使用memcpy函数的耗时测试(拷贝不同大小数据量耗时不同)
今天公司里的一个大神给我普及了一下知识,使用memcpy函数的耗时在拷贝不同大小数据的时候,速度是不一样的,于是我写了个程序测试了一下,具体如下:
目标:比较 使用memcpy()拷贝1k,4k,16k,512k,2M,4M,8M,16M,128M,500M数据的耗时
主要代码如下(编译时会自动区分当前是什么系统):
#include "mainwindow.h"
#include "ui_mainwindow.h"
#include
#if defined(Q_OS_LINUX)
#include "time.h"
#else
#include
class chronograph
{
public:
chronograph()
{
QueryPerformanceFrequency(&m_freq);
QueryPerformanceCounter(&m_bgn);
}
void start()
{
QueryPerformanceCounter(&m_bgn);
}
double duration()
{
QueryPerformanceCounter(&m_end);
return (m_end.QuadPart - m_bgn.QuadPart) * 1000.0 / m_freq.QuadPart;
}
LARGE_INTEGER now()
{
LARGE_INTEGER now;
QueryPerformanceCounter(&now);
return now;
}
double DoubleNow()
{
LARGE_INTEGER now;
QueryPerformanceCounter(&now);
return now.QuadPart*1000.0 / m_freq.QuadPart;
}
private:
LARGE_INTEGER m_freq;
LARGE_INTEGER m_bgn;
LARGE_INTEGER m_end;
};
#endif
MainWindow::MainWindow(QWidget *parent) :
QMainWindow(parent),
ui(new Ui::MainWindow)
{
ui->setupUi(this);
#if defined(Q_OS_LINUX)
//在linux下测试memcpy的耗时
double usetime1k,usetime4k,usetime16k,usetime512k,usetime2M,usetime4M,usetime8M,usetime16M,usetime128M,usetime500M;
usetime1k = 0;
usetime4k = 0;
usetime16k = 0;
usetime512k = 0;
usetime2M = 0;
usetime4M = 0;
usetime8M = 0;
usetime16M = 0;
usetime128M = 0;
usetime500M = 0;
char *cData1k = new char[1024];//1k
char *cData4k = new char[1024*4];//4k
char *cData16k = new char[1024*16];//16k
char *cData512k = new char[1024*512];//512k
char *cData2M = new char[1024*1024*2];//2M //(char*)malloc(1024*1024*1024*2); //
char *cData4M = new char[1024*1024*4];//4M
char *cData8M = new char[1024*1024*8];//8M
char *cData16M = new char[1024*1024*16];//64M
char *cData128M = new char[1024*1024*128];//128M
char *cData500M = new char[1024*1024*500];//128M
char *cData1kCP = new char[1024];//1k
char *cData4kCP = new char[1024*4];//4k
char *cData16kCP = new char[1024*16];//16k
char *cData512kCP = new char[1024*512];//512k
char *cData2MCP = new char[1024*1024*2];//2M //(char*)malloc(1024*1024*1024*2);//
char *cData4MCP = new char[1024*1024*4];//4M
char *cData8MCP = new char[1024*1024*8];//8M
char *cData16MCP = new char[1024*1024*16];//64M
char *cData128MCP = new char[1024*1024*128];//128M
char *cData500MCP = new char[1024*1024*500];//128M
memset(cData1kCP,1,1024);
memset(cData4kCP,1,1024*4);
memset(cData16kCP,1,1024*16);
memset(cData512kCP,1,1024*512);
memset(cData2MCP,1,1024*1024*2);
memset(cData4MCP,1,1024*1024*4);
memset(cData8MCP,1,1024*1024*8);
memset(cData16MCP,1,1024*1024*16);
memset(cData128MCP,1,1024*1024*128);
memset(cData500MCP,1,1024*1024*500);
struct timespec time1,time2;
for(int i = 0;i<100;i++)
{
clock_gettime(CLOCK_MONOTONIC,&time1);//start time
memcpy(cData1k,cData1kCP,1024*sizeof(char));
clock_gettime(CLOCK_MONOTONIC,&time2);//end time
usetime1k += (time2.tv_sec-time1.tv_sec)*1000.0+(time2.tv_nsec-time1.tv_nsec)/1000000.0;//ms
clock_gettime(CLOCK_MONOTONIC,&time1);//start time
memcpy(cData4k,cData4kCP,1024*4*sizeof(char));
clock_gettime(CLOCK_MONOTONIC,&time2);//end time
usetime4k += (time2.tv_sec-time1.tv_sec)*1000.0+(time2.tv_nsec-time1.tv_nsec)/1000000.0;//ms
clock_gettime(CLOCK_MONOTONIC,&time1);//start time
memcpy(cData16k,cData16kCP,1024*16*sizeof(char));
clock_gettime(CLOCK_MONOTONIC,&time2);//end time
usetime16k += (time2.tv_sec-time1.tv_sec)*1000.0+(time2.tv_nsec-time1.tv_nsec)/1000000.0;//ms
clock_gettime(CLOCK_MONOTONIC,&time1);//start time
memcpy(cData512k,cData512kCP,1024*512*sizeof(char));
clock_gettime(CLOCK_MONOTONIC,&time2);//end time
usetime512k += (time2.tv_sec-time1.tv_sec)*1000.0+(time2.tv_nsec-time1.tv_nsec)/1000000.0;//ms
clock_gettime(CLOCK_MONOTONIC,&time1);//start time
memcpy(cData2M,cData2MCP,1024*1024*2*sizeof(char));
clock_gettime(CLOCK_MONOTONIC,&time2);//end time
usetime2M += (time2.tv_sec-time1.tv_sec)*1000.0+(time2.tv_nsec-time1.tv_nsec)/1000000.0;//ms
clock_gettime(CLOCK_MONOTONIC,&time1);//start time
memcpy(cData4M,cData4MCP,1024*1024*4*sizeof(char));
clock_gettime(CLOCK_MONOTONIC,&time2);//end time
usetime4M += (time2.tv_sec-time1.tv_sec)*1000.0+(time2.tv_nsec-time1.tv_nsec)/1000000.0;//ms
clock_gettime(CLOCK_MONOTONIC,&time1);//start time
memcpy(cData8M,cData8MCP,1024*1024*8*sizeof(char));
clock_gettime(CLOCK_MONOTONIC,&time2);//end time
usetime8M += (time2.tv_sec-time1.tv_sec)*1000.0+(time2.tv_nsec-time1.tv_nsec)/1000000.0;//ms
clock_gettime(CLOCK_MONOTONIC,&time1);//start time
memcpy(cData16M,cData16MCP,1024*1024*16*sizeof(char));
clock_gettime(CLOCK_MONOTONIC,&time2);//end time
usetime16M += (time2.tv_sec-time1.tv_sec)*1000.0+(time2.tv_nsec-time1.tv_nsec)/1000000.0;//ms
clock_gettime(CLOCK_MONOTONIC,&time1);//start time
memcpy(cData128M,cData128MCP,1024*1024*128*sizeof(char));
clock_gettime(CLOCK_MONOTONIC,&time2);//end time
usetime128M += (time2.tv_sec-time1.tv_sec)*1000.0+(time2.tv_nsec-time1.tv_nsec)/1000000.0;//ms
clock_gettime(CLOCK_MONOTONIC,&time1);//start time
memcpy(cData500M,cData500MCP,1024*1024*500*sizeof(char));
clock_gettime(CLOCK_MONOTONIC,&time2);//end time
usetime500M += (time2.tv_sec-time1.tv_sec)*1000.0+(time2.tv_nsec-time1.tv_nsec)/1000000.0;//ms
}
qDebug()<<"memcpy 1k data usetime:"< 在Tx2设备上运行结果如下: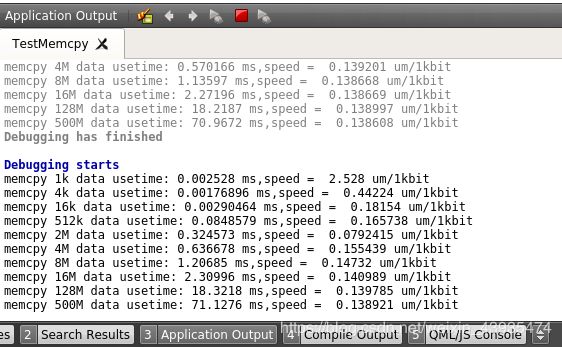
可以看到拷贝数据在2M大小的时候,速度达到峰值。为什么拷贝2M数据速度最快呢,因为Tx2设备的处理器二级缓存就是2M,参数如下图:
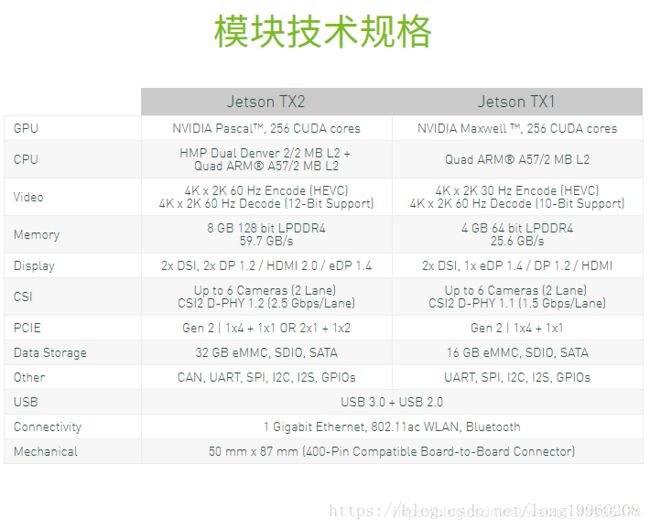
在Thinkpad T570上运行的结果如下:
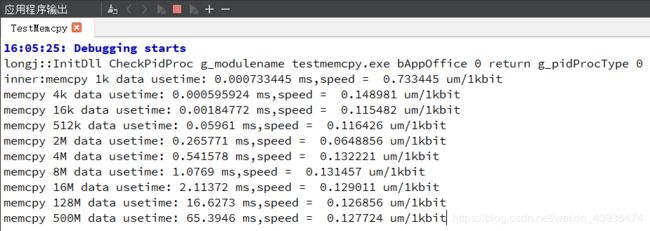
可以看到也是在拷贝2M数据的时候速度最快,CPU为i7-7500U,是3级缓存,大小为4M