Real-time correlative scan matching 论文算法分析
-
-
- 背景
- 算法
- 基础模型
- 算法简化
- 核心
- 后记
-
背景
读这篇论文的初衷在于希望能够读懂 Google’s Cartographer(开源激光SLAM算法),这篇文章是 Cartographer 的论文 《Real-Time Loop Closure in 2D LIDAR SLAM》的引用文献之一,也是代码实现里 real time correlative scan matcher 和 fast correlative scan matcher 的算法来源(两者分别用在了前段和后端的算法中),总之是读懂 Cartographer 的关键论文之一,故这里写下我读这篇论文的一些理解。
算法
有一些基础的概念这里是默认读者是能理解的
1. Scan Matching —— 求解两帧雷达数据(scan to scan)或者雷达数据与地图(scan to map)之间的旋转矩阵(位移和旋转)的过程;
2. Maximum likelihood estiamtion (极大似然估计) —— 利用已知样本结果,在使用某个模型的基础上,反推最有可能导致这样的结果的参数。这是一个相对生涩的解释,有兴趣的读者可以自行搜索相关的博客或文章来看,完整的看下来会比较容易理解。
基础模型
我们这里用极大似然估计的思路来给 Scan Matching 建模,这里我们采用的是 Cartographer 中的 Scan-to-Map 的模式:
其中, xt x t , xt−1 x t − 1 就是当前时刻和上一时刻的位姿,前者为未知的带求解的量, zt z t 为当前scan里的所有数据的集合,相当于是当前一帧雷达数据中的所有点,包括角度和距离; mt−1 m t − 1 现有的地图信息; ut−1 u t − 1 是上一时刻到这一时刻的运动量(或者运动相关的观测量,如里程计数据、IMU数据等)。
那么,这个式子的比较通俗的解释(可能跟式子中的含义并非完全相同)即:
在上一时刻 t−1 t − 1 ,我们已经获得了地图 m m , 还有位姿信息和一些运动相关的信息,我们想要通过这个运动信息和上一时刻的位姿信息来估计当前时刻的位姿,当然由于观测量或者模型的一些不准确性,我们得到的是一个分布的信息,也就是当前的位姿会落在一定的范围内;接着我们就需要求解在这个范围内的所有位姿哪个最符合观测模型,也就是(CS) 式中的第一个概率 —— 在已知地图下,若获得某一雷达观测量 zt z t , 机器人最有可能的位姿(这个就是极大似然估计的思路),不过我们这里换一个思路:我们已经从运动模型获得了一个位姿估计的范围,我们只需要在这个范围里面遍历所有的位姿,每个位姿在已有地图里面获得会获得的观测信息(scan)与实际scan最接近的那个,那这个位姿就是我们要找到的 xt x t
算法简化
首先,并不是所有的机器人都可以获取运动信息(odom、 imu),也就是模型里面的 ut−1 u t − 1 并不是在所有应用场景都存在,或者说这个数据的可信度有时候很低,我们并不一定使用这个观测量,在这样的情况下我们省略掉 (CS)式中第二个概率计算式(通常称作运动模型),而专注于第一个概率计算式(通常称作观测模型)。
接着,针对这个观测模型:
我们仍然要做出一些简化。我们想象一个场景,在一个房间里有若干个箱子(激光无法穿透),有一个搭载了2d单线雷达的机器人在这个房间内,那么它的观测模型将会面临两个问题:1. visibility —— 并不是所有的地图里的东西对于机器人当前位置都是可见的; 2. occlusion —— 机器人在不同位置看到的同一个箱子是完全不同的形状。
在不同的复杂环境中,如果我们在建立观测模型时同时考虑以上这两个问题会非常的复杂,难以建模,所以在这一层的简化里,我们假设 机器人在任何位置上都能看到地图上的所有点,即在 xt x t 点上的机器人可以看到 mt−1 m t − 1 上的所有点,这样建模要相对简单的多(后面我们也会说明这样的简化并不是使定位或者简图的效果变差)。
核心
好了,经过上面的简化,我们的算法已经相对要简单多了,下面就是这个算法的核心:
首先,在我们的直观感受里, zt z t (雷达观测数据)里包含了很多点数据(二维平面上的极坐标),而这些数据相互之间并没有关联,所以我们这里假设他们是完全独立的:
上面的式子将整个一帧观测数据的概率拆分成了当前帧的数据的每一个点的概率,在计算这个概率之前,我们需要对数据帧以及地图做一些处理——栅格化。
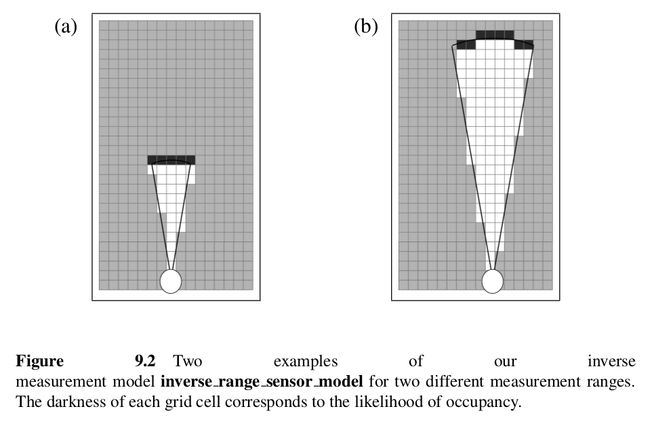
对 ROS 比较熟悉的读者会知道 ROS 里面有一种常用的 2d 地图表达形式,就是占据栅格图(occupancy grid map),就是利用了栅格化的思路,原理很简单,如下图是一帧scan数据的一小部分,我们将整个观测平面切分成固定宽度的方格,我们可以类比图片,每个方格都是一个像素,每个位置有障碍物的概率对应该像素的灰度值。概率越高值越则该像素越黑,说明该位置很有可能有障碍物;相反概率越低越白,也就意味着该位置很可能是空的;未知区域的灰度为128。
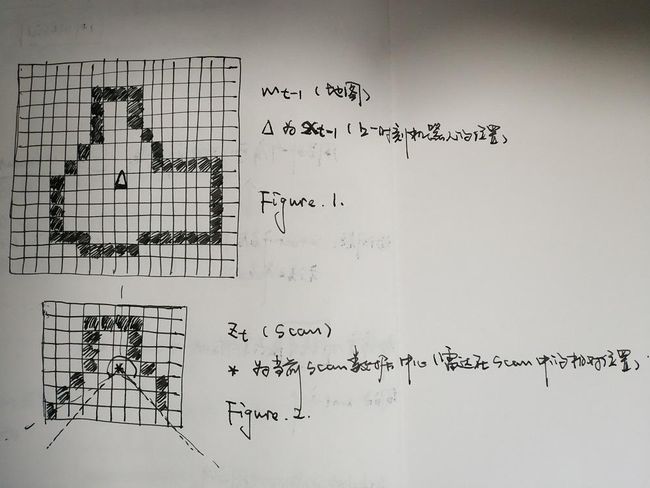
到了最后一步,scan to map 的 scan matching 问题。如下图(我不知道用什么工具可以快速画出上面图中的效果,所以只好手绘拍下来,有更好办法的读者希望可以留言告知),我们假设已经有的地图为 Figure.1 F i g u r e .1 ,图中小三角形是上一时刻的机器人的位姿。当前时刻我们获取到的雷达数据(scan)见 Figure.2 F i g u r e .2 ,我们很容易就能判断出当前的机器人位置(较上一时刻前进了3个像素),不过我们需要用算法实现这个判断。
- 现在设 zt z t 为 (1,1),(2,0),(1,2).. ( 1 , 1 ) , ( 2 , 0 ) , ( 1 , 2 ) . . 这样的一个坐标集合
- 在 xt−1 x t − 1 的周围设定一个 search window,比如一个以 xt−1 x t − 1 为中心的10×10 的矩形区域(单位为像素),这个search window也包括旋转的范围,如(-10°, 10°)
- 在这个区域里面生成一个搜索候选的子集,这个搜索的子集包括位移和旋转,如 xt−1+(2,0) x t − 1 + ( 2 , 0 ) 位置上旋转1°,2°,3°等
- 遍历这个候选的子集,计算每个候选位置和旋转上对应 zt z t 集合中所有坐标上概率和,找到那个概率和最高的就是我们要找的当前机器人的位姿。
Cartographer 中的实现思路大概如上,详细可以看Cartographer代码中的 real_time_correlative_scan_matcher 的实现。不过论文中提供了几个思路的比较,如BF, 2D Slices 等,不过重点在于一个分辨率切换的思路—— multi-resolution:
- 首先选择一个相对低的分辨率对 map 和 scan 进行栅格化,每个栅格上保留高分辨率情况下的该区域的最高概率,这样在匹配时就不会错过正确的位姿估计
- 低分辨率找到最佳匹配后再在该位置进行高分辨率的栅格化,并设定相对较小的 search window( translation & rotation)进行计算。
这个思路在保证不错过最佳匹配的同时明显减少了计算量,使得scan matching可以达到real time的效果。
后记
Cartographer中有两个scan matcher都涉及到了这个论文里的类似算法,包括前面提高的real time correlative scan matcher, 而真正实现了上面的multi-resolution的思路的是fast correlative scan matcher,有兴趣的读者可以去阅读一下源码,代码量不大,也不难懂。