mysql索引底层结构分析
什么是索引,索引说白了就是一种提高查询效率的数据结构,mysql底层是用B+Tree来实现的
分析B+Tree之前,我们先来看下其他的几种数据结构之间的区别以及mysql为什么底层是选择用B+Tree来实现索引的
这边网上看到一篇介绍数据结构的,可以参考
https://blog.csdn.net/qq_34436819/article/details/105731324
常见的几种索引数据结构
1.二叉树
2.红黑树
3.hash表
4.B-Tree
这边介绍一个模拟数据结构很给力的网站,大家可以去这网站上模拟一下这些数据结构是怎么存放数据的
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
1.我们首先来看下二叉树:
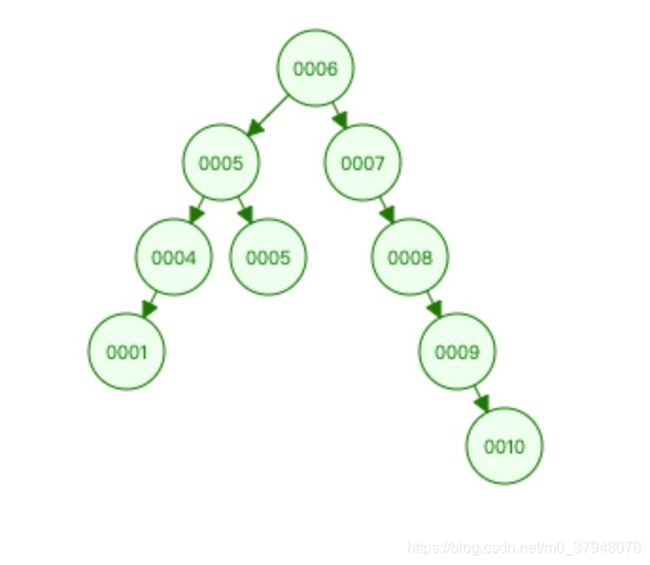
这是一个典型的二叉树的数据结构,每个结点都只有2个字节点,我们可以看到,当数据不断的增加的时候,树的高度就会不断增加,他查找的复杂度就是树的高度,每次查询都会与磁盘做一次I/O交互,消耗比较大。
2.红黑树:
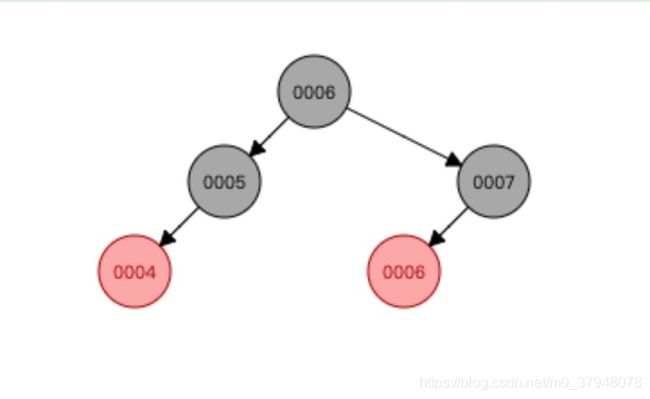

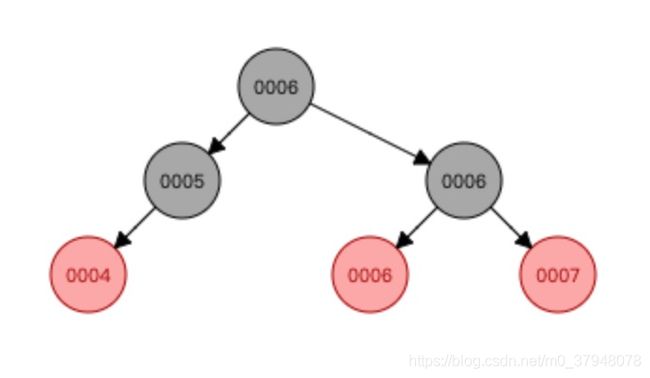
红黑树不断添加数据的时候,树的结点会发生一个自旋,关于红黑树的数据结构比较复杂,这里先不做介绍,之后可能会更新新的博客做介绍,但是能看到每个结点也只有2个字节点,树的高度也会随着数据的增加不断的增加。
3.hash表
hash表是一种key-value的数据结构,它是将 key 通过一个哈希函数计算出一个数字,然后以该数字作为数组的下标,然后将 value 存放到对应下标的数组中。hash表可能出现的问题
1.对于不同的 key,在经过哈希函数计算后,可能出现相同的值,就有可能出现哈希碰撞,这时候就意味着同一个数组下标处要存放两个元素了,所以这个时候将数组中的元素变为一个链表,通过链表将这两个元素串联起来
2.hash表只适合等值查询,如果遇到范围查询等,效率就会很低,不符合实际工作场景
4.B-Tree
B-Tree 的特点是无论叶子结点和非叶子结点,它都存有索引值和数据;B+Tree 的特点是只有叶子结点才会存放索引值和数据,非叶子结点只会存放索引值本身。因此对于非叶子结点,一个结点中,B+Tree 存放的索引值数量会远远大于 B-Tree(因为一个结点的空间是有限的,B-Tree 要存放索引+数据,而 B+Tree 只需要存放索引),这样就导致了每个结点中,B+Tree 能向下分出更多的叉,子结点数更多。
那么在要存储同样大小的数据文件的场景下,用 B+Tree 存储,最终树的高度会远远小于用 B-Tree 存储的高度,所以使用 B+Tree 作为 MySQL 索引的数据结构,将来在读取数据时,发生的磁盘 IO 次数会更少,性能更优,因此最终 MySQL 索引的数据结构使用的是 B+Tree。
关于B-Tree和B+Tree可以参考以下文档
https://mp.weixin.qq.com/s/z_TNLqqJVwYKgb2kBadTwg
https://mp.weixin.qq.com/s/yLCqkrf1rvp6zJA6S-8sTQ
我们主要是分析mysql的InnoDB存储引擎
我们来看下InnoDB的主键索引,普通索引和联合索引的底层数据结构(图是从某个大神那边copy过来的,自己画有点麻烦)
主键索引

普通索引

联合索引

我们来看几个问题
为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?
为甚InnoDB表建议要有自增的主键,尽量建主键,建整形自增的?其实很简单,设计如此,mysql设计的就是innoDB把你的数据和主键索引用B+Tree来组织的,没有主键他的数据就没有一个结构来存储。
建innoDB表的时候没有建主键,表也能建成功,为什么?
不建主键不代表没有主键,没有建主键innodb会帮你选一个字段,一个可以标识唯一的字段,选为默认字段,如果这个字段唯一的话,不重复,可以建唯一索引的话,就会作为类似于唯一索引,用这个字段来作为唯一索引来维护整个表的数据。如果没有,mysql会生成一个唯一的列,类似于rowid,只不过你看不到,他会用生成的这个唯一列,维护B+Tree的结构,查数据的时候还是用B+Tree的结构去查找。
为什么推荐整形呢?
我们想象一下查找过程,是把节点load到内存然后在内存里去比较大小,也就是在查找的过程中要不断的去进行数据的比对。假设UUID,既不自增也不是整形。问一下,是整形的1<2比较的效率高还是字符串的“abc”和“abe”比较的效率高呢?显然是前者,因为字符串的比较是转换成ASCII码一位一位的比,如果最后一位不一样,比到最后才比较出大小,就比整形比较慢多了,存储空间来说,整形更小。索引越节约资源越好。
为什么是自增的呢?
我们可以看一下B-Tree的叶子节点之间是没有指针的,B+Tree优化后增加了叶子节点之间的指针,如果我们遍历数据,从当前节点遍历完之后,就可以根据节点间的指针快速找到下一个节点去遍历。
这边插一个关于联合索引的,联合索引建立需要遵循最左匹配原则,他会先比对第一个字段,比对完第一个字段才会比对第二个字段,最后才会比对第三个字段,举个例子:
有这么一条sql,a,b,c三个字段建立了一个联合索引
select * from table where a=xxx and b=xxx and c=xxx
那么执行会跑3个索引,但是如果变成下面这条查询语句的话就只会跑前面2个索引,而不会跑c索引了
select * from table where a=xxx and b>xxx and c=xxx
个人大致理解就是这样,如果有写的不对的,欢迎一起讨论交流,谢谢!