从零开始打造一个新闻订阅APP之爬虫篇(二、实现一个简单的爬虫系统)
前景提要:如何开发一个新闻订阅APP之爬虫篇(一、背景介绍&需求分析)
做一个特定的爬虫系统,首先考虑它要做什么?
从互联网上抓取指定的N个站点信息,解析提取需要的内容,按照特定的结构存储;
系统结构图如下:

下面是主要的代码结构;
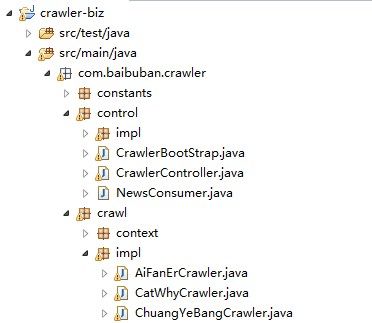
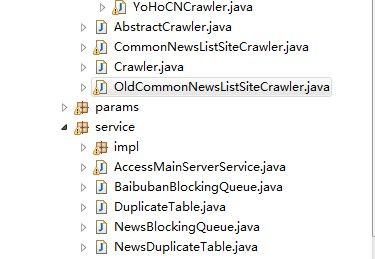
首先,定义一个CrawlerBootStrap类,作为整个系统的主入口。
public void init(){
crawlerList = new ArrayList () ;
for( String name : crawlerNameList ){
Crawler c = (Crawler ) SpringUtil. getObject( name) ;
if( c. init())
crawlerList .add (c );
}
start() ;
}
//爬虫线程池,存储多个爬虫,控制同一时间正在运行爬虫个数
public void start(){
//爬虫池
int corePoolSize = 20 ;
int maximumPoolSize = 1000 ;
long keepAliveTime = 100000L ;
BlockingQueue runnableTaskQueue = new PriorityBlockingQueue ( 20) ;
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor (corePoolSize ,
maximumPoolSize , keepAliveTime, TimeUnit .MILLISECONDS , runnableTaskQueue );
logger. info( "爬虫池启动" );
for( Crawler crawler : crawlerList ){
threadPoolExecutor .execute (crawler );
}
//入库线程
logger. info( "入库线程启动" );
Thread t = new Thread (newsConsumer );
t. start() ;
} 代码解释:
1、由于无法预估每一个待抓取的网站结构和信息更新方式是不是一成不变的,因此,为每一个站点生成一个具体的实现类;
2、这里采用了生产者-消费者模式,由阻塞队列(BlockingQueue)来实现。每一个抓取线程都是生产者,消费者则只有一个入库线程;
工作流程如下:
- 循环从初始化列表中获取待抓取类,实例化,并添加到抓取列表;
- 初始化线程池,由线程池来管理每一个抓取线程(一个线程对应一个站点抓取实例);
- 启动入口线程;
对于那些几乎都是同一类模式(列表+正文,排序方式按照更新时间倒序排列)的站点,可以抽象出一个抽象类实现共性的抓取逻辑,而每一个子类只实现一些细节点:
每一个Crawler都是一个线程,
下面介绍CommonNewsListSiteCrawler的实现逻辑
public void run() {
try {
crawl() ;
} catch (Exception e ) {
logger. error( "crawl error" , e) ;
}
}
protected void crawl(){
boolean first = true ;
while( true ){
try{
if( first){
index = 30;
first = false ;
} else{
index = 5;
}
level = 0;
duplicateNum = 0 ;
NewsResult > newsRes = NewsResult . getSuccessInstance() ;
newsRes. setNextUrl( String .format (crawlUrl ,index ));
do{
newsRes = parseHtml( newsRes. getNextUrl()) ;
if( newsRes. isSuccess()){
int num = addToNewsQueue (newsRes );
Jedis jedis = null;
try{
jedis = jedisPool. getResource ();
jedis. incrBy( RedisConstant .CRAWLER_NAMESPACE + namespace + "crawlTotalNum" , num) ;
jedis. incrBy( RedisConstant .CRAWLER_NAMESPACE + namespace + "todayCrawlTotalNum" , num) ;
jedis. set( RedisConstant .CRAWLER_NAMESPACE + namespace + "currentCrawlUrl" , currentCrawlUrl) ;
} catch( Exception e){
logger. error( "Jedis error" , e) ;
} finally{
jedisPool. returnResource (jedis );
}
}
else {
logger. error( "解析抓取的url页面失败 :" + newsRes. getMessage()) ;
}
generateNextUrl (newsRes );
} while( !newsRes .isEndCrawlFlag () && index > 0) ;
// }while(!newsRes.isEndCrawlFlag());
} catch( Exception e){
logger. error( "failed!" ,e );
intervalTime = 60 *60 *1000 ;
Jedis jedis = null;
try{
jedis = jedisPool. getResource ();
jedis. set( RedisConstant .CRAWLER_NAMESPACE + namespace + "state" , String .valueOf (2 ));
} catch( Exception e1){
logger. error( "Jedis error" , e1) ;
} finally{
jedisPool. returnResource (jedis );
}
}
try {
state = StateEnum .Sleeping ;
Thread .sleep (intervalTime );
} catch ( InterruptedException e) {
e. printStackTrace ();
}
}
}
代码解释:
crawl方法是这一类爬虫的核心代码,每隔一段指定时间,它会抓取一次,考虑更新时间的问题,爬虫是从后往前抓取,即先抓取比较早的数据,首次抓取和第二次抓取设定不同的抓取深度即可(PS:采用这种简单粗暴的方式,能够满足我的实际需求,关注的是较新的内容,并且允许可能存在的丢失问题)
整个步骤如下:
- 抓取当前列表页;
- 分析页面结构,用Jsoup解析出待抓取信息列表,循环处理列表每一条信息;
2.1、读取当前信息url地址,根据去重表判断是否已抓取过,如果没有,继续执行下一步;否则,处理下一条记录;
2.2、解析获取它的标题,并通过它的链接抓取正文信息,并解析其中的图片地址,调用图片服务器接口下载、存储该图片,并返回图片url;
2.3、将解析到的内容包装成一个写入对象,加入阻塞队列中;
2.4、循环2.1 - 2.3,直到列表末尾; - 判断是否满足结束循环条件,是,则结束本次抓取过程,让线程进入睡眠状态;否则,生成下一条抓取记录;
上述代码逻辑很简单,不过它能够满足当前的需求。同时,由于开销小,重复访问站点频次低,几乎不会被目标站点屏蔽(一直运行,目前尚未被任何一个站点屏蔽),并且能够保证更新内容在数分钟内同步抓取。结构简单使得代码维护起来非常轻松;
在实际应用中还会遇到一些小问题,也必须要妥善解决,例如:
1、如果某个站点的数据因为网站结构,程序bug等等导致数据失效,你要能够及时的修复;
2、由于目标站点可能会出现各种网络异常,结构更改等等,因此,需要一个实时监控页面,查看各个爬虫的实时数据是否正常(这里可以有很多优化的地方,不过由于太耗时间,现在只是把一些数据展现出来);
总结:
在实际的项目中,初期,根据业务需要,尽可能考虑写一个满足当前业务需要的系统。不要追求各种高性能;
当然,我说的简单,以满足当前需求为前提,但是一些良好的工程习惯,如面向接口编程,设计类或者模块考虑“高内聚,低耦合”原则,以及代码的可扩展性,可读性等等都是需要你考虑的,这既是对项目负责,也可以让自己养成一个良好编程习惯。
用代码中的去重表实现来举例:
我在项目中将去重表作为一个类实现,因为去重表看似简单,但根据业务需求还是有很多不同的实现方式;如果你抓取的内容不多,那简单的一个hash表就满足你的要求了;为了避免程序重启或崩溃导致hash表数据丢失,你可能会用redis或其它nosql来实现;如果到后来你发现抓取的内容非常多,内存空间已经不够用了,可以更进一步,使用bloomfilter来实现,它可以大大减少内存开销,代价是存在小概率的误判,并且实现一个稳定可用的bloomfilter需要花费一定的时间成本;