Scrapy豆瓣爬虫 爬取用户以及用户关注关系
文章目录
- 明确任务
- 1.新建mysql数据库以及数据表
- 1.1 创建数据库
- 1.2 创建用户信息表users
- 1.3 创建用户关注表user_follows
- 笔记一: mysql中utf8与utf8mb4字符编码
- 笔记二:mysql中的排序规则
- 2.PyCharm搭建Scrapy爬虫项目
- 2.1 创建一个Scrapy工程
- 笔记三:scrapy基本命令
- 创建项目
- 运行项目
- 开始爬虫
- 控制台暂停和终止爬虫
- 笔记四:scrapy工程目录结构解析
- 笔记五:scrapy框架的组成
- 笔记六:scrapy爬取过程理解
- 2.2 实现爬取用户关注列表并用文件存储个人关注的用户的主页地址
- 2.2.1 python模拟登录豆瓣
- 2.2.2 编写database.py
- 2.2.3 爬取用户主页地址并保存到文件中
- 笔记七:两种html标签解析方式(BeautifulSoup、Xpath)的比较
- 笔记八:python中BeautifulSoup的使用
- 示例
- 几种解析器比较
- 笔记九:python中Xpath的使用
- Xpath表达式
- 函数xpath()的返回值
- 笔记十:python中拼接字符串
- 方法一:采用占位符%s
- 方法二:+连接
- 笔记十一:python中的文件的常用操作
- 文件的读写模式含义
- 将字符串按行存入文本
- 从文本中按行读出字符串
- 判断文件夹是否存在
- 判断文件是否存在
- 2.3 实现scrapy框架爬取用户个人主页并存放在mysql数据库中
- 2.3.1 编写items.py
- 2.3.2 编写user_info_spider.py
- 1)Scrapy框架中实现豆瓣登录请求
- 2)按用户主页地址爬取用户信息
- 2.3.3 修改user_info_spider.py
- 笔记十二:python包中类的使用
- 笔记十三:调试方法
- 方法一:print()
- 方法二:logger.info()
- 笔记十四:python中正则表达式的使用
- 2.4 实现保存用户信息到数据库
- 2.4.1 编写pipeline.py文件
- 1)获得用户
- 2)插入用户
- 3)更新用户
- 4)完整代码
- 笔记十五:pymysql对数据库的查插删改
- 建立数据库连接
- 查询
- 插入
- 删除
- 修改
- 2.5 实现保存用户关注关系到数据库
- 2.5.1 编写items.py
- 2.5.2 编写save_user_follow.py
- 2.6 后期优化
- 2.6.1 部分账户被冻结
参考项目: 基于 Python3 的豆瓣电影/豆瓣读书 Scarpy 爬虫,实现封面下载+元数据抓取+评论入库+IP 代理池
明确任务
1.建立user数据表以及user_follow数据表
2.将豆瓣一个用户所关注用户的豆瓣id、头像url爬取到user数据库,并将对应的关注关系存至user_follow数据库
1.新建mysql数据库以及数据表
1.1 创建数据库
CREATE DATABASE db_douban;
1.2 创建用户信息表users
CREATE TABLE users(
id int(10) unsigned NOT NULL AUTO_INCREMENT,
douban_id int(10) unsigned NOT NULL DEFAULT '0',
nickname varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '',
head_thumb varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '',
created_at timestamp NOT NULL DEFAULT '0000-00-00 00:00:00',
update_at timestamp NOT NULL DEFAULT '0000-00-00 00:00:00',
PRIMARY KEY(id)
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
1.3 创建用户关注表user_follows
CREATE TABLE user_follows(
user_id int(10) unsigned NOT NULL,
user_follow_id int(10) unsigned NOT NULL,
FOREIGN KEY(user_id) REFERENCES users(id),
FOREIGN KEY(user_follow_id) REFERENCES users(id),
PRIMARY KEY(user_id,user_follow_id)
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
笔记一: mysql中utf8与utf8mb4字符编码
- utf8mb4比utf8多一个字节用于存放emoji表情编码,仅在mysql 5.5.3 版本以后的才支持。使用时请使用
utf8mb4。 mysql字符集 utf8 和utf8mb4 的区别
笔记二:mysql中的排序规则
- utf8mb4_general_ci 和utf8mb4_unicode_ci均为排序规则。utf8mb4_unicode_ci比较准确,utf8mb4_general_ci速度比较快。通常使用utf8mb4_general_ci的准确性足够。
- 在创建数据库时指定字段的
COLLATE属性可以指定排序规则,告知mysql如何对该列进行排序和比较。MYSQL中的COLLATE是什么?
2.PyCharm搭建Scrapy爬虫项目
2.1 创建一个Scrapy工程
具体步骤
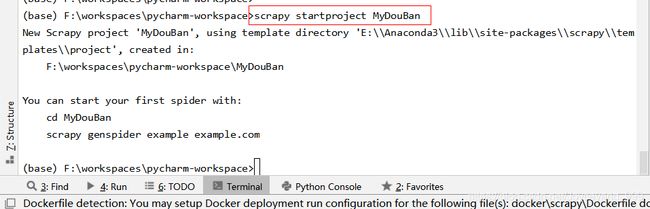
- 在当前工作空间路径输入
scrapy startproject MyDouBan并运行
可以看到该工程已经建立在本地路径之中
- 打开该工程可以看到之前所生成的文件结构
该工程已创建完成。


笔记三:scrapy基本命令
官方文档:Scrapy 1.8 documentation
创建项目
scrapy startproject MyDouBan
运行项目
scrapy runspider test.py
开始爬虫
scrapy crawl book_subject
控制台暂停和终止爬虫
暂停:一次ctrl+c
终止:连续按两次ctrl+c
笔记四:scrapy工程目录结构解析
- spiders文件夹:用于放自己编写的爬虫文件
- items.py:存放自定义实体,用于存储爬取的数据
- middlewares.py:中间件(待理解!)
- pipelines.py:对spiders中爬虫的返回的数据的处理,可以让写入到数据库,也可以让写入到文件
- settings.py:爬虫过程的核心配置文件
- scrapy.cfg:配置文件
笔记五:scrapy框架的组成
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心)- 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址- 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)- 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面- 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。- 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。- 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。- 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
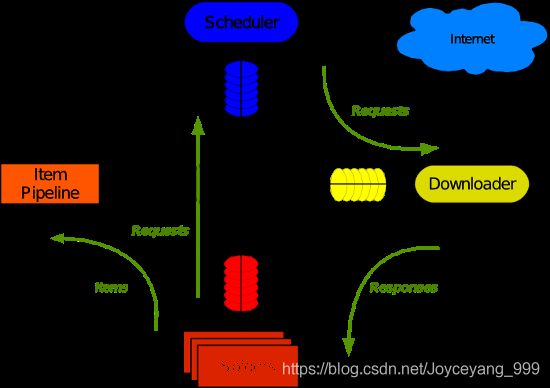
笔记六:scrapy爬取过程理解
- 引擎从调度器中获得一个链接(URL)
- 引擎把该URL封装成一个请求(Request)传给下载器
- 下载器将资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
1) 解析出实体(Item),则交给实体管道进行进一步的处理
2) 解析出的是链接(URL),则把URL交给调度器等待抓取
- 管道将实体信息存储到数据库中
2.2 实现爬取用户关注列表并用文件存储个人关注的用户的主页地址
本来打算访问用户关注列表然后将关注页面中的头像和昵称还有豆瓣id写入users表,然后把关注关系写入user_follows表
通过关注用户关注页面部分用户的个人主页并不包含豆瓣ID,遇见了问题二,由于保存用户信息以及用户关注情况均需要豆瓣ID作为豆瓣身份的唯一标识,也就相当于我们这用户的唯一标识,所以未获得豆瓣ID后续操作无法执行。
解决问题二的时候转变了最开始的思路,采用文件将关注用户的个人主页地址存储起来,然后通过访问个人主页地址获得豆瓣ID以及用户信息
2.2.1 python模拟登录豆瓣
- 问题一:请求用户关注列表需要登录
在第一次访问时需要登录,之后可以根据登录后的cookie访问。由于cookie隔一段时间会清空,因此在cookie失效后仍要重新登录。
- 解决思路
参考:Python登录豆瓣并爬取影评
- 获得豆瓣登录请求的url,然后把用户名和密码作为参数传输,实现模拟登录
- 利用cookie保存会话状态
- 具体步骤
1.查看豆瓣网登录请求信息
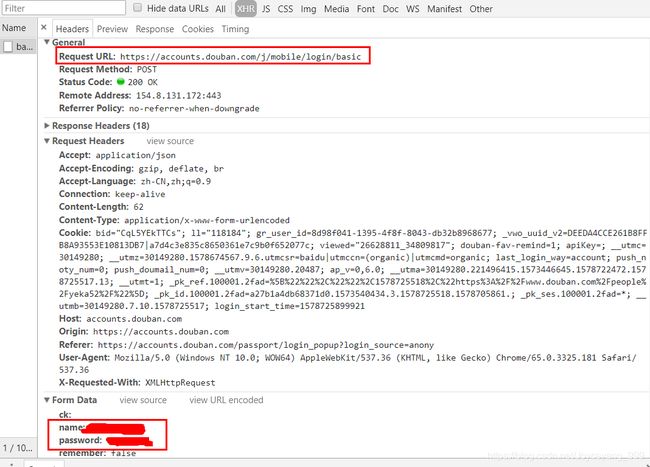
- 通过豆瓣登录界面,发现登录成功,由于页面跳转而捕捉不到请求。故输错密码,然后登录,可以看到登录的请求内容,包括登录请求的URL:
https://accounts.douban.com/j/mobile/login/basic
以及name和password属性
2.利用session提交登录请求保存请求的cookie
- 如果发送了一个错误请求(一个 4XX 客户端错误,或者 5XX 服务器错误响应),可以通过 Response.raise_for_status() 来抛出异常:如果状态码为200,或者302则调用 raise_for_status() 得到的是None
import requests # 生成Session对象,用于保存Cookie session = requests.Session() #登录豆瓣,1登录成功,0登录失败 def login_douban(): # 登录URL login_url = 'https://accounts.douban.com/j/mobile/login/basic' # 请求头 headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36', 'Referer': 'https://accounts.douban.com/passport/login?source=main' } # 传递用户名和密码 data = {'name': '用户名', 'password': '密码', 'remember': 'false'} try: response = session.post(login_url, headers=headers, data=data) response.raise_for_status() #抛出错误请求异常 except: print('登录请求失败') return 0 print(response.text) # 打印请求结果 return 13. 判断是否为登录页面
- 如果未登录,通过session请求豆瓣个人关注用户链接则会转到登录界面;如果登录后长时间未操作,也需要重新登录
- 可以通过BeautifulSoup解析页面判断找class=login-right的标签是否存在,来判断是否为登录界面,如果是登录页面则请求登录执行login_douban()
from bs4 import BeautifulSoup import os if __name__ == '__main__': users = get_users() for user in users: douban_id = user['douban_id'] filepath = '../storage/userFollow/' + '%s' % douban_id + '.txt' print(filepath) if not os.path.exists(filepath): #用户全部关注人链接 url = 'https://www.douban.com/people/%s/contacts/' % user['douban_id'] print(url) headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36'} response = session.get(url=url,headers=headers) #BeautifulSoup解析页面 content = BeautifulSoup(response.text,"html5lib") #获得当前登录状态 IF_LOGIN = content.find('div', class_='login-right') if IF_LOGIN == None: #已登录 print('已登录') else: #未登录(cookie失效或者第一次登录) print('登录') login_douban()4.运行结果
- 第一次运行的时候需要登录,而第二次运行的时候不需要登录

2.2.2 编写database.py
编写database.py 用于连接数据库

import pymysql
MYSQL_DB = 'db_douban' #数据库名称
MYSQL_USER = 'root' #用户名
MYSQL_PASS = '123456' #密码
MYSQL_HOST = 'localhost' #本地数据库
connection = pymysql.connect(host=MYSQL_HOST, user=MYSQL_USER,
password=MYSQL_PASS, db=MYSQL_DB,
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
2.2.3 爬取用户主页地址并保存到文件中
- 问题二:用户主页地址的格式不一致无法直接获得豆瓣id
用户关注列表中很多用户主页的Url并不是直接包含该用户的豆瓣id
一般用户的主页:https://www.douban.com/people/1008662/,其中的数字为用户的豆瓣id
例如刘未鹏大大的主页:https://www.douban.com/people/pongba/
所以不能直接通过主页地址获得用户关注用户的豆瓣id
- 解决思路
直接将用户的主页地址存储下来,然后根据主页地址从用户主页关注此人处获得用户豆瓣id
但是我们还需要存储用户关注的关系,如果仅存用户主页地址无法体现出关系
想法一:用一个以豆瓣id命名的txt文件按行存入用户主页地址。一个文件代表一个用户的关注信息。这样根据数据库里的用户id可以得到该用户所关注用户的主页地址。并根据这些地址主页获得豆瓣id、用户名称、加入时间、用户头像存入user数据表,同时将关注关系写入user_follow关系表(本来打算在类中弄一个user_url全局变量,用于存放当前爬取的地址,但是发现请求和爬取并非一一对应,请求要快于爬取,故这个全局变量只能表示最后请求的url,这样不行),保存完用户数据后再遍历一遍文件,根据文件名在数据库找到用户id,根据文件中的url在数据库中找到对应的被关注者的id,添加关注关系
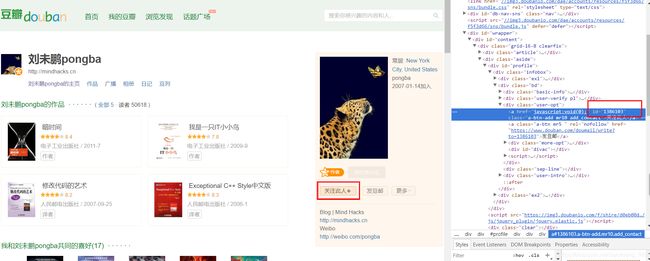
- 具体步骤
1.保存用户主页地址
- 将个人全部关注页面的用户url写入/storage/userFollow/豆瓣id.txt文件中
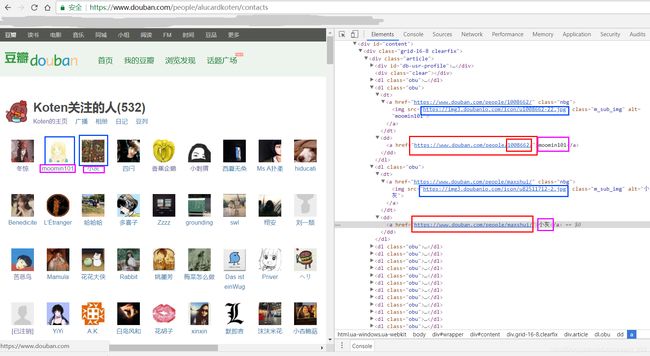
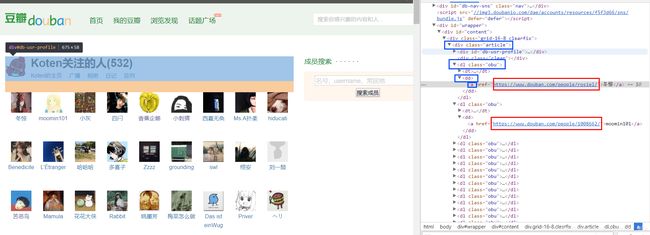
首先要在工程目录下创建对应路径的文件,然后运行代码- 我们要提取的用户关注列表如图所示,由于上述的BeautifulSoup寻找标签仍然不够方便,故将这页面解析部分全部改成了Xpath解析器。通过
xpath('//div[@class="article"]/dl[@class="obu"]/dd/a/@href')获得链接- 事先在users数据表中存储了两个用户的信息,然后将这两个用户的关注用户URL爬取下来
2.编写user_follow.py文件
import os import MyDouBan.database as db import requests from lxml import etree #获得连接数据库的游标 cursor = db.connection.cursor() # 生成Session对象,用于保存Cookie session = requests.Session() #登录豆瓣,1登录成功,0登录失败 def login_douban(): # 登录URL login_url = 'https://accounts.douban.com/j/mobile/login/basic' # 请求头 headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36', 'Referer': 'https://accounts.douban.com/passport/login?source=main' } # 传递用户名和密码 data = {'name': '用户名', 'password': '密码', 'remember': 'false'} try: response = session.post(login_url, headers=headers, data=data) response.raise_for_status() #抛出错误请求异常 except: print('登录失败') return 0 print('登录成功') # 打印请求结果 return 1 #从数据库中获得用户 def get_users(): sql = 'SELECT douban_id from users' cursor.execute(sql) users = cursor.fetchall() return users #向文件中添加用户url def save_url(filepath,user_url_list): #为了方便每个用户关注只保存一次,不考虑关注变动 if not os.path.exists(filepath): file = open(filepath, "w+") for user_url in user_url_list: file.write(str(user_url)+'\n') print(filepath+'已保存完成') else: print(filepath + '已存在') pass if __name__ == '__main__': users = get_users() for user in users: douban_id = user['douban_id'] filepath = '../storage/userFollow/' + '%s' % douban_id + '.txt' print(filepath) if not os.path.exists(filepath): #用户全部关注人链接 url = 'https://www.douban.com/people/%s/contacts/' % user['douban_id'] print(url) headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36'} response = session.get(url=url,headers=headers) #Xpath解析页面 tree = etree.HTML(response.text) # 获得当前登录状态 IF_LOGIN = tree.xpath('//div[@class="login-right"]') if not IF_LOGIN : #已登录 print('已登录') else: #未登录(cookie失效或者第一次登录) print('转到登录') while(login_douban() == 0): login_douban() response = session.get(url=url, headers=headers) tree = etree.HTML(response.text) user_url_list = tree.xpath('//div[@class="article"]/dl[@class="obu"]/dd/a/@href') save_url(filepath,user_url_list) else: print('该用户关注列表已经获得')运行效果
优化
由于存在已注销的账户,这部分账户并没有什么意义,需要删除
- 修改xpath路径
2. 修改save_url中保存的逻辑,多一个已注销用户名的判断
可以看到文件中所保存的url明显变少了


笔记七:两种html标签解析方式(BeautifulSoup、Xpath)的比较
- xpath 要求一定清楚文档层次结构,它通过元素和属性进行导航,可以使用绝对路径或相对路径查找,而beautifulsoup 不必清楚文档结构,可以直接找某些标签,简单粗暴。
- BeautifulSoup解析中find_all()当没有找到时返回None,而Xpath解析中xpath()当没有找到时返回空集合,两者判断不同
- 返回为None判断:
if data == None:- 返回为空集合判断:
if not data:
- 正则表达式也可以对标签进行匹配,但十分麻烦,适合处理字符串而非网页文档,不推荐在此使用
Xpath 的性能优于BeautifulSoup 示例
beautifulsoup和xpath的解析方式
笔记八:python中BeautifulSoup的使用
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。
- 它是一个第三方的Python库,由python语言编写。通过解析文档为用户提供需要抓取的数据。使用者不需要清楚文档结构,可以直接找到标签。但是也存在很多的局限性。
- 寻找标签时会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多。
官方中文文档:Beautiful Soup 4.4.0 文档
示例
#BeautifulSoup解析页面
content = BeautifulSoup(response.text,"html5lib")
#查找标签
IF_LOGIN = content.find('div', class_='login-right')
几种解析器比较
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| python标准库 | BeautifulSoup(markup, “html.parser”) | Python的内置标准库速度适中;文档容错能力强 | Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, “lxml”) | 速度快;文档容错能力强 | 需要安装C语言库 |
| lxml HTML 解析器 | BeautifulSoup(markup, [“lxml”, “xml”]) BeautifulSoup(markup, “xml”) | 速度快;唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, “html5lib”) | 最好的容错性;以浏览器的方式解析文档;生成HTML5格式的文档 | 速度慢 |
笔记九:python中Xpath的使用
使用 lxml 中的 xpath 高效提取文本与标签属性值。lxml局部遍历DOM树,因此性能会好很多。
Xpath表达式
- 路径
- 绝对路径(一个/):从根开始。例如
/html/body/div/ul/li- 相对路径(两个/):从任意位置开始。例如
//div//li
- 规定标签属性
- 标签[@属性名=值]
例如//div[@id="link-report"]//div[@class="intro"]
- 取值
- 取标签中的属性值:标签/@属性名 例如
/div/@class- 取标签中的内容值:标签/text() 例如
/div/a/text()
函数xpath()的返回值
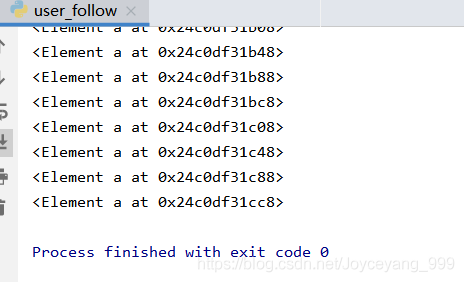
xpath对该文本中的元素定位返回的是一个list列表,遍历后发现一堆看不懂的东西
tree = etree.HTML(response.text) user_url_list = tree.xpath('//div[@class="article"]/dl[@class="obu"]/dd/a') for i in user_url_list: print(i)
- 运行结果
- 用lxml获取网页内容,再用Xpath解析后打印出来的值为
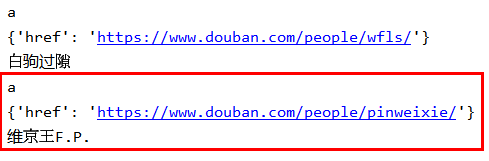
这表示其中的元素是以字典形式存放,故含有键值对from lxml import etree tree = etree.HTML(response.text) user_url_list = tree.xpath('//div[@class="article"]/dl[@class="obu"]/dd/a') for i in range(len(user_url_list)): # user_url_list[i]返回的是一个字典 print(user_url_list[i].tag) print(user_url_list[i].attrib) print(user_url_list[i].text)
- 运行结果
其中tag对应标签,attrib对应标签中的属性(以键值对的形式存放),text对应标签中的内容
笔记十:python中拼接字符串
方法一:采用占位符%s
一个参数
"当前内容:%s" % param1
多个参数
"当前内容:%s,%s" % (param1,param2)
方法二:+连接
"当前内容"+param1+param2
笔记十一:python中的文件的常用操作
文件的读写模式含义
| 模式 | 可做操作 | 若文件不存在 | 是否覆盖 |
|---|---|---|---|
| r | 只读 | 报错 | - |
| r+ | 可读可写 | 报错 | 是 |
| w | 只写 | 创建 | 是 |
| w+ | 可读可写 | 创建 | 是 |
| a | 只写 | 创建 | 否,追加写 |
| a+ | 可读可写 | 创建 | 否,追加写 |
将字符串按行存入文本
filepath = '../storage/userFollow/' + douban_id +'\n'
open(filepath, 'w+').write(douban_user_url)
#另一种写法
file = open(filepath, 'w+')
file.write(douban_user_url)
- 写的时候换行在字符串后面加上’\n’即可
- 此种存储方式读取的时候会连同\n一起读出,读出时需要将后面的\n去掉
从文本中按行读出字符串
file = open(filepath,"r")
for line in file:
print(line) #按行输出字符串
line = line[:-2] #将行后面的'\n'字符对应编码%0A去除
判断文件夹是否存在
if os.path.isdir('data'): #data文件夹已存在
pass
else: #data文件夹不存在
os.mkdir('data') #创建data文件夹
- 由于python不会自己创建文件夹。所以用到文件夹最好自己手动建立,否则就要写代码判断是否存在,不存在建立文件夹
判断文件是否存在
if not os.path.exists(filepath): #如果不存在该用户的关注文件
print('不存在%s文件' % filepath)
else:
print('存在%s文件' % filepath)
- 在写入文件的时候采用w/w+/a/a+当文件不存在时都会自动创建新文件
2.3 实现scrapy框架爬取用户个人主页并存放在mysql数据库中
2.3.1 编写items.py
由于目前我们从豆瓣页面中仅获得用户的豆瓣id、用户昵称和用户头像对应的图片url、,故只要建立如下类即可。
补充:由于在关注关系的判断时需要比较用户主页地址表明用户,故需要再加一个用户关注地址,有的部分可能没有该字段
from scrapy import Item,Field
class User(Item):
id = Field()
head_thumb = Field()
douban_id = Field()
nickname = Field()
created_at = Field()
douban_user_url = Field()
2.3.2 编写user_info_spider.py
1)Scrapy框架中实现豆瓣登录请求
- 问题描述
用户只有登录后才能在关注他人那里看到对方的豆瓣Id,问题一只是在一般的爬虫情况,而我们想通过Scrapy框架进行爬虫,所以有了问题三
- 解决思路
参考:Scrapy模拟登陆豆瓣抓取数据
同问题一,也是通过请求登录url,传递个人的用户名和密码信息,得到response后在request
- 具体步骤
1.scrapy框架中的爬虫类默认从start_requests开始执行,因此初始时先请求登录地址
def start_requests(self): return [Request(url="https://accounts.douban.com/passport/login", meta={"cookiejar": 1}, callback=self.login)]Request函数中的部分参数含义
url参数:请求的url地址meta参数:从request向response传递的参数(为问题二中存储关注关系提供了新思路,可以把请求的用户豆瓣id放在参数里)
在这里meta={'cookiejar': 1}:代表本次请求开启cookiecallback参数:本次访问成功后的回调函数2.根据start_requests中请求的回调转到login函数,执行登录操作。
def login(self,response): # 登录URL login_url = 'https://accounts.douban.com/j/mobile/login/basic' # 传递用户名和密码 data = {'name': '用户名', 'password': '密码', 'remember': 'false'} return [FormRequest(url=login_url, method='POST', meta={"cookiejar":response.meta["cookiejar"]}, formdata=data, dont_filter=True, callback=self.start_user_info)]FormRequest函数中的部分参数含义
- meta参数:这里
meta={"cookiejar":response.meta["cookiejar"]}- formdata参数:表单参数, 这里包括用户名和密码
3.执行完登录后,再次回调到start_user_info方法
这里是我们实际要进行的逻辑
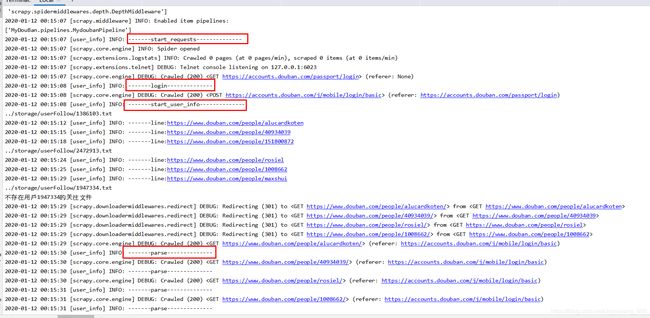
从文件中依次读取用户个人主页url,然后请求,由于meta里传递了之前的cookie信息,所以此次请求是登录状态def start_user_info(self,response): for user in self.users: self.user_id = user['id'] self.filepath = '../storage/userFollow/' + '%s' % user['douban_id'] + '.txt' if not os.path.exists(self.filepath): #如果不存在该用户的关注文件 print('不存在用户%s的关注文件' % user['douban_id']) else: file = open(self.filepath,"r") for line in file: time.sleep(1 + random.randint(0, 5)) line = line[:-2] yield Request(line, callback=self.parse,meta={"cookiejar":True})
- True与1的值相等,所以用哪个都行
4.引擎将封装的request请求交给下载器,下载器进行下载,封装成response交给爬虫爬取,回调parse函数,这就和未实现登录前一样了
5.运行结果
- 代码整合
import random
import string
import time
import os
import re
import MyDouBan.database as db
from scrapy import Spider,Request,FormRequest
from MyDouBan.items import User,UserFollow
cursor = db.connection.cursor()
class UserInfoSpider(Spider):
name="user_info"
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36'
allowed_domains = ["douban.com"]
sql = 'SELECT * from users'
cursor.execute(sql)
users = cursor.fetchall()
num=0
def start_requests(self):
self.logger.info('-------start_requests--------------')
return [Request(url="https://accounts.douban.com/passport/login", meta={"cookiejar": 1}, callback=self.login)]
def login(self,response):
self.logger.info('-------login--------------')
# 登录URL
login_url = 'https://accounts.douban.com/j/mobile/login/basic'
# 传递用户名和密码
data = {'name': '',
'password': '',
'remember': 'false'}
return [FormRequest(url=login_url,
method='POST',
meta={"cookiejar":response.meta["cookiejar"]},
formdata=data,
dont_filter=True,
callback=self.start_user_info)]
def start_user_info(self,response):
self.logger.info('-------start_user_info--------------')
for user in self.users:
self.user_id = user['id']
self.filepath = '../storage/userFollow/' + '%s' % user['douban_id'] + '.txt'
print(self.filepath)
if not os.path.exists(self.filepath): #如果不存在该用户的关注文件
print('不存在用户%s的关注文件' % user['douban_id'])
else:
file = open(self.filepath,"r")
num = 0
for line in file:
num =num+1
time.sleep(1 + random.randint(0, 5))
#self.logger.info('-------linebefore:%s', line)
line = line[:-2]
self.logger.info('-------line:%s', line)
if num == 3:
break
yield Request(line, callback=self.parse,meta={"cookiejar":True})
def parse(self, response):
self.logger.info('-------parse--------------')
- 大坑注意
开始很完美的运行了程序,但是过了一段时间大概是cookie过期了,导致怎么运行都是未登录状态。
后来过了一会,重新运行就好了
2)按用户主页地址爬取用户信息
- 发现用户只有登录后才能在关注他人那里看到对方的豆瓣Id,问题一只是在一般的爬虫情况,而我们想通过Scrapy框架进行爬虫,所以有了问题三
- 解决完问题三后,主要解决根据response回复的内容利用Xpath进行解析,获得页面中所需要的元素,这里根据定位我们需要获得豆瓣id、用户名称、加入时间、用户头像。
- 为了找到哪些页面元素没有获得,将没有获得的页面保存在
storage/errorPages文件夹下,用num加以区分
- 代码
def get_nikename(self,user,response):
regx = '//div[@class="pic"]/a/@title'
data = response.xpath(regx).extract() #解析得到list
if data:
user['nickname'] = data[0]
self.logger.info('1-------nickname:%s', data[0])
else:
regx = '//div[@class="pic"]/a/img/@alt'
data = response.xpath(regx).extract()
if data:
user['nickname'] = data[0]
self.logger.info('2-------nickname:%s', data[0])
else:
self.num = self.num +1
filepath = '../storage/errorPages/nickname_%s.html' % str(self.num)
file = open(filepath,"w+",encoding="utf8")
file.write(response.text)
return user
def get_head_thumb(self,user,response):
regx = '//div[@class="basic-info"]/img/@src'
data = response.xpath(regx).extract()
if data:
user['head_thumb'] = data[0]
self.logger.info('-------head_thumb:%s', data[0])
else:
self.num = self.num + 1
filepath = '../storage/errorPages/head_thumb_%s.html' % str(self.num)
file = open(filepath, "w+", encoding="utf8")
file.write(response.text)
return user
def get_douban_id(self,user,response):
regx = '//div[@class="user-opt"]/a/@id'
data = response.xpath(regx).extract()
if data:
user['douban_id'] = data[0]
self.logger.info('-------douban_id:%s', data[0])
else:
self.num = self.num + 1
filepath = '../storage/errorPages/douban_id_%s.html' % str(self.num)
file = open(filepath, "w+", encoding="utf8")
file.write(response.text)
return user
def get_created_at(self,user,response):
regx = '//div[@class="user-info"]/div[@class="pl"]/text()'
data = response.xpath(regx).extract()
if data:
result = re.search("(\d{4})-(\d{2})-(\d{2})",data[1])
if result != None:
created_at = "%s-%s-%s 00:00:00" % (result.group(1),result.group(2),result.group(3))
user['created_at'] = created_at
self.logger.info('-------created_at:%s', created_at)
return user
self.num = self.num + 1
filepath = '../storage/errorPages/created_at_%s.html' % str(self.num)
file = open(filepath, "w+", encoding="utf8")
file.write(response.text)
def parse(self, response):
self.logger.info('-------parse--------------')
if 35000 > len(response.body):
print(response.body)
print(response.url)
elif 404 == response.status:
print(response.url)
else:
user = User()
self.get_douban_id(user,response)
self.get_nikename(user,response)
self.get_head_thumb(user,response)
self.get_created_at(user,response)
print(user)
return user
- 函数定义中的self参数在使用时是不需要加的。注意定义get_douban_id时有三个参数
def get_douban_id(self,user,response):而在实际使用函数时只需要传递两个参数,self.get_douban_id(user,response)因为self参数是默认传递的,如果写成self.get_douban_id(self,user,response)则会报错需要三个参数而实际传递了四个参数。
- 运行情况
成功获得用户的这四个信息

2.3.3 修改user_info_spider.py
- 由于在关注的时候需要根据用户主页地址在数据库中查找到用户所对应的实际表中id值,所以还需要保存用户主页地址。
- 用户主页地址并非从爬取的页面获得,而是request请求中发起的url,故需要在request利用
meta将url参数传递给response
只需要修改def start_user_info(self,response):中的yield Request(line, callback=self.parse,meta={“cookiejar”:True,“user_url”:line})
在response中根据response.meta.get("user_url")获取数据
参考:Python爬虫:scrapy框架请求参数meta、headers、cookies一探究竟
笔记十二:python包中类的使用
- 直接指明引用包中的类名
直接指明了引用scrapy包中的Item类和Field类,故可以直接使用。
from scrapy import Item,Field class User(Item): id = Field() head_thumb = Field()
- 指明引用包而不具体指明类名
如果通过import scrapy引入scrapy并不指明具体使用的类,则在使用时需要加上包名
import scrapy class MydoubanItem(scrapy.Item): name = scrapy.Field()
- 引用其他文件中定义的类
引入MyDouban文件中items.py文件中定义的class
from MyDouBan.items import User,UserFollow
- 重命名包
利用as重命名MyDouBan文件夹下database.py文件为dp,相当于到包的概念,由于database.py定义了connection数据,通过db.connection使用该数据
- user_follow.py
import MyDouBan.database as db
- database.py
connection = pymysql.connect(host=MYSQL_HOST, user=MYSQL_USER, password=MYSQL_PASS, db=MYSQL_DB, charset='utf8mb4', cursorclass=pymysql.cursors.DictCursor)
笔记十三:调试方法
方法一:print()
直接在控制台输出我们想要的数据,看它的值
方法二:logger.info()
会比print多了一些内容,包括时间信息等
self.logger.info('-------douban_id:%s', data[0])
笔记十四:python中正则表达式的使用
re正则表达式匹配
re.search和re.match
groups()与group()
匹配日期那个太难了
regx = '//div[@class="user-info"]/div[@class="pl"]/text()'
data = response.xpath(regx).extract()
if data:
result = re.search("(\d{4})-(\d{2})-(\d{2})",data[1])
if result != None:
created_at = "%s-%s-%s 00:00:00" % (result.group(1),result.group(2),result.group(3))
user['created_at'] = created_at
2.4 实现保存用户信息到数据库
2.4.1 编写pipeline.py文件
由于scrapy框架的原理可知,由spider爬虫解析出的实体,交由管道进行处理。因此编写pipeline文件将获得的用户Item写入数据库。
分析爬虫解析后的实体User
在print(user)后我们可以看到,当前用户实体是以字典的形式存放,故由一个个键值对组成。spider传到pipeline的实体交由
def process_item(self, item, spider):函数进行处理。由于对于不同的实体有不同的操作,因此要判断传来的item类型。if isinstance(item, User):表明当前item是一个User类。在这里我们想要实现通过
get_user(item)根据传来的豆瓣id获得用户。如果当前用户在数据库中,则执行update_user(item)更新;如果不在,则执行save_user(item)保存这里要注意一个问题,在对mysql数据库操作时通过sql语句,例如插入时需要
insert into users(param1,param2) values (value1,value2),随着项目的变化,数据库中的字段经常会发生改变。 这样每次就要修改sql语句十分的麻烦,所以采用一种通用的方式:根据字典中所拥有的内容来填充sql语句。

1)获得用户
#根据豆瓣id获得用户
def get_user(self,item):
sql = 'SELECT * FROM users WHERE douban_id=%s' % item['douban_id']
print(sql) #SELECT * FROM users WHERE douban_id=2472913
cursor.execute(sql)
return cursor.fetchone()
- fetchone()取出一行值,还有个fetchall()取出多行值
2)插入用户
#保存用户
def save_user(self,item):
# item是字典,keys为列表,values为元组,field与temp为字符串
keys = item.keys()
values = tuple(item.values())
fields = ','.join(keys)
temp = ','.join(['%s'] * len(keys))
sql = 'INSERT INTO users (%s) VALUES (%s)' % (fields, temp)
print(keys) #dict_keys(['douban_user_url', 'douban_id', 'nickname', 'head_thumb', 'created_at'])
print(values) #('https://www.douban.com/people/alucardkoten/', '2472913', 'Koten', 'https://img9.doubanio.com/icon/ul2472913-4.jpg', '2008-05-11 00:00:00')
print(fields) #douban_user_url,douban_id,nickname,head_thumb,created_at
print(temp) #%s,%s,%s,%s,%s
print(sql) #INSERT INTO users (douban_user_url,douban_id,nickname,head_thumb,created_at) VALUES (%s,%s,%s,%s,%s)
cursor.execute(sql, tuple(i.strip() for i in values))
return db.connection.commit()
keys = item.keys()用于获得所有的字段名列表;values = tuple(item.values())用于获得所有的值列表,要注意这里item.values()返回的类型为,利用tuple()转换为元组,也就是表明这里的元素不能被修改;fields = ','.join(keys)获得一逗号隔开的字段名,如key1,key2,······keyN的形式;temp = ','.join(['%s'] * len(keys))根据实体包含字段的个数来给值占位,如%s,%s······- 这样可通过
'INSERT INTO user_follows (%s) VALUES (%s)' % (fields, temp)获得插入的字符串。在执行插入时将值的参数传入cursor.execute(sql, tuple(i.strip() for i in values))- 运行结果
数据橙光写入数据库

3)更新用户
#更新用户
def update_user(self,item):
douban_id = item.pop('douban_id') #删除豆瓣id的键值对
keys = item.keys()
values = tuple(item.values()) # item.values() 类型: 如果用list(item.values())强制转换还是ValuesView
#由于元组不能添加元素,故遍历元组
valuelist = []
for value in values:
valuelist.append(value)
valuelist.append(douban_id) #将douban_id放在值的最末尾,对应Where后面的%s
fields = ['%s=' % i + '%s' for i in keys]
sql = 'UPDATE users SET %s WHERE douban_id=%s' % (','.join(fields), '%s')
print(sql) #UPDATE users SET douban_user_url=%s,nickname=%s,head_thumb=%s,created_at=%s WHERE douban_id=%s
cursor.execute(sql, valuelist)
return db.connection.commit()
#优化后
#更新用户
def update_user(self,item):
douban_id = item.pop('douban_id') #删除豆瓣id的键值对
keys = item.keys()
values = tuple(item.values()) # item.values() 类型: 如果用list(item.values())强制转换还是ValuesView
fields = ['%s=' % i + '%s' for i in keys]
sql = 'UPDATE users SET %s WHERE douban_id=%s' % (','.join(fields), douban_id)
print(sql) #UPDATE users SET douban_user_url=%s,nickname=%s,head_thumb=%s,created_at=%s WHERE douban_id=1947334
cursor.execute(sql, values)
return db.connection.commit()
- item为字典,利用pop()删除字典中douban_id的键值对,因为之前在获得用户时是根据豆瓣Id获得,故豆瓣id的值不用重新更新,而是要作为最后WHERE的条件传递。
- 由于元组不能在最后利用append添加数据,故将元组遍历添加到一个列表中,在最后利用append()添加douban_id
- 运行结果
- 优化:后来想到其实不需要把douban_id放在values而是直接拼接在sql后面不需要占位,故做了修改,毕竟元组里的值改变就失去了元组的作用,这样不太合理。

4)完整代码
import MyDouBan.database as db
from MyDouBan.items import User,UserFollow
cursor = db.connection.cursor() #获得游标
class MydoubanPipeline(object):
#根据豆瓣id获得用户
def get_user(self,item):
sql = 'SELECT * FROM users WHERE douban_id=%s' % item['douban_id']
print(sql) #SELECT * FROM users WHERE douban_id=2472913
cursor.execute(sql)
return cursor.fetchone()
#保存用户
def save_user(self,item):
# item是字典,keys为列表,values为元组,field与temp为字符串
keys = item.keys()
values = tuple(item.values())
fields = ','.join(keys)
temp = ','.join(['%s'] * len(keys))
sql = 'INSERT INTO users (%s) VALUES (%s)' % (fields, temp) #
print(sql) #INSERT INTO users (douban_user_url,douban_id,nickname,head_thumb,created_at) VALUES (%s,%s,%s,%s,%s)
cursor.execute(sql, tuple(i.strip() for i in values))
return db.connection.commit()
#更新用户
def update_user(self,item):
douban_id = item.pop('douban_id') #删除豆瓣id的键值对
keys = item.keys()
values = tuple(item.values()) # item.values() 类型: 如果用list(item.values())强制转换还是ValuesView
fields = ['%s=' % i + '%s' for i in keys]
sql = 'UPDATE users SET %s WHERE douban_id=%s' % (','.join(fields), douban_id)
print(sql) #UPDATE users SET douban_user_url=%s,nickname=%s,head_thumb=%s,created_at=%s WHERE douban_id=1947334
cursor.execute(sql, values)
return db.connection.commit()
def process_item(self, item, spider):
if isinstance(item, User):
'''
User
'''
exist = self.get_user(item)
if exist == None: #如果当前douban_id对应用户不存在
try:
self.save_user(item)
print('用户%s已添加至数据库!' % item['douban_id'])
except Exception as e:
print(item)
print(e)
else: #若已存在应当更新
self.update_user(item)
print('用户%s已更新!' % exist['douban_id'])
#return item
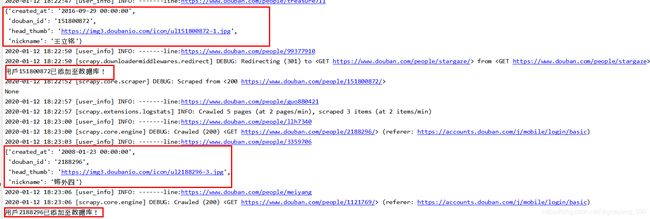
- 运行结果
- scrapy crawl user_info


笔记十五:pymysql对数据库的查插删改
建立数据库连接
import pymysql
MYSQL_DB = 'db_douban' #数据库名称
MYSQL_USER = 'root' #用户名
MYSQL_PASS = '123456' #密码
MYSQL_HOST = 'localhost' #本地数据库
connection = pymysql.connect(host=MYSQL_HOST, user=MYSQL_USER,
password=MYSQL_PASS, db=MYSQL_DB,
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
cursor = connection.cursor() #获得游标
查询
取出一条数据
sql = 'SELECT * FROM users WHERE douban_id=2472913'
cursor.execute(sql)
user = cursor.fetchone() #字典类型,通过user['douban_id']可以取出douban_id的值
取出多条数据
sql = 'SELECT * FROM users'
cursor.execute(sql)
users = cursor.fetchall() #列表类型,内部元素为字典类型,通过user[0]['douban_id']可以取出第一条数据的douban_id的值
插入
占位符填充参数和数据(最方便,通用)
item = {'created_at': '2007-10-25 00:00:00',
'douban_id': '1947334',
'douban_user_url': 'https://www.douban.com/people/rosiel/',
'head_thumb': 'https://img9.doubanio.com/icon/ul1947334-64.jpg',
'nickname': '冬惊'}
keys = item.keys()
values = tuple(item.values())
fields = ','.join(keys)
temp = ','.join(['%s'] * len(keys))
sql = 'INSERT INTO users (%s) VALUES (%s)' % (fields, temp)
cursor.execute(sql, tuple(i.strip() for i in values))
db.connection.commit()
数据采用占位符插入
values = ('https://www.douban.com/people/alucardkoten/', '2472913', 'Koten', 'https://img9.doubanio.com/icon/ul2472913-4.jpg', '2008-05-11 00:00:00')
sql = 'INSERT INTO users (douban_user_url,douban_id,nickname,head_thumb,created_at) VALUES (%s,%s,%s,%s,%s)'
cursor.execute(sql, tuple(i.strip() for i in values)) #取出字符串两边空格
db.connection.commit()
数据直接用字符串插入
values = ('https://www.douban.com/people/alucardkoten/', '2472913', 'Koten', 'https://img9.doubanio.com/icon/ul2472913-4.jpg', '2008-05-11 00:00:00')
temp = '\',\''.join(values)
sql = 'INSERT INTO users (douban_user_url,douban_id,nickname,head_thumb,created_at) VALUES (\'%s\')' % temp
#上述sql = 'INSERT INTO users (douban_user_url,douban_id,nickname,head_thumb,created_at) VALUES ('https://www.douban.com/people/alucardkoten/','2472913','Koten','https://img9.doubanio.com/icon/ul2472913-4.jpg','2008-05-11 00:00:00')'
cursor.execute(sql)
db.connection.commit()
删除
sql = 'DELETE FROM users WHERE douban_id = %s' % '2472913'
cursor.execute(sql)
db.connection.commit()
修改
item = {'created_at': '2007-10-25 00:00:00',
'douban_id': '1947334',
'douban_user_url': 'https://www.douban.com/people/rosiel/',
'head_thumb': 'https://img9.doubanio.com/icon/ul1947334-64.jpg',
'nickname': '冬惊'}
keys = item.keys()
values = tuple(item.values())
fields = ['%s=' % i + '%s' for i in keys]
sql = 'UPDATE users SET %s WHERE douban_id=%s' % (','.join(fields), douban_id)
print(sql) #UPDATE users SET douban_user_url=%s,nickname=%s,head_thumb=%s,created_at=%s WHERE douban_id=1947334
cursor.execute(sql, values)
db.connection.commit()
2.5 实现保存用户关注关系到数据库
2.5.1 编写items.py
添加UserFollow实体
class UserFollow(Item):
user_id = Field()
user_follow_id = Field()
2.5.2 编写save_user_follow.py
由于之前存储是以当前用户豆瓣Id命名的文件,根据该豆瓣id可以获得主码id。然后在文件中存储了用户主页的url,依次从文件中取出url在数据库中查找,如果找到则能得到对应关注用户的主码id,将这个关系存储到数据库即可。
import os
import MyDouBan.database as db
from MyDouBan.items import UserFollow
#获得连接数据库的游标
cursor = db.connection.cursor()
#从数据库中获得所有用户
def get_users():
sql = 'SELECT douban_id from users'
cursor.execute(sql)
users = cursor.fetchall()
return users
#根据用户主页地址从数据库中获得某个用户id
def get_user_from_url(user_url):
sql = 'SELECT id from users WHERE douban_user_url=\'%s\'' % user_url
cursor.execute(sql)
user = cursor.fetchone()
return user
#根据用户豆瓣ID从数据库中获得某个用户id
def get_user_from_id(douban_id):
sql = 'SELECT id from users WHERE douban_id=%s' % douban_id
cursor.execute(sql)
user = cursor.fetchone()
return user
#找出该关注关系是否已经存储
def get_user_follow(item):
sql = 'SELECT * from user_follows WHERE user_id=%s AND user_follow_id=%s' % (item['user_id'],item['user_follow_id'])
cursor.execute(sql)
user = cursor.fetchone()
return user
#保存用户关注关系
def save_user_follow(item):
keys = item.keys() # item是字典,keys为列表,values为元组,field与temp为字符串
values = tuple(item.values())
fields = ','.join(keys)
temp = ','.join(['%s'] * len(keys))
sql = 'INSERT INTO user_follows (%s) VALUES (%s)' % (fields, temp)
cursor.execute(sql, tuple(i for i in values))
return db.connection.commit()
if __name__ == '__main__':
users = get_users()
for user in users:
douban_id = user['douban_id']
user_id = get_user_from_id(douban_id)['id'] #获得当前用户的id
filepath = '../storage/userFollow/' + '%s' % douban_id + '.txt'
print(filepath)
if os.path.exists(filepath):
file = open(filepath, "r")
for line in file:
line = line[:-1]
user_follow = get_user_from_url(line) #获得用户关注的对象
if user_follow:
user_follow_id = user_follow['id'] #获得用户关注的对象的id
userFollow = UserFollow()
userFollow['user_id'] = user_id
userFollow['user_follow_id'] = user_follow_id
print(userFollow)
exist = get_user_follow(userFollow)
if not exist:
save_user_follow(userFollow)
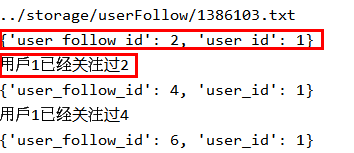
else:
print('用户%s已经关注过%s' % (userFollow['user_id'],userFollow['user_follow_id']))
else:
print('未找到%s对应用户' % line)
else:
print('不存在用户%s的关注文件' % user['douban_id'])
运行结果
2.6 后期优化
2.6.1 部分账户被冻结
被冻结的用户无法获得豆瓣id,因此要过滤,不用保存到错误页面中

regx1 = '//div[@class="mn"]/a'
exist = data = response.xpath(regx1).extract()
if exist:
print('%s用户已冻结' % user ['douban_user_url'])
同时优化解析过程如果douban_id为空就不爬取其他信息了
user['douban_user_url'] = response.meta.get("user_url")
self.get_douban_id(user,response)
if user["douban_id"] != None:
self.get_nikename(user,response)
self.get_head_thumb(user,response)
self.get_created_at(user,response)
print(user)
return user
项目地址:https://github.com/joyceyang999/MyDouBan
本文旨在记录自己搭建项目时的理解和思考,由于知识水平受限,存在偏颇,记录过程有点乱,如有大佬发现错误之处,欢迎指正探讨。虚心求学ing