以hello world为例,详细分析程序的运行过程
以hello world为例,详细分析程序的运行过程
(一)环境说明:
IDE :Visual Studio 2017
语言:C++
示例代码:
#include
using namespace std;
void main() {
cout << “Hello World”;
}
在点击运行后输出"Hello World"
可以看一下啊该项目的文件树

基本介绍
test1.sln
是整个解决方案(Solution)的配制文件,组织多个工程和相关的元素到一个解决方案中。用鼠标双击它就能用VS打开整个工程项目。
test1.vcxproj:
记录工程(Project)相关的属性配制。
test1.vcxproj.filters:
文件过虑器, "工程结构"中各个文件的组织和编排都是定义在这个文件中的。
test1.vcxproj.user:
用户相关的一些配制。
源.cpp
存放源代码
test1.ilk文件是连接时生成的文件
test1.pdb 可以保存调试信息
test1/Debug 里主要存放一些日志信息
在整个项目中的test1.exe(二进制可执行文件)就是可以被计算机执行的程序
该"Hello World"程序执行过程可以分析以下两个阶段
-
程序编译的过程
-
exe文件的执行过程
(二)程序编译过程
为了能让机器读懂我们语言,所以需要进行一系列的转换,将高级语言转换为机器能读懂的低级语言指令,然后这些指令按照一种称为可执行目标程序的格式打包好,以二进制磁盘文件形式存放起来,目标程序也称为可执行程序
C++程序目标文件和可执行文件结构
目标文件和可执行文件可以有几种不同的格式,有ELF(Excutable and linking Format,可执行文件和链接)格式,也有COFF(Common Object-File Format,普通目标文件格式)。虽然格式不一样,但具有一个共同的概念,那就是段(segments),这里段指二进制格式文件中的一块区域。
linux下的可执行文件有三个段文本段(text)、数据段(data)、bss段,可用nm命令查看目标文件的符号清单。
编译过程: 源文件-------->到可执行文件
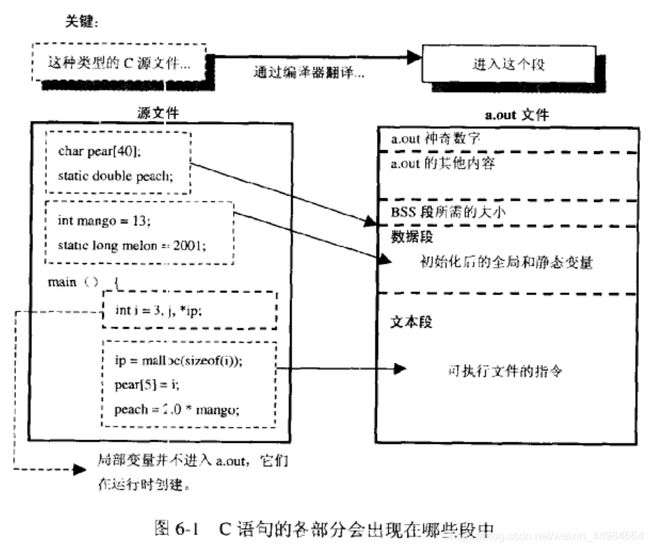
图引自《C专家编程》
从源文件到目标文件的转换是由编译器驱动程序完成的。
分为以下几个阶段:
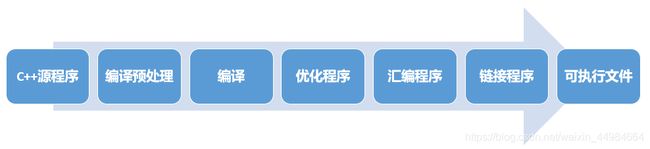
1.编译预处理
读取C++源程序,对其中的伪指令(以#开头的指令)和特殊符号进行处理。
伪指令主要包括以下四个方面
(1)宏定义指令,如# define Name TokenString,#undef等。对于前一个伪指令,预编译所要作得的是将程序中的所有Name用TokenString替换,但作为字符串常量的Name则不被替换。对于后者,则将取消对某个宏的定义,使以后该串的出现不再被替换。
(2)条件编译指令,如#ifdef,#ifndef,#else,#elif,#endif,等等。这些伪指令的引入使得程序员可以通过定义不同的宏来决定编译程序对哪些代码进行处理。预编译程序将根据有关的文件,将那些不必要的代码过滤掉。
(3)头文件包含指令,如#include “FileName"或者#include
包含到c源程序中的头文件可以是系统提供的,这些头文件一般被放在/usr/include目录下。在程序中#include它们要使用尖括号(<>)。另外开发人员也可以定义自己的头文件,这些文件一般与C++源程序放在同一目录下,此时在#include中要用双引号(”")。
(4)特殊符号,预编译程序可以识别一些特殊的符号。例如在源程序中出现的LINE标识将被解释为当前行号(十进制数),FILE则被解释为当前被编译的C源程序的名称。预编译程序对于在源程序中出现的这些串将用合适的值进行替换。
预编译程序所完成的基本上是对源程序的"替代"工作。经过此种替代,生成一个没有宏定义、没有条件编译指令、没有特殊符号的输出文件。这个文件的含义同没有经过预处理的源文件是相同的,但内容有所不同。下一步,此输出文件将作为编译程序的输出而被翻译成为机器指令。
2.编译阶段
经过预编译得到的输出文件中,将只有常量。如数字、字符串、变量的定义,以及C++语言的关键字,如main,if,else,for,while,{,},+,-,*,\,等等。预编译程序所要作得工作就是通过词法分析和语法分析,在确认所有的指令都符合语法规则之后,将其翻译成等价的中间代码表示或汇编代码。
3.优化阶段
优化处理是编译系统中一项比较艰深的技术。它涉及到的问题不仅同编译技术本身有关,而且同机器的硬件环境也有很大的关系。优化一部分是对中间代码的优化。这种优化不依赖于具体的计算机。另一种优化则主要针对目标代码的生成而进行的。
对于前一种优化,主要的工作是删除公共表达式、循环优化(代码外提、强度削弱、变换循环控制条件、已知量的合并等)、复写传播,以及无用赋值的删除,等等。
后一种类型的优化同机器的硬件结构密切相关,最主要的是考虑是如何充分利用机器的各个硬件寄存器存放的有关变量的值,以减少对于内存的访问次数。另外,如何根据机器硬件执行指令的特点(如流水线、RISC、CISC、VLIW等)而对指令进行一些调整使目标代码比较短,执行的效率比较高,也是一个重要的研究课题。
经过优化得到的汇编代码必须经过汇编程序的汇编转换成相应的机器指令,方可能被机器执行。
4.汇编过程
汇编过程实际上指把汇编语言代码翻译成目标机器指令的过程。对于被翻译系统处理的每一个C++语言源程序,都将最终经过这一处理而得到相应的目标文件。目标文件中所存放的也就是与源程序等效的目标的机器语言代码。
目标文件由段组成。通常一个目标文件中至少有两个段:
代码段 该段中所包含的主要是程序的指令。该段一般是可读和可执行的,但一般却不可写。
数据段 主要存放程序中要用到的各种全局变量或静态的数据。一般数据段都是可读,可写,可执行的。
UNIX环境下主要有三种类型的目标文件:
(1)可重定位文件 其中包含有适合于其它目标文件链接来创建一个可执行的或者共享的目标文件的代码和数据。
(2)共享的目标文件 这种文件存放了适合于在两种上下文里链接的代码和数据。第一种事链接程序可把它与其它可重定位文件及共享的目标文件一起处理来创建另一个目标文件;第二种是动态链接程序将它与另一个可执行文件及其它的共享目标文件结合到一起,创建一个进程映象。
(3)可执行文件 它包含了一个可以被操作系统创建一个进程来执行之的文件。
汇编程序生成的实际上是第一种类型的目标文件。对于后两种还需要其他的一些处理方能得到,这个就是链接程序的工作了。
5.链接程序
由汇编程序生成的目标文件并不能立即就被执行,其中可能还有许多没有解决的问题。例如,某个源文件中的函数可能引用了另一个源文件中定义的某个符号(如变量或者函数调用等);在程序中可能调用了某个库文件中的函数,等等。所有的这些问题,都需要经链接程序的处理方能得以解决。
举个简单的例子,如果程序A中引用了文件B中定义的函数,为了A中的函数能正常执行,就需要把B中的函数部分也放在A的源代码中,那么将A和B合并成一个文件的过程就是链接了。有专门的过程用来链接程序,称为链接器。他将一些输入的目标文件加工后合成一个输出文件。这些目标文件中往往有相互的数据、函数引用。
链接程序的主要工作就是将有关的目标文件彼此相连接,也即将在一个文件中引用的符号同该符号在另外一个文件中的定义连接起来,使得所有的这些目标文件成为一个能够被操作系统装入执行的统一整体。
根据开发人员指定的同库函数的链接方式的不同,链接处理可分为两种:
(1)静态链接 在这种链接方式下,函数的代码将从其所在地静态链接库中被拷贝到最终的可执行程序中。这样该程序在被执行时这些代码将被装入到该进程的虚拟地址空间中。静态链接库实际上是一个目标文件的集合,其中的每个文件含有库中的一个或者一组相关函数的代码。
(2)动态链接 在此种方式下,函数的代码被放到称作是动态链接库或共享对象的某个目标文件中。链接程序此时所作的只是在最终的可执行程序中记录下共享对象的名字以及其它少量的登记信息。在此可执行文件被执行时,动态链接库的全部内容将被映射到运行时相应进程的虚地址空间。动态链接程序将根据可执行程序中记录的信息找到相应的函数代码。
对于可执行文件中的函数调用,可分别采用动态链接或静态链接的方法。使用动态链接能够使最终的可执行文件比较短小,并且当共享对象被多个进程使用时能节约一些内存,因为在内存中只需要保存一份此共享对象的代码。但并不是使用动态链接就一定比使用静态链接要优越。在某些情况下动态链接可能带来一些性能上损害。
经过上述五个过程,C源程序就最终被转换成可执行文件了
(三)exe文件的执行过程
EXE File英文全名executable file ,译作可执行文件,可移植可执行 (PE) 文件格式的文件,它可以加载到内存中,并由操作系统加载程序执行,是可在操作系统存储空间中浮动定位的可执行程序。
EXE文件分为两个部分: EXE文件头和程序本体。exe文件比较复杂,属于一种多段的结构,是DOS最成功和复杂的设计之一。每个exe文件包含一个文件头和一个可重定位程序的映像。文件头包含MS-DOS用于加载程序的信息,例如程序的大小和寄存器的初始值。文件头还指向一个重定位表,该表包含指向程序映像中可重定位段地址的指针链表。MS-DOS通过把该映像直接从文件复制到内存加载exe程序,然后调整定位表中说明的可重定位段地址。定位表是一个重定位指针数组,每个指向程序映像中的可重定位段地址

可执行文件中的段在内存中的布局
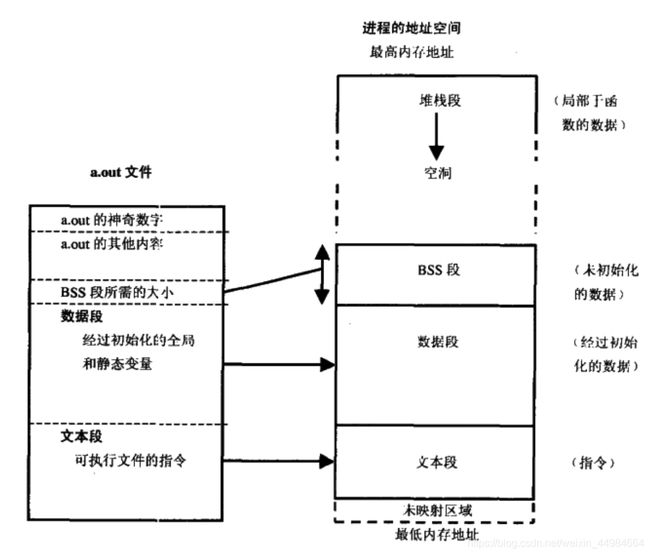
exe文件的执行过程
1、Shell(Explorer.exe )调用CreateProcess函数激活exe程序
2、系统创建一个进程内核对象,引用计数置为1
3、系统为进程创建一个4GB的进程虚拟地址空间
4、PE装载器把exe的代码映射到地址空间,并查找ImportTable引入相关
的动态链接库(DLLs )
5、系统为进程创建一个主线程,线程得到CPU后,把CS:IP指向.text节中
的程序进入点(OEP) ,此处是一条JMP指令,它跳到XXXCRTStartup
函数处执行
6、完成c/c++运行期库的一些初始化设置,包括c++ 构造函数的调用
全局变量,静态变量的初始化
7、调用WinMain/main函数,进入主函数
8、注册窗口类,创建窗口,显示窗口,更新窗口,进入消息循环
9、窗口关闭,循环退出,返回到C/C++ 运行期库
10、完成一些清理工作
11 、最后是ExitProcess退出进程
具体到cout来说(类似于C中的print函数)
是个普通的函数调用,与正常的函数调用没有太大区别。他通过系统调用去请求内核完成在屏幕上打印字符串的动作。
这就是整个"Hello World"程序的执行过程,先由编译器将源文件编译为exe文件(window操作系统中 在Linux中是bin文件)再接着由操作系统执行该二进制文件,实现对应的功能