python的unittest框架如何按自己编好的顺序批量执行的解决方案
利用python的unittest框架批量执行case的加载方式有2种:
1.通过unittest.main()来启动所需测试的测试模块;
2.添加到testsuite集合中再加载所有的被测试对象,而testsuit里存放的就是所需测试的用例;
2.添加到testsuite集合中再加载所有的被测试对象,而testsuit里存放的就是所需测试的用例;
方案大概为以下4种:
1、通过unittest.main()来执行测试用例的方式:
if __name__ == "__main__":
unittest.main()
2、通过testsuit来执行测试用例的方式:
if __name__ == "__main__":
# 构造测试集
suite = unittest.TestSuite()
suite.addTest(TestCase("testCreateFolder"))
suite.addTest(TestCase("testDeleteFolder"))
# 执行测试
runner = unittest.TextTestRunner()
runner.run(suite)
3、通过testLoader 逐一添加测试脚本:
if __name__ == "__main__":
#此用法可以同时测试多个类
suite1 = unittest.TestLoader().loadTestsFromTestCase(TestCase1)
suite2 = unittest.TestLoader().loadTestsFromTestCase(TestCase2)
suite = unittest.TestSuite([suite1, suite2])
unittest.TextTestRunner(verbosity=2).run(suite)
4、通过TestLoader 类中提供的discover():
import
unittest
case_path ="./test_case/"
suite = unittest . defaultTestLoader . discover ( case_path , pattern = "test_*.py" )
if __name__ == '__main__' :
runner = unittest . TextTestRunner ()
runner . run ( suite )
case_path ="./test_case/"
suite = unittest . defaultTestLoader . discover ( case_path , pattern = "test_*.py" )
if __name__ == '__main__' :
runner = unittest . TextTestRunner ()
runner . run ( suite )
然后我们已知unittest默认加载脚本的顺序是:根据ASCII码的顺序加载,数字与字母的顺序为:0-9,A-Z,a-z。所以以A开头的测试用例方法会优先执行,以a开头会后执行。
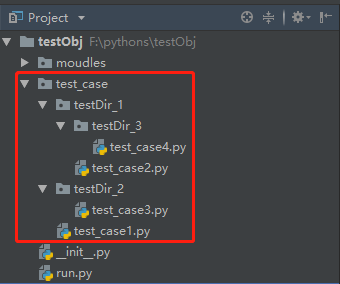
很多情况下,我们的脚本会放在不同的路径下,如图:
【脚本分了很多层级,每一级都有case和下一级目录】
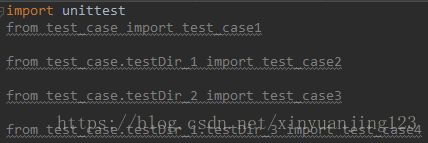
如果我们单个加载case,那么我们首先要做的,是需要在一个run文件的开头,import所有包含case的.py文件
脚本逻辑及框架设计痛点:在case比较多且目录多时,import比较费时费力。而如果使用discover()的方式,则脚本添加的顺序很可能不是我们理想的(通常情况下,我们的脚本之间有依赖关系,这就牵涉到如何写脚本逻辑的问题,此不多做讨论),一种方案如果在脚本文件中提前按case名称编写,如test_1, test_2, test_3,这无疑也是痛苦的,一旦我们需要新增和删除一个脚本时,维护case名称会费时费力。基于这些设计痛点,本人设计了一套解决方案,可以让脚本按照数据驱动的原理,顺序添加case名称加载到测试套件中,达到理想化的顺序执行问题。设计思路如下:
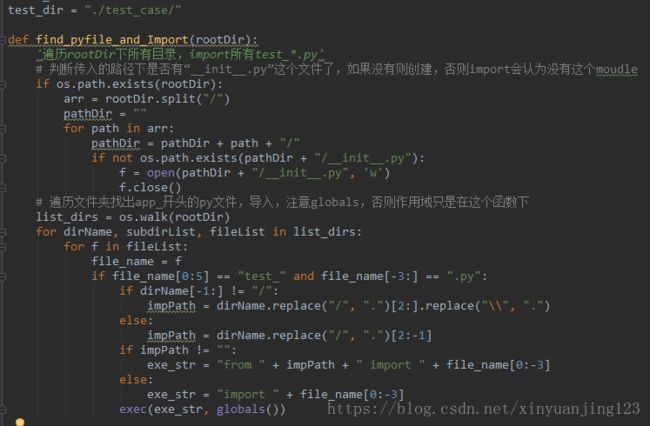
一,动态导入test_case目录及其所有子目录下的所有以test_开头的.py文件(测试脚本文件也需要这样维护),代码:
二,把需要执行的case文件的类以及其需要执行的case维护在excel中(也可以维护在其它类型文件中,怎么维护就怎么解析,目的是排序),附excel数据及解析方式:

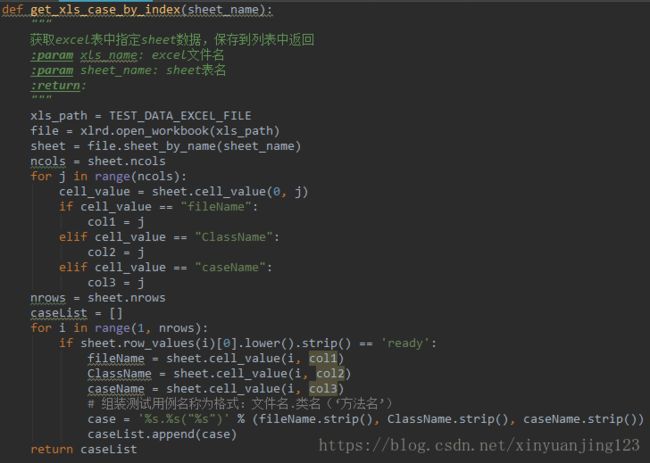
说明:excel中标记为ready的才会添加到caseList中,这样不需要执行的case只需要改变isReady的值即可,返回值是一个按excel顺序排列并按格式 fileName.ClassName("caseName")保存的字符串List, 因为addTest方法就是按这个格式去匹配的
三,前面两步完成以后,只需要把caseList中的每一项[字符串]变成可以被程序识别的类,然后顺序的添加到测试套件中,即可完成测试套件的组装,这里需要用到了一个【eval】方法(不懂自行百度),附执行逻辑如下:
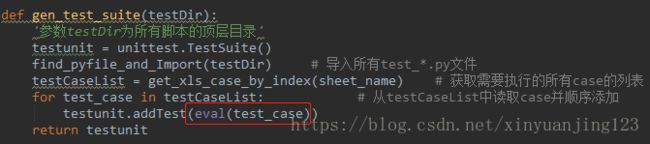
四,把步骤三返回的suite执行一个run方法即可,开头有介绍,不再另附代码
结论:如此,完美的解决了脚本的执行顺序问题,应用到自己的框架中,也会起到很好的效果。我想这也是开源自动化绕不开的难题,开发语言设计就是要先导入后识别,此方案的核心也是解决动态导入的问题