吴恩达 序列模型_学习笔记3 seq2seq 序列模型和注意力机制
我也是一个nlp新手,在这里将自己的学习心得总结下来,希望可以帮助到也在共同学习的同志们。
目录
- 1、基本概念
- 2、选择最可能的句子
- 3、Beam search 算法
- 4、改进的Beam search
- 5、Beam search的误差分析
- 6、Bleu(Bilingual evalution understudy )评分
- 7-8 注意力机制
- 9、语音辨别
- 10、触发字检测
1、基本概念
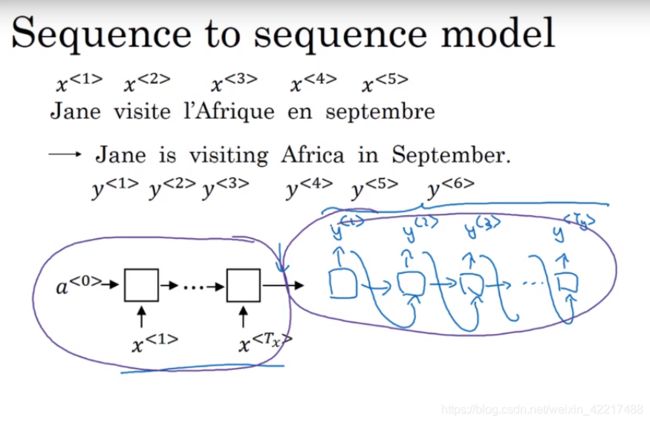
回顾第一周的不同类型的RNN,seq2seq模型一般如下,其中前半部分可以看做是编码器,后半部分是一个解码器。而每一个单元可以是RNN单元也可以是LSTM或者GRU.
seq2seq模型一个十分常见的使用场景就是文本翻译,下面的内容也多以文本翻译的例子讲解。
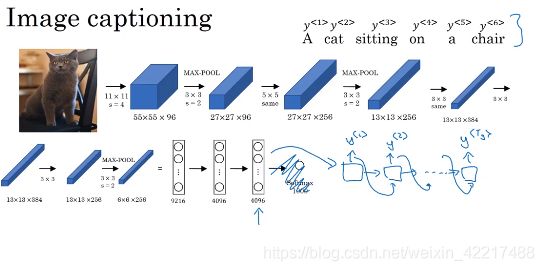
CNN和解码器的连接完成图像注释。其中CNN部分可以看成是在做特征提取,后面是在做特征解码。
2、选择最可能的句子
我们可以发现,seq2seq模型的后半部分和语言模型十分相似,语言模型是要输出一个句子的概率:
P ( y < 1 > , y < 2 > , … , y < T y > ) P(y^{<1>},y^{<2>},\dots,y^{
而不同于语言模型的是,seq2seq模型是一个条件概率模型:
P ( y < 1 > , y < 2 > , … , y < T y > ∣ x < 1 > , x < 2 > , … , x < T x > ) P(y^{<1>},y^{<2>},\dots,y^{

在我们训练前向传播(预测)的时候,可能会出现好几种翻译方式。我们的目标是获得最有可能的翻译。

贪心算法
每一步都选择概率最大的单词组成句子。

为什么并不用贪心算法
因为每一步最优不一定全局最优,就比如最速梯度下降中出现的zig-zag现象,过犹不及。如何感性认识呢?就比如老师这里举得例子。如果我们只考虑按顺序达到最优,那么在进行到第三个单词时,这个最优的就会造成全局的非最优。
3、Beam search 算法
上面介绍了在预测的时候,我们不能使用贪心算法。Beam search是解决上述问题的一个常见算法。 beam search存在一个超参数(beam width)。这里假设beam width=3.就是在每一步得到一个单词的概率之后,我们选择概率最大的三个单词。在进行下一步解码的时候,对每一个单词进行向下传播。这样就会有310000个组合方式,分别表示表示 P ( y < 2 > ∣ x , y < 1 > ) P(y^{<2>}|x,y^{<1>}) P(y<2>∣x,y<1>)。接着我们在这三万种组合中选择概率最大的三个,再向下传播,产生310000种组合方式,分别表示 P ( y < 3 > ∣ x , y < 1 > , y < 2 > ) P(y^{<3>}|x,y^{<1>},y^{<2>}) P(y<3>∣x,y<1>,y<2>)。一直向下递归,我们就可以得到相对概率最大的句子。
因为 P ( y < 1 > , y < 2 > , … , y < T y > ∣ x ) = P ( y < 1 > ∣ x ) P ( y < 2 > ∣ x , y < 1 > ) , … , P ( y < T y > ∣ x , y < 1 > , y < 1 > . … , y < T y − 1 > ) P(y^{<1>},y^{<2>},\dots,y^{

可以发现,当B=1时,上述算法就是贪心算法
4、改进的Beam search
观察上面的过程,我们可以发现上面的算法的目标是最大化下式。
现在有几个问题:
1、如果是直接取概率,我们最后得到的概率是一个很小的值,可能会造成下溢,所以我们取了log
2、我们发现,长度越长的句子的概率越低,所以生成的句子会偏向低概率,所以要做一个长度上的标准化。

5、Beam search的误差分析
我们把Beam search 运用到seq2seq的时候,要适当调节Beam Width,但是这个Beam Width如何调节呢?结果不好的原因是因为模型还是搜索算法呢?为了解决这个调参问题,我们就要进行误差分析。
主要思路是计算真实标签的概率值和预测得到的句子的概率值。当真实标签的概率大于预测得时,说明是我们的搜索算法不够好


具体在实践中,对于所有的数据,我们分别计算是模型还是搜索算法造成的错误多。据此来调整模型或者参数。

6、Bleu(Bilingual evalution understudy )评分
在进行机器翻译的时候,我们需要一个可以对其进行评估的指标。比较常用的指标就是BLEU。简单地说,这个评分是计算真实标签中的词块在估计出来的结果中的词块(n-gram)的比值,
具体的计算方法如下:


实际中,bleu存在一些问题:
1、n的取值
2、该得分对于一些短的句子更加偏好。
对于上述问题作出如下改变

7-8 注意力机制
注意力机制最早由Bahdanau et.al.,2014在机器翻译的论文中发现,主要是为了解决机器翻译随着句子长度的增长,导致得分下降的问题。
注意力机制的思路和我们人类自己做翻译的思路很一致,就是逐字翻译。比如我们翻译“I love China”,当我们翻译到“爱”时就把注意力集中在“love”上。
那么这个思路是怎么实现的呢?
关键在于引入一个 α < t , t ′ > \alpha^{
s t = f ( s t − 1 , y t − 1 , c t ) s_{t}=f(s_{t-1},y_{t-1},c_{t}) st=f(st−1,yt−1,ct),而输出为 y ^ = g ( s t ) \hat{y}=g(s_{t}) y^=g(st)
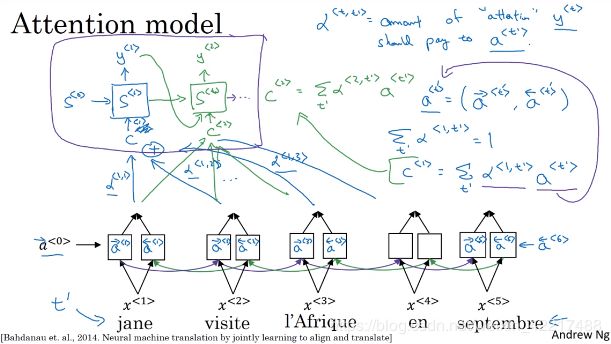
上述的内容其实还相对比较好理解,主要是我们有个假设 α < t , t ′ > \alpha^{
首先我们思考这个注意力和什么有关系?我们回到对注意力最初的思路——逐词翻译。那么也就是说,如果要翻译的词和原文之间有一定相关性的话,那么注意力就要集中在这里。确实差不多也是这么个意思。 α < t , t ′ > \alpha^{
α t = s o f t m a x ( s t − 1 T a 1 , … , s t − 1 T a t ′ ) \alpha_{t}=softmax(s_{t-1}^{T}a_{1},\dots,s_{t-1}^{T}a_{t^{'}}) αt=softmax(st−1Ta1,…,st−1Tat′)
这里的 s t − 1 T a 1 , … , s t − 1 T a t ′ s_{t-1}^{T}a_{1},\dots,s_{t-1}^{T}a_{t^{'}} st−1Ta1,…,st−1Tat′可以看做是求翻译的词和原文之间相关性。那么在反向传播的时候,对于这个相关性高的词就会权重变大。而这个softmax函数也比较好理解,就是把计算出来的相关性变成0-1的概率分布(注意力)。除了这种相关性的算法,还有神经网络的算法, α t = s o f t m a x ( t a n h ( W 1 a + W 2 s t − 1 ) ) \alpha_{t}=softmax(tanh(W_{1}a+W_{2}s_{t-1})) αt=softmax(tanh(W1a+W2st−1))
类似的还有很多,但是都得用到原词 a t a_{t} at和要翻译的词 s t − 1 s_{t-1} st−1。
最后得到的 α < t , t ′ > \alpha^{

看这个注意力分布,也是十分符合我们逐词翻译的假设。
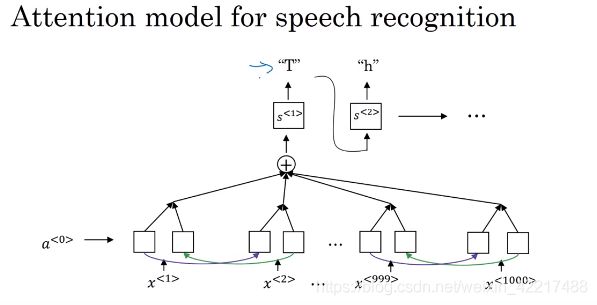
9、语音辨别
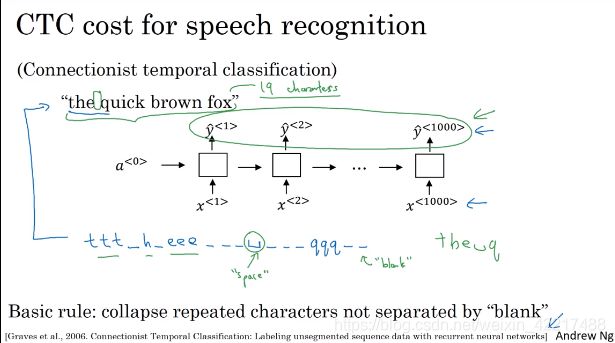
task:根据音频输出文字
problems:输入的10s的音频,可能是100Hz的,也就是10秒共有1000个输入,需要我们根据100个输入预测十多个字符。
解决:
1、CTC
强行产生1000个输出,然后对1000个输出做一个整和。
2.注意力机制
seq2seq+attention 的思路
10、触发字检测
类似于siri和小爱同学这种的,用语音控制执行任务的应用。有一种思路是输入为音频特征,输出全部为0-1,这样的问题是标签不平衡,一个简单粗暴的做法是添加trigger附近的1。

我也是一个nlp新手,在这里将自己的学习心得总结下来,希望可以帮助到也在共同学习的同志们。如果我上述的有任何错误,欢迎留言交流,我都将虚心接受。