
class Fire(nn.Module):
def __init__(self, in_channels, squeeze_channels, expand1x1_channels, expand3x3_channels):
super(Fire, self).__init__()
self.squeeze = nn.Conv2d(in_channels, squeeze_channels, kernel_size=1)
self.squeeze_activation = nn.ReLU(inplace=True)
self.expand1x1 = nn.Conv2d(squeeze_channels, expand1x1_channels, kernel_size=1)
self.expand1x1_activation = nn.ReLU(inplace=True)
self.expand3x3 = nn.Conv2d(squeeze_channels, expand3x3_channels, kernel_size=3, padding=1)
self.expand3x3_activation = nn.ReLU(inplace=True)
def forward(self, X):
X = self.squeeze_activation(self.squeeze(X))
X = torch.cat([
self.expand1x1_activation(self.expand1x1(X)),
self.expand3x3_activation(self.expand3x3(X))
], dim=1)
return X
class SqueezeNet(nn.Module):
def __init__(self):
super(SqueezeNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=7, stride=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(96, 16, 64, 64),
Fire(128, 16, 64, 64),
Fire(128, 32, 128, 128),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 32, 128, 128),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(512, 64, 256, 256)
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Conv2d(512, 1000, kernel_size=1), #输出 13*13*1000
nn.ReLU(inplace=True),
nn.AdaptiveAvgPool2d((1, 1)) #输出 1*1*1000
)
def forward(self, X):
X = self.features(X)
print(X.shape)
X = self.classifier(X)
return torch.flatten(X, 1)
#对图像的预处理(固定尺寸到224, 转换成touch数据, 归一化)
tran = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
if __name__ == '__main__':
image = Image.open("tiger.jpeg")
image = tran(image)
image = torch.unsqueeze(image, dim=0)
net = SqueezeNet()
# net = squeezenet1_0()
for name, parameter in net.named_parameters():
print("name={},size={}".format(name, parameter.size()))
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = net.to(device)
image = image.to(device)
net.load_state_dict(torch.load("squeezenet1_0-a815701f.pth")) # 加载pytorch中训练好的模型参数
net.eval()
output = net(image)
test, prop = torch.max(output, 1)
synset = [l.strip() for l in open("synset.txt").readlines()]
print("top1:", synset[prop.item()])
preb_index = torch.argsort(output, dim=1, descending=True)[0]
top5 = [(synset[preb_index[i]], output[0][preb_index[i]].item()) for i in range(5)]
print(("Top5: ", top5))

2.TensorFlow实现
import tensorflow as tf
import math
import numpy as np
from tensorflow.contrib.layers import conv2d, avg_pool2d, max_pool2d
class SqueezeNet():
def __init__(self, parameter_path=None):
if parameter_path:
self.parameter_dict = np.load(parameter_path, encoding="latin1").item()
else:
self.parameter_dict = {}
self.is_training = True
def set_training(self, is_training):
self.is_training = is_training
def bulid(self, image):
RGB_MEAN = [103.939, 116.779, 123.68]
with tf.variable_scope("preprocess"):
mean = tf.constant(value=RGB_MEAN, dtype=tf.float32, shape=[1, 1, 1, 3], name="preprocess_mean")
image = image - mean
self.conv1 = self._conv_layer(image, stride=2, filter_size=7, in_channels=3, out_channels=96, name="conv1") #112
self.conv1_relu = tf.nn.relu(self.conv1)
self.maxpool1 = self._max_pool(self.conv1_relu, filter_size=3, stride=2) #56
self.Fire2 = self._Fire(self.maxpool1, 96, 16, 64, 64, name="Fire2_")
self.Fire3 = self._Fire(self.Fire2, 128, 16, 64, 64, name="Fire3_")
self.Fire4 = self._Fire(self.Fire3, 128, 32, 128, 128, name="Fire4_")
self.maxpool2 = self._max_pool(self.Fire4, filter_size=3, stride=2, padding="VALID") #27
self.Fire5 = self._Fire(self.maxpool2, 256, 32, 128, 128, name="Fire5_")
self.Fire6 = self._Fire(self.Fire5, 256, 48, 192, 192, name="Fire6_")
self.Fire7 = self._Fire(self.Fire6, 384, 48, 192, 192, name="Fire7_")
self.Fire8 = self._Fire(self.Fire7, 384, 64, 256, 256, name="Fire8_")
self.maxpool3 = self._max_pool(self.Fire8, filter_size=3, stride=2, padding="VALID") #13
self.Fire9 = self._Fire(self.maxpool3, 512, 54, 256, 256, name="Fire9_")
# self.droup = tf.nn.dropout(self.Fire9, keep_prob=0.5)
self.conv10 = self._conv_layer(self.Fire9, stride=1, filter_size=1, in_channels=512, out_channels=10,
name="conv10")
print("self.conv10.get_shape()={}".format(self.conv10.get_shape()))
self.avgpool = self._avg_pool(self.conv10, filter_size=13, stride=1)
print("self.avgpool.get_shape()={}".format(self.avgpool.get_shape()))
return tf.squeeze(self.avgpool, [1, 2])
def _Fire(self, input, in_channels, squeeze_channels, expand1x1_channels, expand3x3_channels, name):
self.squeeze_conv = self._conv_layer(input, stride=1, filter_size=1,
in_channels=in_channels, out_channels=squeeze_channels,
name=name+"squeeze_conv")
self.squeeze_conv_relu = tf.nn.relu(self.squeeze_conv)
self.expand1x1_conv = self._conv_layer(self.squeeze_conv_relu, stride=1, filter_size=1,
in_channels=squeeze_channels, out_channels=expand1x1_channels,
name=name+"expand1x1_conv")
self.expand1x1_conv_relu = tf.nn.relu(self.expand1x1_conv)
self.expand3x3_conv = self._conv_layer(self.squeeze_conv_relu, stride=1, filter_size=3,
in_channels=squeeze_channels, out_channels=expand3x3_channels,
name=name + "expand3x3_conv")
self.expand3x3_conv_relu = tf.nn.relu(self.expand3x3_conv)
return tf.concat([self.expand1x1_conv_relu, self.expand3x3_conv_relu], axis=3)
def _batch_norm(self, input):
return tf.layers.batch_normalization(inputs=input, axis=3, momentum=0.99,
epsilon=1e-12, center=True, scale=True,
training=self.is_training)
def _avg_pool(self, input, filter_size, stride, padding="VALID"):
return tf.nn.avg_pool(input, ksize=[1, filter_size, filter_size, 1],
strides=[1, stride, stride, 1], padding=padding)
def _max_pool(self, input, filter_size, stride, padding="SAME"):
return tf.nn.max_pool(input, ksize=[1, filter_size, filter_size, 1],
strides=[1, stride, stride, 1], padding=padding)
def _conv_layer(self, input, stride, filter_size, in_channels, out_channels, name, padding="SAME"):
'''
定义卷积层
'''
with tf.variable_scope(name):
conv_filter, bias = self._get_conv_parameter(filter_size, in_channels, out_channels, name)
conv = tf.nn.conv2d(input, filter=conv_filter, strides=[1, stride, stride, 1], padding=padding)
conv_bias = tf.nn.bias_add(conv, bias)
return conv_bias
def _fc_layer(self, input, in_size, out_size, name):
'''
定义全连接层
'''
with tf.variable_scope(name):
input = tf.reshape(input, [-1, in_size])
fc_weights, fc_bais = self._get_fc_parameter(in_size, out_size, name)
fc = tf.nn.bias_add(tf.matmul(input, fc_weights), fc_bais)
return fc
def _get_conv_parameter(self, filter_size, in_channels, out_channels, name):
'''
用于获取卷积层参数
:param filter_size: 卷积核大小
:param in_channel: 卷积核channel
:param out_channel: 卷积输出的channel,也就是卷积核个数
:param name: 当前卷积层name
:return: 返回对应卷积核 和 偏置
'''
if name in self.parameter_dict:
conv_filter_initValue = self.parameter_dict[name][0];
bias_initValue = self.parameter_dict[name][1]
conv_filter_value = tf.Variable(initial_value=conv_filter_initValue, name=name + "_weights")
bias = tf.Variable(initial_value=bias_initValue, name=name + "_biases")
else:
conv_filter_value = tf.get_variable(name=name+"_weights",
shape=[filter_size, filter_size, in_channels, out_channels],
initializer=tf.contrib.keras.initializers.he_normal())
bias = tf.get_variable(name=name+"_biases", shape=[out_channels],
initializer=tf.constant_initializer(0.1, dtype=tf.float32))
return conv_filter_value, bias
def _get_fc_parameter(self, in_size, out_size, name):
'''
用于获取全连接层参数
:param in_size:
:param out_size:
:param name:
:return:
'''
if name in self.parameter_dict:
fc_weights_initValue = self.parameter_dict[name][0]
fc_bias_initValue = self.parameter_dict[name][1]
fc_weights = tf.Variable(initial_value=fc_weights_initValue, name=name + "_weights")
fc_bias = tf.Variable(initial_value=fc_bias_initValue, name=name + "_biases")
else:
fc_weights = tf.get_variable(name=name + "_weights",
shape=[in_size, out_size],
initializer=tf.contrib.keras.initializers.he_normal())
fc_bias = tf.get_variable(name=name + "_biases", shape=[out_size],
initializer=tf.constant_initializer(0.1, dtype=tf.float32))
return fc_weights, fc_bias
if __name__ == '__main__':
input = tf.placeholder(dtype=tf.float32, shape=[1, 224, 224, 3], name="input")
resnet = SqueezeNet()
out_put = resnet.bulid(input)
print(out_put.get_shape())相关完整代码以及pytorch训练好的模型参数百度网盘下载,请关注我的公众号 AI计算机视觉工坊,回复【代码】获取。本公众号不定期推送机器学习,深度学习,计算机视觉等相关文章,欢迎大家和我一起学习,交流
