08.模型集成
机器学习实战教程(十):提升分类器性能利器-AdaBoost
模型融合方法总结
机器学习模型优化之模型融合
xgboost
lightgbm
文章目录
- 集成方法
- 1、Bagging
- 2、Boosting
- 3、Bagging、Boosting二者之间的区别
- 4、AdaBoost
- 1) 计算样本权重
- 2) 计算错误率
- 3) 计算弱学习算法权重
- 4) 更新样本权重
- 5) AdaBoost算法
- 5.实例
- Bagging
- Adaboost
集成方法
将不同的分类器组合起来,而这种组合结果则被成为集成方法(ensemble method)或者元算法(meta-algorithm)。
集成方法主要包括Bagging和Boosting两种方法,Bagging和Boosting都是将已有的分类或回归算法通过一定方式组合起来,形成一个性能更加强大的分类器,更准确的说这是一种分类算法的组装方法,即将弱分类器组装成强分类器的方法。
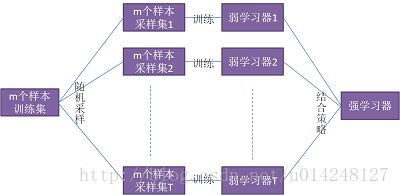
1、Bagging
自举汇聚法(bootstrap aggregating),也称为bagging方法。Bagging对训练数据采用自举采样(boostrap sampling),即有放回地采样数据,主要思想:
- 从原始样本集中抽取训练集(
每次都是从训练集中做有放回的随机采样)。每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的) - 每次使用一个训练集得到一个模型,k个训练集共得到k个模型。(注:这里并没有具体的分类算法或回归方法,我们可以根据具体问题采用不同的分类或回归方法,如决策树、感知器等)
- 对分类问题:将上步得到的k个模型采用
投票的方式得到分类结果;对回归问题,计算上述模型的均值(或加权平均)作为最后的结果。(所有模型的重要性相同)
2、Boosting
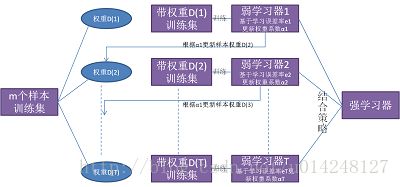
Boosting是一种与Bagging很类似的技术。Boosting的思路则是采用重赋权(re-weighting)法迭代地训练基分类器,主要思想:
- 每一轮的训练数据样本赋予一个权重,并且每一轮样本的权值分布依赖上一轮的分类结果(
每一轮训练的样本集不变,只是赋予了不同的权重)。 - 基分类器之间采用序列式的
线性加权方式进行组合。
3、Bagging、Boosting二者之间的区别
样本选择上:
- Bagging:训练集是在原始集中有
放回采样,从原始集中选出的各轮训练集之间是独立的。 - Boosting:每一轮的
训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
样例权重:
- Bagging:使用均匀取样,每个样例的权重相等。
- Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
预测函数:
- Bagging:所有预测函数的权重相等。
- Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
并行计算:
- Bagging:各个预测函数可以并行生成。
- Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
下面是将决策树与这些算法框架进行结合所得到的新的算法:
- Bagging + 决策树 = 随机森林
- AdaBoost + 决策树 = 提升树
- Gradient Boosting + 决策树 = GBDT
4、AdaBoost
AdaBoost算法是基于Boosting思想的机器学习算法,AdaBoost是adaptive boosting(自适应boosting)的缩写,其运行过程如下:
1) 计算样本权重
训练数据中的每个样本,赋予其权重,即样本权重,用向量D表示,这些权重都初始化成相等值。假设有n个样本的训练集:

设定每个样本的权重都是相等的,即1/n。
2) 计算错误率
利用第一个弱学习算法h1对其进行学习,学习完成后进行错误率ε的统计:

3) 计算弱学习算法权重
弱学习算法也有一个权重,用向量α表示,利用错误率计算权重α:
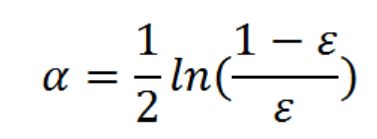
4) 更新样本权重
在第一次学习完成后,需要重新调整样本的权重,以使得在第一分类中被错分的样本的权重,在接下来的学习中可以重点对其进行学习:
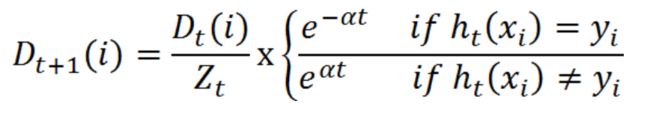
其中, h t ( x i ) = y i h_t(x_i) = y_i ht(xi)=yi表示对第 i i i个样本训练正确,不等于则表示分类错误。 Z t Z_t Zt是一个归一化因子:
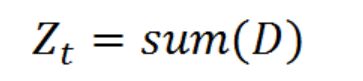
这个公式我们可以继续化简,将两个公式进行合并,化简如下:
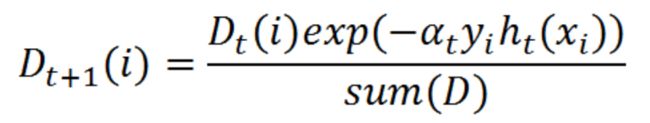
5) AdaBoost算法
重复进行学习,这样经过t轮的学习后,就会得到t个弱学习算法、权重、弱分类器的输出以及最终的AdaBoost算法的输出,分别如下:
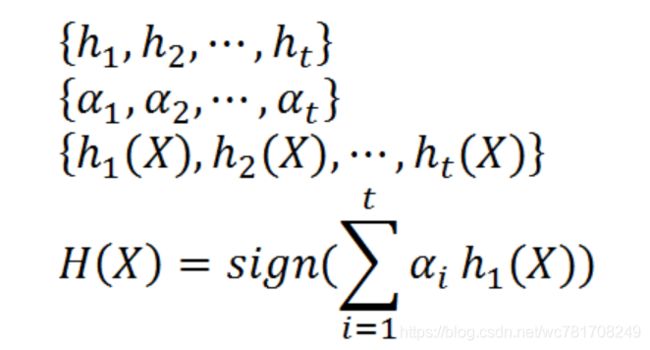

5.实例
Bagging
"""
Author:wucng
Time: 20200115
Summary: 模型融合-Bagging
源代码: https://github.com/wucng/MLAndDL
参考:https://cuijiahua.com/blog/2017/11/ml_10_adaboost.html
"""
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.ensemble import BaggingClassifier,VotingClassifier
from sklearn.linear_model import LinearRegression,LogisticRegression
from sklearn.tree import DecisionTreeClassifier,DecisionTreeRegressor
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import numpy as np
import scipy,pickle,os,time
import pandas as pd
# 1.加载数据集(并做预处理)
def loadData(dataPath: str) -> tuple:
# 如果有标题可以省略header,names ;sep 为数据分割符
df = pd.read_csv(dataPath, sep=",")
# 填充缺失值
df["Age"] = df["Age"].fillna(df["Age"].median())
df['Embarked'] = df['Embarked'].fillna('S')
# df = df.fillna(0)
# 数据量化
# 文本量化
df.replace("male", 0, inplace=True)
df.replace("female", 1, inplace=True)
df.loc[df["Embarked"] == "S", "Embarked"] = 0
df.loc[df["Embarked"] == "C", "Embarked"] = 1
df.loc[df["Embarked"] == "Q", "Embarked"] = 2
# 划分出特征数据与标签数据
X = df.drop(["PassengerId","Survived","Name","Ticket","Cabin"], axis=1) # 特征数据
y = df.Survived # or df["Survived"] # 标签数据
# 数据归一化
X = (X - np.min(X, axis=0)) / (np.max(X, axis=0) - np.min(X, axis=0))
# 使用sklearn方式
# X = MinMaxScaler().transform(X)
# 查看df信息
# df.info()
# df.describe()
return (X.to_numpy(), y.to_numpy())
class BaggingClassifierSelf(object):
def __init__(self,modelList=[]):
self.modelList = modelList
def fit(self,X:np.array,y:np.array):
index = np.arange(0,len(y),dtype = np.int32)
for model in self.modelList:
# 有放回的随机采样
new_index = np.random.choice(index, size=len(y))
new_X =X[new_index]
new_y = y[new_index]
model.fit(new_X,new_y)
def predict(self,X:np.array):
preds =[]
for model in self.modelList:
preds.append(model.predict(X))
# 按少数服从多数(投票机制)
new_preds = np.array(preds).T
# 统计每列次数出现最多对应的值即为预测标签
y_pred = [np.bincount(pred).argmax() for pred in new_preds]
return preds,y_pred
def predict_proba(self,X:np.array):
preds_proba=[]
for model in self.modelList:
preds_proba.append(model.predict_proba(X))
# 直接计算分成没类分数取平均
y_preds_proba = np.zeros_like(preds_proba[0])
for proba in preds_proba:
y_preds_proba += proba
# 取平均
y_preds_proba = y_preds_proba/len(preds_proba)
return preds_proba,y_preds_proba
if __name__=="__main__":
dataPath = "../../dataset/titannic/train.csv"
X, y = loadData(dataPath)
# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=40)
# 创建5个决策树模型,也可以使用其他模型混合(模型不一定要一样)
modelList =[]
modelList.append(DecisionTreeClassifier(random_state=9))
modelList.append(DecisionTreeClassifier(splitter="random",random_state=0))
modelList.append(DecisionTreeClassifier("entropy",random_state=9))
modelList.append(DecisionTreeClassifier("entropy","random",random_state=0))
modelList.append(DecisionTreeClassifier("entropy","random",random_state=12))
modelList.append(LogisticRegression(penalty='l2',max_iter=1000,C=1.5))
modelList.append(LogisticRegression(penalty='l1',max_iter=1000,C=1.5))
modelList.append(LogisticRegression(penalty='l2',max_iter=2000,C=1.5))
modelList.append(LogisticRegression(penalty='l1', max_iter=5000, C=1.5))
modelList.append(LogisticRegression(penalty='l2', max_iter=5000, C=1.5))
clf_bagging = BaggingClassifierSelf(modelList)
clf_bagging.fit(X_train,y_train)
preds,y_pred = clf_bagging.predict(X_test)
# 计算acc
# 每个单独的分类器的acc
for i in range(len(modelList)):
print("model:%d acc:%.5f" % (i, accuracy_score(preds[i], y_test)))
# bagging的acc
print("bagging acc:%.5f" % (accuracy_score(y_pred, y_test)))
print("-----------------------------------------------------")
preds_proba, y_preds_proba = clf_bagging.predict_proba(X_test)
preds, y_pred = [proba.argmax(axis=-1) for proba in preds_proba], y_preds_proba.argmax(axis=-1)
# 计算acc
# 每个单独的分类器的acc
for i in range(len(modelList)):
print("model:%d acc:%.5f"%(i,accuracy_score(preds[i],y_test)))
# bagging的acc
print("bagging acc:%.5f" % (accuracy_score(y_pred, y_test)))
# sklearn 的 BaggingClassifier
clf = BaggingClassifier(DecisionTreeClassifier())
clf.fit(X_train,y_train)
y_pred = clf.predict(X_test)
print("bagging acc:%.5f" % (accuracy_score(y_pred, y_test)))
# sklearn 的 VotingClassifier
clf = VotingClassifier(estimators=[(str(i),model) for i,model in enumerate(modelList)])
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("bagging acc:%.5f" % (accuracy_score(y_pred, y_test)))
Adaboost
"""
Author:wucng
Time: 20200115
Summary: 模型融合-Adaboost
源代码: https://github.com/wucng/MLAndDL
参考:https://cuijiahua.com/blog/2017/11/ml_10_adaboost.html
"""
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.ensemble import BaggingClassifier,VotingClassifier,AdaBoostClassifier
from sklearn.linear_model import LinearRegression,LogisticRegression
from sklearn.tree import DecisionTreeClassifier,DecisionTreeRegressor
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import numpy as np
import scipy,pickle,os,time
import pandas as pd
# 1.加载数据集(并做预处理)
def loadData(dataPath: str) -> tuple:
# 如果有标题可以省略header,names ;sep 为数据分割符
df = pd.read_csv(dataPath, sep=",")
# 填充缺失值
df["Age"] = df["Age"].fillna(df["Age"].median())
df['Embarked'] = df['Embarked'].fillna('S')
# df = df.fillna(0)
# 数据量化
# 文本量化
df.replace("male", 0, inplace=True)
df.replace("female", 1, inplace=True)
df.loc[df["Embarked"] == "S", "Embarked"] = 0
df.loc[df["Embarked"] == "C", "Embarked"] = 1
df.loc[df["Embarked"] == "Q", "Embarked"] = 2
# 划分出特征数据与标签数据
X = df.drop(["PassengerId","Survived","Name","Ticket","Cabin"], axis=1) # 特征数据
y = df.Survived # or df["Survived"] # 标签数据
# 数据归一化
X = (X - np.min(X, axis=0)) / (np.max(X, axis=0) - np.min(X, axis=0))
# 使用sklearn方式
# X = MinMaxScaler().transform(X)
# 查看df信息
# df.info()
# df.describe()
return (X.to_numpy(), y.to_numpy())
class AdaboostClassifier(object):
def __init__(self,modelList=[]):
self.modelList = modelList
def fit(self,X:np.array,y:np.array):
# 样本权重,初始化成相等值,设定每个样本的权重都是相等的,即1/n
D = np.ones((len(y)))*1/len(y)
alpha_list =[]
for model in self.modelList:
model.fit(X, y,sample_weight=D) # 加上每个样本对应的权重
# 计算错误率
y_pred = model.predict(X)
err = np.sum(y_pred!=y)/len(y)
# 计算弱学习算法权重
alpha = 1/2*np.log((1-err)/err)
alpha_list.append(alpha)
# 更新样本权重
Z = np.sum(D)
D = np.asarray([d/Z*np.exp(alpha*(-1)**(y_pred[i]==y[i])) for i,d in enumerate(D)])
self.alpha_list=alpha_list
def predict(self,X:np.array):
preds = []
last_preds = []
for model,alpha in zip(self.modelList,self.alpha_list):
y_pred = model.predict(X)
preds.append(y_pred)
last_preds.append(y_pred*alpha)
y_pred = np.sign(np.sum(last_preds,0))
return preds,y_pred
if __name__=="__main__":
dataPath = "../../dataset/titannic/train.csv"
X, y = loadData(dataPath)
y[y==0]=-1 # 转成{-1,+1}标记,不使用{0,1}标记
# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=40)
modelList = []
for i in range(5):
modelList.append(DecisionTreeClassifier("entropy", "random",random_state=i))
# modelList.append(DecisionTreeClassifier(random_state=9))
# modelList.append(DecisionTreeClassifier(splitter="random", random_state=0))
# modelList.append(DecisionTreeClassifier("entropy", random_state=9))
# modelList.append(DecisionTreeClassifier("entropy", "random", random_state=0))
# modelList.append(DecisionTreeClassifier("entropy", "random", random_state=12))
# modelList.append(LogisticRegression(penalty='l2', max_iter=1000, C=1.5))
# modelList.append(LogisticRegression(penalty='l1', max_iter=1000, C=1.5))
# modelList.append(LogisticRegression(penalty='l2', max_iter=2000, C=1.5))
# modelList.append(LogisticRegression(penalty='l1', max_iter=5000, C=1.5))
# modelList.append(LogisticRegression(penalty='l2', max_iter=5000, C=1.5))
clf = AdaboostClassifier(modelList)
clf.fit(X_train,y_train)
preds,y_pred = clf.predict(X_test)
# 计算acc
# 每个单独的分类器的acc
for i in range(len(modelList)):
print("model:%d acc:%.5f" % (i, accuracy_score(preds[i], y_test)))
# bagging的acc
print("AdaBoost acc:%.5f" % (accuracy_score(y_pred, y_test)))
# 使用sklearn 的 AdaBoostClassifier
clf = AdaBoostClassifier(DecisionTreeClassifier(),10)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("sklearn AdaBoost acc:%.5f" % (accuracy_score(y_pred, y_test)))