MapReduce之 WordCount 源码分析和操作流程
在之前的工作中,主要做了三件事情:
1 如何完成Hadoop的完全分布式集群搭建
2 如何运行Hadoop自带示例WordCount,验证集群的运行
3 如何基于eclipse插件实现Hadoop编程
完成每一件事都需要经过谨慎的操作、反复的验证,还有耐心。安装完之后一下成功是很难的,仍需要检验每一步的操作、查看错误问题的日志、分析网上类似问题的各类解决方法,于是在千转百回之下,柳暗花明。我分享了以上操作的详细步骤和注意事项,如果你尚未搭建Hadoop,可以看一看,或许有帮助。
自此就正式开始进入Hadoop的学习之旅了。今天介绍Hadoop编程模型mapreduce中最基础的示例Wordcount。主要介绍两部分:
- WordCount 源码分析
- WordCount 操作流程
1 WordCount 源码分析
WordCount 的源码一般是在下载的Hadoop安装包下的hadoop-1.2.1/src/examples/org/apache/hadoop/examples 里面有WordCount.java文件,你可以使用UltraEdit或者记事本打开。内容如下:
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "172.16.10.15:9001");//自己额外加的代码
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount " );
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
这里包含了三个部分:编写map类实现Mapper操作,编写reduce类实现Reduce操作,编写主函数实现参数设置和执行。
1.1 编写map类实现Mapper操作
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}a) 定义一个自己的Map过程,TokenizerMapper 这个类名自己设定,这个类需要继承org.apache.hadoop.mapreduce包中的Mapper类,四个参数分别表示输入键key的参数类型,输入值value的参数类型,输出键key的参数类型,输出值value的参数类型。
b) map方法中参数value是指文本文件中的一行,参数key是为该行首字母相对于文本文件首地址的偏移量。
c) StringTokenizer类是一个用来分隔String的应用类,类似于split。
//它的构造函数有三种:
public StringTokenizer(String str)
public StringTokenizer(String str,String delim)
public StringTokenizer(String str,String delim,boolean returnDelims)
//其中第一个参数为要分隔的String,第二个参数为分隔字符集合,第三个参数为分隔符是否作为标记返回,如果不指定分隔符,默认是'\t\n\r\f'
//它的方法主要有三种:
public boolean hasMoreTokens()//返回是否还有分隔符
public String nextToken()//返回从当前位置到下一个分隔符的字符串
public int countTokens()//返回nextToken方法被调用的次数d) 经过StringTolenizer 处理之后会得到一个个 < word,1 > 这样的键值对,放在context里。
1.2 编写reduce类实现Reduce操作
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} a) 同mapper 过程一样,Reduce过程需要继承org.apache.hadoop.mapreduce包中Reducer类,并重写其reduce方法。
b) reduce方法中输入参数key 指单个单词,value 指对应单词的计数值的列表
c) reduce 方法的目的就是对列表的值进行加和处理
d) 输出的是< key,value>,key 指单个单词,value 指对应单词的计数值的列表的值的总和。
1.3 编写主函数实现参数设置和执行
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "172.16.10.15:9001");//自己额外加的代码
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount " );
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}a) Configuration conf = new Configuration(); 默认情况下,Configuration开始实例化的时候,会从Hadoop的配置文件里读取参数。
b) conf.set(“mapred.job.tracker”, “172.16.10.15:9001”);设置这句代码是由于我们要把使用eclipse提交作业到Hadoop集群,所以手动添加Job运行地址。若是直接在Hadoop 集群进行运行,不用加这句代码。
c) 接下来这一句也是读取参数,这里是从命令行参数里读取参数。
d) Job job = new Job(conf, “word count”); 在MapReduce处理过程中,由Job对象负责管理和运行一个计算任务,然后通过Job的若干方法来对任务的参数进行设置。”word count”是Job的名字。
e) job.setJarByClass(WordCount.class);是根据WordCount类的位置设置Jar文件
f) job.setMapperClass(TokenizerMapper.class);设置Mapper
g) job.setCombinerClass(IntSumReducer.class);设置Combiner,这里先使用Reduce类来进行Mapper 的中间结果的合并,能够减轻网络传输的压力。
h) job.setReducerClass(IntSumReducer.class);设置Reduce
i) job.setOutputKeyClass(Text.class);和 job.setOutputValueClass(IntWritable.class);分别是设置输出键的类型和设置输出值的类型
j) FileInputFormat.addInputPath(job, new Path(otherArgs[0]));设置输入文件,它是otherArgs第一个参数
k) FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));设置输出文件,将输出结果写入这个文件里,它是otherArgs第二个参数
l) System.exit(job.waitForCompletion(true) ? 0 : 1);job执行,等待执行结果
1.4 引用的若干个类
本文为MapReduce系列第一篇分析,所以加上了对文件开头的包和类的介绍,之后的例子里相差不大的话,就不再专门介绍了。
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
这里分别是开发过程中的Java API 文档和Hadoop API 文档,在接下来的介绍中会提及,有兴趣可以查看。
a) package org.apache.hadoop.examples;Java 提供包机制管理代码,关键词是package, 包名字可以自己定,但不能重复。通常为了包的唯一性,推荐使用公司域名的逆序作为包,于是有了上面例子中的‘org.apache.hadoop’这样的包名。
b) import java.io.IOException; 凡是以java开头的包,在JDK1.7的API里可以找到类的资料。这里是从java.io中引入IOException,是一个输入输出异常类。
c) import java.util.StringTokenizer;这是从java.util包中引入的StringTokenizer类,是一个解析文本的类。具体用法上文中已提过了。
d) import org.apache.hadoop.conf.Configuration;凡是以org.apache.hadoop开头的包,在Hadoop1.2.1 的API文档可以找到类的资料。这里是从hadoop的conf包中引入Configuration类,它是一个读写和保存配置信息的类。
e) import org.apache.hadoop.fs.Path;Path类保存文件或者目录的路径字符串
f) import org.apache.hadoop.io.IntWritable;IntWritable是一个以类表示的可序化的整数。在java中,要表示一个整数,可以使用int类型,也可以使用integer类型,integer封装了int类型,且integer类是可序化的。但Hadoop认为integer的可序化不合适,于是实现了IntWritable。
g) import org.apache.hadoop.io.Text;从io包中引入Text类,是一个存储字符串的可比较可序化的类。
h) import org.apache.hadoop.mapreduce.Job;引入Job类,Hadoop中每个需要执行的任务是一个Job,这个Job负责参数配置、设置MapReduce细节、提交到Hadoop集群、执行控制等操作。
i) import org.apache.hadoop.mapreduce.Mapper;引入Mapper类,负责MapReduce中的Map过程。
j) import org.apache.hadoop.mapreduce.Reducer;引入Reduce类,负责MapReduce中的Reduce过程。
k) import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;引入FileInputFormat类,主要功能是将文件进行切片。
l) import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;FileOutputFormat类是将输出结果写入文件。
m) import org.apache.hadoop.util.GenericOptionsParser;这个类负责解析命令行参数。
2 WordCount 操作流程
经过第一部分的介绍,能够了解到WordCount在MapReduce计算框架下的实现原理,下面通过一个具体的例子和图示来展示一下WordCount的操作流程。
1) 将文件file1.txt,file2.txt 上传到hdfs中的hdfsinput1文件夹里(上传的方式可以通过eclipse客户端,也可以通过Hadoop命令行),然后在eclipse上编写wordcount.java文件(也即是第一部分分析的源码)
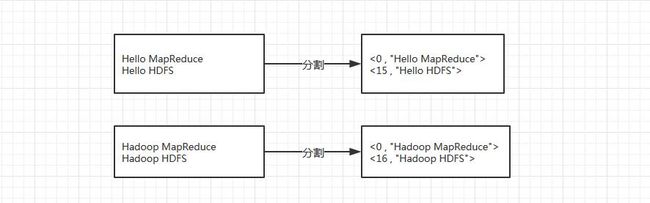
2) 由于测试用的文件较小,所以每个文件为一个split,并将文件按行分割形成< key,value>,这一步由MapReduce框架自动完成,其中key值为该行首字母相对于文本文件首地址的偏移量。
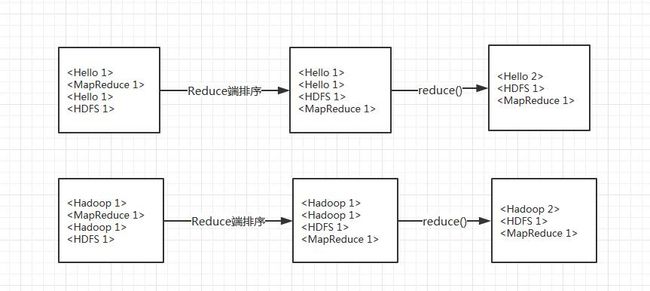
3) 将分割好的< key,value>对交给自己定义的map方法,输出新的< key,value>对。

4) 得到map方法输出的< key,value>对后,进行Combine操作。这里Combine 执行的是Reduce的代码。
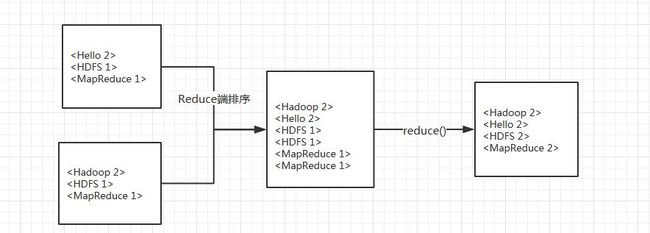
5)同样,在Reduce过程中先对输入的数据进行排序,再交由自定义的reduce方法进行处理,得到新的< key,value>对,并作为WordCount的输出结果,输出结果存放在第一张图的lxnoutputssss文件夹下的part-r-00000里。
参考文献:
1.Hadoop集群(第6期)_WordCount运行详解 http://www.cnblogs.com/xia520pi/archive/2012/05/16/2504205.html
2.从零开始学习Hadoop–第2章 第一个MapReduce程序 https://www.douban.com/note/313096086/
3.谷歌技术”三宝”之MapReduce http://blog.csdn.net/opennaive/article/details/7514146