centos8+java14+hadoop-3.3.0搭建hadoop集群(全网最新)
最近在学hadoop集群的搭建,网上常见的教程是基于centos7.5,java8,和hadoop2搭建的,由于笔者比较喜欢新技术,这里就作死使用最新的环境进行搭建,希望大家能提出意见一起进步。
基础配置:3台安装完环境的centos8虚拟服务器。包括java14,mysql8.0,hadoop-3.3.0。基础环境的搭建过于简单,笔者用的是官方的压缩包,这里不再赘述(但是要注意$PATH环境的配置)
笔者所用的包:
drwxr-xr-x. 14 1001 1001 266 8月 4 08:44 hadoop-3.3.0
-rw-r--r--. 1 root root 500749234 8月 3 19:22 hadoop-3.3.0.tar.gz
-rw-r--r--. 1 root root 173071148 8月 3 19:28 jdk-14.0.2_linux-x64_bin.rpm
drwxr-xr-x. 2 root root 4096 7月 26 15:49 mysql
-rw-r--r--. 1 root root 756193280 7月 26 15:47 mysql-8.0.21-1.el8.x86_64.rpm-bundle.tar
PATH环境:
#java envirnment
export JAVA_HOME=/usr/java/jdk-14.0.2
export PATH=.:$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#HADOOP_HOME
export HADOOP_HOME=/opt/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
测试hadoop用的是Apache官网的测试用例:

这时候我们有3台在线服务器,笔者这里取名hadoop01,hadoop02,hadoop03。
![]()
我们需要设置一下主机的映射(笔者先在一台服务器上配置了环境然后进行克隆,如果克隆之后进行设置,则需要再另外两台机器也进行映射):
[root@hadoop01 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.150.4 hadoop01
192.168.150.5 hadoop02
192.168.150.6 hadoop03
192.168.150.7 hadoop04
192.168.150.8 hadoop05
192.168.150.9 hadoop06
用对应的映射对虚拟机的网卡进行设置,以便我们下一步对三台虚拟机之间进行免密登陆准备条件,这里还需要在三台服务器都关闭防火墙防止出现意外。
我们随便找一台服务器在控制台输入:
ssh-keygen -t rsa
连续敲3个回车,会生成公钥和秘钥,我当时的公钥是:
SHA256:5lYUudNbCL8foGo+sXlSLJzS00jbq8rEzxTAHaFIxB4
进入下面的目录查看是否生成如下文件:
[root@hadoop02 ~]# cd /root/.ssh/
[root@hadoop02 .ssh]# ll
总用量 16
-rw-------. 1 root root 1701 8月 4 01:36 authorized_keys
-rw-------. 1 root root 2602 8月 4 01:00 id_rsa
-rw-r--r--. 1 root root 567 8月 4 01:00 id_rsa.pub
-rw-r--r--. 1 root root 723 8月 4 02:14 known_hosts
然后在这台机器上将上面的公钥拷贝到另外两台机器:
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03
并在当前机器登陆其他两台服务器,登陆过程中可能需要输入之前的公钥,可以提前复制好:
ssh hadoop01
ssh hadoop02
ssh hadoop03
这时候我们已经可以在这台服务器免密登陆其他两台服务器,接下来我们要在其他两台服务器上进行和上面相同的操作,生成秘钥并分发。一般来说秘钥是相同的在上面已经生成。照着葫芦画瓢即可。
免密登陆后我们就可以进行集群的搭建了。我们有三台服务器,这三台服务器每一台都有着自己的角色和功能,因为每一种角色都很耗费内存,所以我们不能将他们都放到一个节点上。

hadoop有三大架构:
HDFS(分为NameNode和DataNode)
YARN(分为resourcemanager和nodemanager)
MapReduce(分为map和reduce)
在目录
[root@hadoop02 hadoop]# pwd
/opt/hadoop-3.3.0/etc/hadoop
里,我们有四个配置文件,分别对上面的三大框架逐一进行配置:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml
我们随机选择一个服务器的hadoop,对这4个文件进行配置:
core-site.xml
核心设置
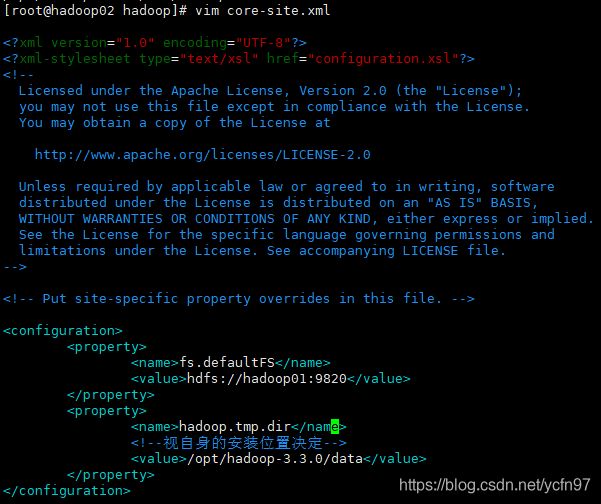
fs.defaultFS
hdfs://hadoop01:9820
hadoop.tmp.dir
/opt/hadoop-3.3.0/data
这里配置的就是namenode目录节点的ip和端口,我们设置hadoop01为NameNode节点,每一台服务器都是目录的DataNode负责存储数据,下面我们还要设置一个secondarynamenode节点,每隔一段时间对NameNode目录进行备份。
hdfs-site.xml
hdfs存储系统框架设置

dfs.namenode.http-address
hadoop01:9870
dfs.namenode.secondary.http-address
hadoop03:9868
yarn-site.xml
yarn资源管理框架设置
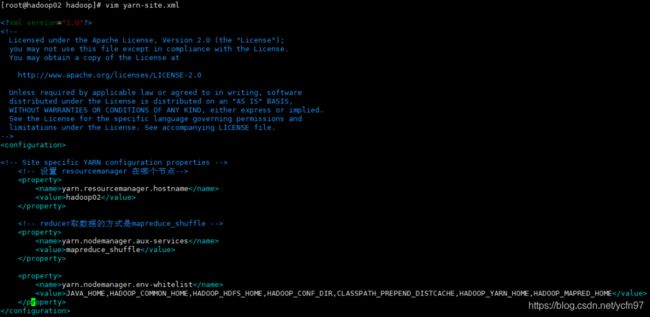
yarn.resourcemanager.hostname
hadoop02
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
这里设置yarn的resourcemanager节点,我们设置为第二台服务器hadoop02负责资源管理,主要负责处理用户请求,监控node节点,以及资源的分配调度,每一台服务器都是资源管理的nodemanager。
mapred-site.xml
MapReduce分布式计算框架设置
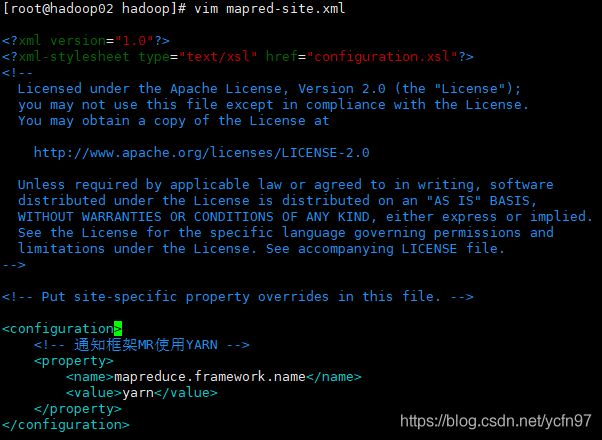
mapreduce.framework.name
yarn
最后,还要配置一下
vim /opt/hadoop-3.3.0/etc/hadoop/workers

因为我们事先做过无秘钥通信,这时候就可以把已经配置好的这台机器上的文件同步到另外两台虚拟机:
rsync -av /opt/hadoop-3.3.0/* root@hadoop01:/opt/hadoop-3.3.0/
rsync -av /opt/hadoop-3.3.0/* root@hadoop03:/opt/hadoop-3.3.0/
好了,现在我们可以开始召唤神龙了,下面开始启动集群,第一次启动集群需要在NameNode节点所在的虚拟机进行格式化操作:
hdfs namenode -format
随后:
start-dfs.sh

还需要启动yarn资源管理:
start-yarn.sh
启动成功,成功召唤神龙!
查看NameNode集群情况可以在本机Google输入:
http://192.168.150.4:9870/dfshealth.html#tab-overview

查看yarn资源管理:
http://192.168.150.5:8088/cluster

over,enjoy!
常见报错0
centos8重启网络服务
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
修改hadoop/sbin里面的四个文件夹
1、对于start-dfs.sh和stop-dfs.sh文件,添加下列参数:
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
2、对于start-yarn.sh和stop-yarn.sh文件,添加下列参数:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
这是一个技术和财经都会分享的公众号