import numpy as np
import matplotlib.pyplot as plt
"""
Desc:
创建单层决策树的数据集
Parameters:
None
Returns:
dataMat - 数据矩阵
classLabels - 数据标签
"""
def loadsimpData():
datMat = np.matrix([[1. , 2.1],
[1.5, 1.6],
[1.3, 1. ],
[1. , 1. ],
[2. , 1. ]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datMat, classLabels
"""
Desc:
单层决策树分类函数
Parameters:
dataMatrix - 数据矩阵
dimen - 第dimen列,也就是第几个特征
threshVal - 阈值
threshIneq - 标志
Returns:
retArray - 分类结果
"""
def stumpClassify(dataMatrix, dimen, threshVal, threshIneq):
retArray = np.ones((np.shape(dataMatrix)[0], 1))
if threshIneq == 'lt':
retArray[dataMatrix[:, dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:, dimen] > threshVal] = -1.0
return retArray
"""
Desc:
找到数据集上最佳的单层决策树
Parameters:
dataArr - 数据矩阵
classLabels - 数据标签
D - 样本权重,每个样本权重相等 1/n
Returns:
bestStump - 最佳单层决策树信息
minError - 最小误差
"""
def buildStump(dataArr, classLabels, D):
dataMatrix = np.mat(dataArr)
labelMat = np.mat(classLabels).T
m, n = np.shape(dataMatrix)
numSteps = 10.0
bestStump = {}
bestClasEst = np.mat(np.zeros((m, 1)))
minError = float('inf')
for i in range(n):
rangeMin = dataMatrix[:, i].min()
rangeMax = dataMatrix[:, i].max()
stepSize = (rangeMax - rangeMin) / numSteps
for j in range(-1, int(numSteps) + 1):
for inequal in ['lt', 'gt']:
threshVal = (rangeMin + float(j) * stepSize)
predictedVals = stumpClassify(dataMatrix, i, threshVal, inequal)
errArr = np.mat(np.ones((m, 1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T * errArr
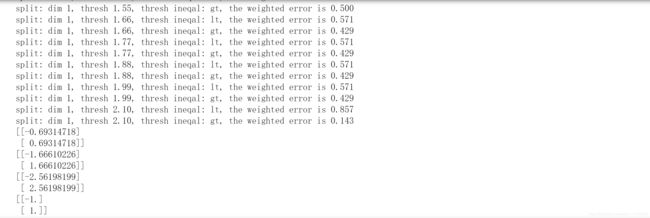
print("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError))
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump, minError, bestClasEst
"""
Desc:
使用AdaBoost进行优化
Parameters:
dataArr - 数据矩阵
classLabels - 数据标签
numIt - 最大迭代次数
Returns:
weakClassArr - 存储单层决策树的list
aggClassEsc - 训练的label
"""
def adaBoostTrainDS(dataArr, classLabels, numIt=40):
weakClassArr = []
m = np.shape(dataArr)[0]
D = np.mat(np.ones((m, 1)) / m)
aggClassEst = np.mat(np.zeros((m, 1)))
for i in range(numIt):
bestStump, error, classEst = buildStump(dataArr, classLabels, D)
alpha = float(0.5 * np.log((1.0 - error) / max(error, 1e-16)))
bestStump['alpha'] = alpha
weakClassArr.append(bestStump)
expon = np.multiply(-1 * alpha * np.mat(classLabels).T, classEst)
D = np.multiply(D, np.exp(expon))
D = D / D.sum()
aggClassEst += alpha * classEst
aggErrors = np.multiply(np.sign(aggClassEst) != np.mat(classLabels).T, np.ones((m, 1)))
errorRate = aggErrors.sum() / m
if errorRate == 0.0:
break
return weakClassArr, aggClassEst
"""
Desc:
AdaBoost分类函数
Parameters:
datToClass - 待分类样例
classifierArr - 训练好的分类器
Returns:
分类结果
"""
def adaClassify(datToClass, classifierArr):
dataMatrix = np.mat(datToClass)
m = np.shape(dataMatrix)[0]
aggClassEst = np.mat(np.zeros((m, 1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix, classifierArr[i]['dim'], classifierArr[i]['thresh'], classifierArr[i]['ineq'])
aggClassEst += classifierArr[i]['alpha'] * classEst
print(aggClassEst)
return np.sign(aggClassEst)
"""
Desc:
数据可视化
Parameters:
dataMat - 数据矩阵
classLabels - 数据标签
Returns:
None
"""
def showDataSet(dataMat, labelMat):
data_plus = []
data_minus = []
for i in range(len(dataMat)):
if labelMat[i] > 0:
data_plus.append(dataMat[i])
else:
data_minus.append(dataMat[i])
data_plus_np = np.array(data_plus)
data_minus_np = np.array(data_minus)
plt.scatter(np.transpose(data_plus_np)[0], np.transpose(data_plus_np)[1])
plt.scatter(np.transpose(data_minus_np)[0], np.transpose(data_minus_np)[1])
plt.show()
if __name__ == '__main__':
dataArr, classLabels = loadsimpData()
weakClassArr, aggClassEst = adaBoostTrainDS(dataArr, classLabels)
print(adaClassify([[0, 0], [5, 5]], weakClassArr))
import numpy as np
import matplotlib.pyplot as plt
"""
Desc:
加载文件
Parameters:
fileName - 文件名
Returns:
dataMat - 数据矩阵
labelMat - 数据标签
"""
def loadDataSet(fileName):
numFeat = len((open(fileName).readline().split('\t')))
dataMat = []
labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numFeat - 1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat, labelMat
"""
Desc:
单层决策树分类函数
Parameters:
dataMatrix - 数据矩阵
dimen - 第dimen列,也就是第几个特征
threshVal - 阈值
threshIneq - 标志
Returns:
retArray - 分类结果
"""
def stumpClassify(dataMatrix, dimen, threshVal, threshIneq):
retArray = np.ones((np.shape(dataMatrix)[0], 1))
if threshIneq == 'lt':
retArray[dataMatrix[:, dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:, dimen] > threshVal] = -1.0
return retArray
"""
Desc:
找到数据集上最佳的单层决策树
Parameters:
dataArr - 数据矩阵
classLabels - 数据标签
D - 样本权重,每个样本权重相等 1/n
Returns:
bestStump - 最佳单层决策树信息
minError - 最小误差
bestClassEst - 最佳的分类结果
"""
def buildStump(dataArr, classLabels, D):
dataMatrix = np.mat(dataArr)
labelMat = np.mat(classLabels).T
m, n = np.shape(dataMatrix)
numSteps = 10.0
bestStump = {}
bestClasEst = np.mat(np.zeros((m, 1)))
minError = float('inf')
for i in range(n):
rangeMin = dataMatrix[:, i].min()
rangeMax = dataMatrix[:, i].max()
stepSize = (rangeMax - rangeMin) / numSteps
for j in range(-1, int(numSteps) + 1):
for inequal in ['lt', 'gt']:
threshVal = (rangeMin + float(j) * stepSize)
predictedVals = stumpClassify(dataMatrix, i, threshVal, inequal)
errArr = np.mat(np.ones((m, 1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T * errArr
print("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError))
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump, minError, bestClasEst
"""
Desc:
使用AdaBoost进行优化
Parameters:
dataArr - 数据矩阵
classLabels - 数据标签
numIt - 最大迭代次数
Returns:
weakClassArr - 存储单层决策树的list
aggClassEsc - 训练的label
"""
def adaBoostTrainDS(dataArr, classLabels, numIt=60):
weakClassArr = []
m = np.shape(dataArr)[0]
D = np.mat(np.ones((m, 1)) / m)
aggClassEst = np.mat(np.zeros((m, 1)))
for i in range(numIt):
bestStump, error, classEst = buildStump(dataArr, classLabels, D)
alpha = float(0.5 * np.log((1.0 - error) / max(error, 1e-16)))
bestStump['alpha'] = alpha
weakClassArr.append(bestStump)
expon = np.multiply(-1 * alpha * np.mat(classLabels).T, classEst)
D = np.multiply(D, np.exp(expon))
D = D / D.sum()
aggClassEst += alpha * classEst
aggErrors = np.multiply(np.sign(aggClassEst) != np.mat(classLabels).T, np.ones((m, 1)))
errorRate = aggErrors.sum() / m
if errorRate == 0.0:
break
return weakClassArr, aggClassEst
"""
Desc:
AdaBoost分类函数
Parameters:
datToClass - 待分类样例
classifierArr - 训练好的分类器
Returns:
分类结果
"""
def adaClassify(datToClass, classifierArr):
dataMatrix = np.mat(datToClass)
m = np.shape(dataMatrix)[0]
aggClassEst = np.mat(np.zeros((m, 1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix, classifierArr[i]['dim'], classifierArr[i]['thresh'], classifierArr[i]['ineq'])
aggClassEst += classifierArr[i]['alpha'] * classEst
return np.sign(aggClassEst)
if __name__ == '__main__':
dataArr, LabelArr = loadDataSet('horseColicTraining2.txt')
weakClassArr, aggClassEst = adaBoostTrainDS(dataArr, LabelArr)
testArr, testLabelArr = loadDataSet('horseColicTest2.txt')
print(weakClassArr)
predictions = adaClassify(dataArr, weakClassArr)
errArr = np.mat(np.ones((len(dataArr), 1)))
print('训练集的错误率:%.3f%%' % float(errArr[predictions != np.mat(LabelArr).T].sum() / len(dataArr) * 100))
predictions = adaClassify(testArr, weakClassArr)
errArr = np.mat(np.ones((len(testArr), 1)))
print('测试集的错误率:%.3f%%' % float(errArr[predictions != np.mat(testLabelArr).T].sum() / len(testArr) * 100))

import numpy as np
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
"""
Desc:
加载文件
Parameters:
fileName - 文件名
Returns:
dataMat - 数据矩阵
labelMat - 数据标签
"""
def loadDataSet(fileName):
numFeat = len((open(fileName).readline().split('\t')))
dataMat = []
labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numFeat - 1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat, labelMat
if __name__ == '__main__':
dataArr, classLabels = loadDataSet('horseColicTraining2.txt')
testArr, testLabelArr = loadDataSet('horseColicTest2.txt')
bdt = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2), algorithm="SAMME", n_estimators=10)
bdt.fit(dataArr, classLabels)
predictions = bdt.predict(dataArr)
errArr = np.mat(np.zeros((len(dataArr), 1)))
for i in range(len(classLabels)):
if classLabels[i] != predictions[i]:
errArr[i] = 1
print('训练集的错误率:%.3f%%' % float(errArr.sum() / len(dataArr) * 100))
predictions = bdt.predict(testArr)
errArr = np.mat(np.zeros((len(testArr), 1)))
for i in range(len(testLabelArr)):
if testLabelArr[i] != predictions[i]:
errArr[i] = 1
print('测试集的错误率:%.3f%%' % float(errArr.sum() / len(testArr) * 100))
'''
训练集的错误率:16.054%
测试集的错误率:17.910%
'''
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
"""
Desc:
加载文件
Parameters:
fileName - 文件名
Returns:
dataMat - 数据矩阵
labelMat - 数据标签
"""
def loadDataSet(fileName):
numFeat = len((open(fileName).readline().split('\t')))
dataMat = []
labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numFeat - 1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat, labelMat
"""
Desc:
单层决策树分类函数
Parameters:
dataMatrix - 数据矩阵
dimen - 第dimen列,也就是第几个特征
threshVal - 阈值
threshIneq - 标志
Returns:
retArray - 分类结果
"""
def stumpClassify(dataMatrix, dimen, threshVal, threshIneq):
retArray = np.ones((np.shape(dataMatrix)[0], 1))
if threshIneq == 'lt':
retArray[dataMatrix[:, dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:, dimen] > threshVal] = -1.0
return retArray
"""
Desc:
找到数据集上最佳的单层决策树
Parameters:
dataArr - 数据矩阵
classLabels - 数据标签
D - 样本权重,每个样本权重相等 1/n
Returns:
bestStump - 最佳单层决策树信息
minError - 最小误差
bestClassEst - 最佳的分类结果
"""
def buildStump(dataArr, classLabels, D):
dataMatrix = np.mat(dataArr)
labelMat = np.mat(classLabels).T
m, n = np.shape(dataMatrix)
numSteps = 10.0
bestStump = {}
bestClasEst = np.mat(np.zeros((m, 1)))
minError = float('inf')
for i in range(n):
rangeMin = dataMatrix[:, i].min()
rangeMax = dataMatrix[:, i].max()
stepSize = (rangeMax - rangeMin) / numSteps
for j in range(-1, int(numSteps) + 1):
for inequal in ['lt', 'gt']:
threshVal = (rangeMin + float(j) * stepSize)
predictedVals = stumpClassify(dataMatrix, i, threshVal, inequal)
errArr = np.mat(np.ones((m, 1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T * errArr
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump, minError, bestClasEst
"""
Desc:
使用AdaBoost进行优化
Parameters:
dataArr - 数据矩阵
classLabels - 数据标签
numIt - 最大迭代次数
Returns:
weakClassArr - 存储单层决策树的list
aggClassEsc - 训练的label
"""
def adaBoostTrainDS(dataArr, classLabels, numIt=60):
weakClassArr = []
m = np.shape(dataArr)[0]
D = np.mat(np.ones((m, 1)) / m)
aggClassEst = np.mat(np.zeros((m, 1)))
for i in range(numIt):
bestStump, error, classEst = buildStump(dataArr, classLabels, D)
alpha = float(0.5 * np.log((1.0 - error) / max(error, 1e-16)))
bestStump['alpha'] = alpha
weakClassArr.append(bestStump)
expon = np.multiply(-1 * alpha * np.mat(classLabels).T, classEst)
D = np.multiply(D, np.exp(expon))
D = D / D.sum()
aggClassEst += alpha * classEst
aggErrors = np.multiply(np.sign(aggClassEst) != np.mat(classLabels).T, np.ones((m, 1)))
errorRate = aggErrors.sum() / m
if errorRate == 0.0:
break
return weakClassArr, aggClassEst
"""
Desc:
绘制ROC
Parameters:
predStrengths - 分类器的预测强度
classLabels - 类别
Returns:
None
"""
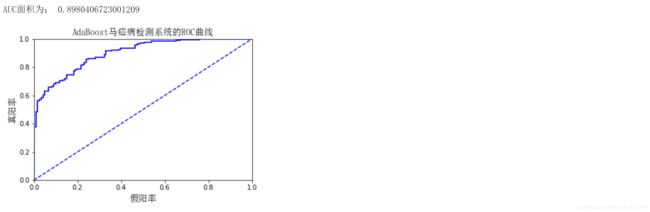
def plotROC(predStrengths, classLabels):
font = FontProperties(fname=r"C:\Windows\Fonts\simsun.ttc", size=14)
cur = (1.0, 1.0)
ySum = 0.0
numPosClas = np.sum(np.array(classLabels) == 1.0)
yStep = 1 / float(numPosClas)
xStep = 1 / float(len(classLabels) - numPosClas)
sortedIndicies = predStrengths.argsort()
fig = plt.figure()
fig.clf()
ax = plt.subplot(111)
for index in sortedIndicies.tolist()[0]:
if classLabels[index] == 1.0:
delX = 0
delY = yStep
else:
delX = xStep
delY = 0
ySum += cur[1]
ax.plot([cur[0], cur[0] - delX], [cur[1], cur[1] - delY], c='b')
cur = (cur[0] - delX, cur[1] - delY)
ax.plot([0, 1], [0, 1], 'b--')
plt.title('AdaBoost马疝病检测系统的ROC曲线', FontProperties=font)
plt.xlabel('假阳率', FontProperties=font)
plt.ylabel('真阳率', FontProperties=font)
ax.axis([0, 1, 0, 1])
print('AUC面积为:', ySum * xStep)
plt.show()
if __name__ == '__main__':
dataArr, LabelArr = loadDataSet('horseColicTraining2.txt')
weakClassArr, aggClassEst = adaBoostTrainDS(dataArr, LabelArr)
plotROC(aggClassEst.T, LabelArr)