分布式列簇式存储系统HBase
分布式列簇式存储系统HBase
HBase是一个基于HDFS构建的分布式数据库系统,具有良好的扩展性、容错性以及易用的API。核心思想是将表中数据按照rowkey排序后,切分成若干region,并存储到多个节点上。HBase采用了经典的主从软件架构,其中主服务被称为HMaster,负责管理从节点、数据负载均衡及容错等,Hmaster是无状态的,所有元信息保存在ZooKeeper中,从服务被称为RegionServer,负责Region的读写,HMaster和RegionServer之间通过ZooKeeper进行服务协调。HBase提供了丰富的访问方式,用户可以通过Hbase shell、Hbase API、数据收集组件、计算引擎等存取HBase上的文件。
一、HBase逻辑数据模型
逻辑数据模型是用户从数据库所看到的模型,直接与HBase数据建模相关。
类似于数据库中的database和table逻辑概念,HBase称为namespace和table,一个namespace中包含一组table,HBase内置了两个默认的namespace。
- hbase:系统内建表,包括namespace和meta表
- default:用户建表时未指定namespace的表都创建在此。
HBase表由一系列行构成,每行数据有一个rowkey,以及若干column family构成,每个column family可包含无限列。
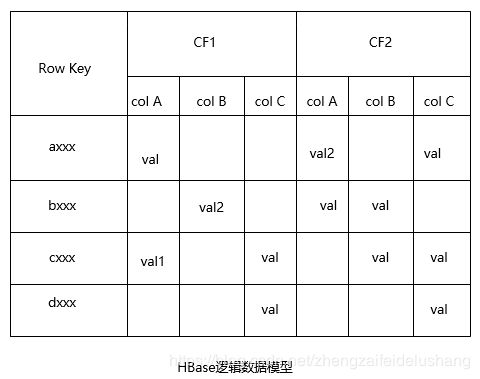
- rowkey:HBase表中的数据是以rowkey作为标识的,rowkey类似于关系型数据库中的主键,每行数据有一个rowkey,唯一标识该行,是定位该行数据的索引。同一张表内,rowkey是全局有序的。rowkey是没有数据类型的,以字节数组(byte[])形式保存。
- column family:HBase表中数据是按照column family组织的,每行数据拥有相同的column family。column family属于schema的一部分,定义表时必须指定好,但每个column family可包含无数个动态列。
column family是访问控制的基本单位,同一个column family中的数据在物理上会存储在一个文件中。column family名称的类型是字符串,由一系列符合Linux路径名称规则的字符构成。 - column qualifier:HBase每列数据可通过family:qualifier唯一标识,qualifier不属于schema的一部分,可以动态指定,且每行数据可以有不同的qualifier。column qualifier也是没有数据类型的,以字节数组(byte[])形式存储。
- cell:通过rowkey,column family和column qualifier可唯一定位一个cell,cell内部保存了多个版本的数组,默认情况下每个数值的版本号是写入时间戳。cell内的数值也没有数据类型的,以数组形式保存。
- timestamp:cell内部数据是多版本的,默认将时间戳作为版本号,用户可根据自己的业务需求设置版本号(数据类型为long)。每个column family保留最大版本数可单独配置,默认是3,读数据时未指定版本号,HBase只会返回最新版本的数值;如果一个cell内数据数目超过最大版本数,则旧的版本将自动被剔除。
从另外一个角度理解HBase的逻辑数据模型:将HBase表看成一个有序多维映射表。

HBase也可以看作一个key/value存储系统,rowkey是key,其他部分是value,也可以将[row key,column family ,column qualifier,timestamp]看做key,Cell中的值对应value,举例如下:
axx,CF1,col A,timestamp1:val
二、物理数据存储
HBase是列式存储引擎,以column family为单位存储数据,每个column family内部数据是以key value格式保存的,key value组成如下:
[row key,column family,column qualifier,timestamp] => value
数据在存储介质中按照下图所示的形式保存:
从保存形式上可以看出,每行数据中不同版本的cell value会重复保存rowkey,column family和column qualifier,因此为了节省存储空间,这几个字段值在保证业务易理解的前提下尽可能短。
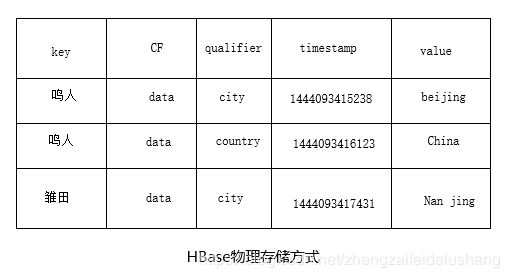
在HBase中,同一表中的数据是按照rowkey升序排列的,同一行中的不同列是按照column qualifier升序排列的,同一cell中的数值是按照版本号(时间戳)降序排列的。HBase表从逻辑视图到物理视图的映射。

HBase是列簇式存储引擎,即同一列簇中的数据会单独存储,但列簇内数据是行式存储的。
三、HBase基本架构
为了将数据表分布到进群中以提供并行读写服务,HBase按照rowkey将数据划分成多个固定大小的有序分区,每个分区被称为一个"region",这些region会被均衡地存放在不同节点上。HBase是构建在HDFS之上的,所有的region均会以文件的形式保存到HDFS上,以保证这些数据的高可靠存储。
HBase采用了经典的master/slave架构,master与slave不直接互连,而是通过引入ZooKeeper让两类服务解耦,使得HBase master变得完全无状态,进而避免了master宕机导致整个集群不可用。

1.HMaster
HMaster可以存在多个,主HMaster由ZooKeeper动态选举产生,当主HMaster出现故障后,系统可由ZooKeeper动态选举出的新HMaster接管。HMaster本身是无状态的(所有状态信息均保存至ZooKeeper中),主HMaster挂掉后,不会影响正常的读写服务。
HMaster主要有以下职责:
- 协调RegionServer:包括为RegionServer分配region,均衡各RegionServer的负载,发现失效的RegionServer并重新分配其上的region。
- 元信息管理:为用户提供table的增删改查操作。
Client读写操作过程是不需要与HMaster进行交互的,而是直接与RegionServer通信来完成的。
2.RegionServer
RegionServer负责单个Region的存储和管理(比如Region切片),并与Client交互处理读写请求。
3.ZooKeeper
ZooKeeper内部存储着有关HBase的重要元信息和状态信息,担任着Master与RegionServer之间的服务协调角色,具体职责如下:
- 保证集群只有一个master。
- 存储所有Region的寻址入口。
- 实时监控Region Server的上线和下线信息,并实时通知给Master。
- 存储HBase的schema和table元数据。
4.Client
Client提供HBase访问接口,与RegionServer交互读写数据,并维护cache加快对HBase的访问速度。
四、HBase内部原理
HBase是构建在HDFS之上的,利用HDFS可靠地存储数据文件,其内部则包含Region定位、读写流程管理和文件管理等实现。
1.Region定位
HBase支持put、get、delete、scan等基础操作,所有这些操作的基础是region定位。给定一个rowkey或rowkey区间,获取rowkey所在的RegionServer地址如下所示:

1)客户端与ZooKeeper交互,查找hbase:meta系统表所在的RegionServer,hbase:meta表维护了每个用户表中rowkey区间与Region存放位置的映射关系,具体如下:
rowkey:table name,start key,region id
value:RegionServer对象(保存了RegionServer位置信息等)
2)客户端与hbase:meta系统表所在RegionServer交互,获取rowkey所在的RegionServer.
3) 客户端与rowkey所在的RegionServer交互,执行该rowkey相关操作。
注意:客户端首次执行读写操作时才需要定位hbase:meta表的位置,之后会将其缓存到本地,除非因region移动导致缓存失效,客户端才会重新读取hbase:meta表位置,并更新缓存。
2.RegionServer内部关键组件
RegionServer内部关键组件如下图所示:
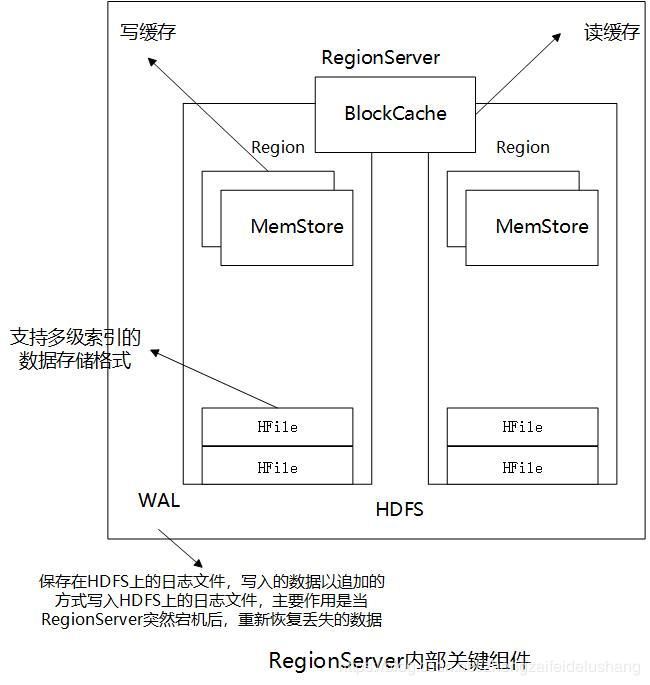
- BlockCache:读缓存,负责缓存频繁读取的数据,采用了LRU置换策略。
- MemStore:写缓存,负责暂时缓存未写入磁盘的数据,并在写入磁盘前对数据排序。每个region内的每个column family拥有一个MemStore。
- HFile:一种支持多级索引的数据存储格式,用于保存HBase表中实际的数据。所有HFile均保存在HDFS中。
- WAL:即Write Ahead Log,保存在HDFS上的日志文件,用于保存那些未持久化到HDFS中的HBase数据,以便RegionServer宕机后恢复这些数据。
3.RegionServer读写操作
HBase中最重要的两个操作是写操作和读操作。

(1)写流程
RegionServer将所有收到的写请求暂时写入内存,之后再顺序刷新到磁盘上,进而将随机写转化未顺序写以提升性能。
具体流程如下:
- RegionServer收到写请求后,将写入的数据以追加的方式写入HDFS上的日志文件,该日志被称为"Write Ahead Log "(WAL)。WAL主要作用是当RegionServer突然宕机后重新恢复丢失的数据。
- RegionServer将数据写入内存数据结构MemStore中,之后通知客户端数据写入成功。
当MemStore所占内存达到一定阙值后,RegionServer会将数据顺序刷新到HDFS中,保存成HFile(一种带多级索引的文件格式)格式的文件。
(2)读流程
由于写流程可能使得数据位于内存中或磁盘上,因此读取数据时,需要从多个数据存放位置中寻找数据,包括读缓存BlockCache、写缓存MemStore,以及磁盘上的HFile文件(可能有多个),并将读到的数据合并在一起返回给用户。
具体流程如下:
- 扫描其查找读缓存BlockCache,内部缓存了最近读取过的数据。
- 扫描器查找写缓存MemCache,内部缓存了最近写入的数据。
- 如果在BlockCache和MemCache中未找到目标数据,HBase将读取HFile中的数据,以获取需要的数据。
4.MemStore与HFile组织结构
MemStore负责将最近写入的数据缓存到内存中,是一个有序Key/Value内存存储格式,每个colum family拥有一个MemStore。

MemStore中的数据量达到一定阙值后,会被刷新到HDFS文件中,保存成HFile格式。HFile是Google SSTable(Sorted String Table,Google BigTable中用到的存储格式)的开源实现,是一种有序Key/Value磁盘存储格式,带有多级索引,以方便定位数据,HFile中的多级索引类似于B+树。
五、HBase访问方式
HBase提供了多种访问方式,包括HBase shell、HBase API、数据收集组件(Sqoop等)、上层计算框架等。
1.HBase shell
可以通过"$HBASE_HOME/bin/hbase shell"命令进入交互式命令行。
bin/hbase shell
1)DDL:作用在HBase表(元信息)上的命令,主要包括如下命令:
- create:创建一张HBase表,语法为:
create 'table name','column family'
create 'employee','personal','office'
- list:列出HBase中所有表。
- disable:让一张HBase表下线
- drop:删除一张HBase表
注意:创建HBase表需要指定所包含的column family,无需指定具体的列。
2) DML:作用在数据上的命令,主要包括如下命令。
- put:往HBase表中的特定行写入一个cell value。语法为:
put 'table name','rowkey','column family:column qualifier', ‘value'
- get:获取HBase表中一个cell或一行的值,语法为:
get 'table naem','rowkey','column family:column qualifier','timestamp'
- delete:删除一个cell value,语法为:
delete 'table name','rowkey','column family:column qualifier','timestamp'
- deleteall:删除一行中所有cell value,语法为:
delete 'table name','rowkey'
- scan:给定一个初始rowkey和结束rowkey,扫描并返回该区间内的数据,语法为:
scan 'table name'[,{filter1,filter2,...}]
例如:
scan 'hbase:meta',{COLUMNS => 'info:regioninfo',LIMIT => 10}
- count:返回HBase表中总的记录条数,语法为:
count 'table name'
实例:往创建好的employee表中插入两个员工信息
创建表
create 'employee','personal','office'
将下面shell命令写入文本文件add_employee.txt中:
put 'employee','00001','personal:name','鸣人'
put 'employee','00001','personal:gender','man'
put 'employee','00001','office:phone','12345678901'
put 'employee','00001','office:salary','88888'
put 'employee','00002','personal:name','犬夜叉'
put 'employee','00002','personal:gender','man'
put 'employee','00002','personal:address','beijing'
put 'employee','00002','office:salary','99999'
以非交互模式执行add_employee.txt中所有命令:
$HBASE_HOME/bin/hbase shell ./add_employee.txt
使用scan命令查看表中的数据:
scan 'employee'
2.计算引擎
HBase提供了TableInputFormat和TableOutputFormat两个组件供各类计算引擎并行读取或写入HBase中的数据,TableInputFormat以HBase Region为单位划分数据,每个Region会被映射成一个InputSplit,可被一个任务处理;TableOutputFormat可将数据插入到HBase中。