Centos7安装Hadoop3.2
一、 Linux环境准备
- 准备4台服务器,通过VMware安装centos7(此文不讲VMware安装Linux)
1台(server01)用来安装namenode和resourceManager,3台(server02,server03,server04)datanode - 给4台服务器新增hadoop用户
使用xshell客户连接服务器,compose bar可以同时向所有会话服务器执行相同命令
useradd hadoop 提示用户已存在 
执行 userdel -r hadoop 删除用户,再执行useradd hadoop,执行passwd hadoop修改密码

以下操作都用Hadoop用户进行
3. 安装jdk1.8
下载jdk
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
上传jdk到server01,可以输入rz命令或者通过xftp工具上传
执行命令 tar -zxvf jdk-8u221-linux-x64.tar.gz -C /usr/local/ 解压到/usr/local/目录

提示权限不够
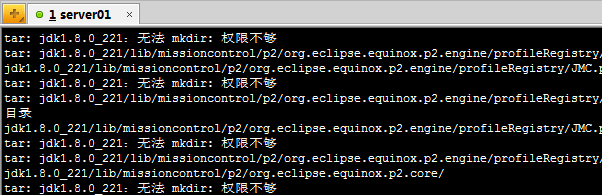
采用sudo tar -zxvf jdk-8u221-linux-x64.tar.gz -C /usr/local/执行 提示hadoop不在sudoers中

切换root用户配置sudoers文件
[root@localhost hadoop]# vi /etc/sudoers
增加配置

切换hadoop执行
[hadoop@localhost ~]$ sudo tar -zxvf jdk-8u221-linux-x64.tar.gz -C /usr/local/
配置jdk环境变量
切换root用户,vi /etc/profile 修改profile 文件,定义javaHome为上一步解压目录,并把Javahome追加到系统path后面

保存后执行 source /etc/profile 加载环境变量生效,
执行[root@localhost hadoop]# java -version 提示jdk安装成功

此处还只安装了server01环境的jdk,另外3台服务器在server01通过scp命令拷贝过去
1.拷贝sudoers文件
[root@server01 hadoop]# scp /etc/sudoers server02:/etc/
提示没有配置hostname

修改hostname,并配置服务器之间域名解析
[root@localhost sysconfig]# vi /etc/hostname
再执行[root@server01 hadoop]# scp /etc/sudoers server02:/etc/
![]()
2. 拷贝profile文件
[root@server01 hadoop]# scp /etc/profile server02:/etc/
3.拷贝jdk安装目录
[root@server01 hadoop]# scp -r /usr/local/jdk1.8.0_221 server02:/usr/local/
分别再重复执行上面步骤,修改server03,server04就好
4.分别在每天服务器执行命令加载环境变量
[root@server02 hadoop]# source /etc/profile
5.分别检查每天机器的jdk是否安装成功
第一次写博客,文本编辑器用的很不习惯,上面一点点内容写了2小时,加油吧。
二、安装Hadoop
- 下载Hadoop
下载地址:https://hadoop.apache.org/release/3.2.0.html
我下载是最新的版本 Release 3.2.0 available hadoop-3.2.0.tar.gz - 上传hadoop-3.2.0.tar.gz 到server01服务器
- 解压hadoop-3.2.0.tar.gz 到/home/hadoop/apps目录(apps目录存放安装文件)
[hadoop@localhost ~]$ tar -zxvf hadoop-3.2.0.tar.gz - apps/
查看解压文件

- 配置Hadoop环境变量
[hadoop@localhost hadoop-3.2.0]$ sudo vi /etc/profile

同理拷贝 /etc/profile 到server02,server03,server04服务器
[hadoop@localhost hadoop-3.2.0]$ sudo scp /etc/profile server02:/etc/
- 修改hadoop配置, 目录/home/hadoop/apps/hadoop-3.2.0/etc/hadoop
#修改hadoop-env.sh找到文件中JavaHome位置并修改

#修改core-site.xml,在configuration在添加如下property,
Fd.defaultFS指定文件存储协议及地址端口
Hadoop.tmp.dir指定数据存放目录

#修改hdfs-site.xml文件,指定副本数量,默认3,不配置也可以

#修改mapred-site.xml,指定mapreduce采取的调度框架
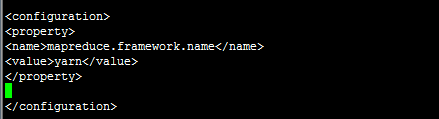
#修改yarn-site.xml

6. 格式化Hadoop
[hadoop@localhost hadoop-3.2.0]$ hadoop namenode –format
- 启动Hadoop
[hadoop@localhost sbin]$ hadoop-daemon.sh start namenode
查看namenode是否启动成功
[hadoop@localhost sbin]$ jps
18923 Jps
18845 NameNode - 访问hsfs web页面 http;//ip:50070 提示无法访问
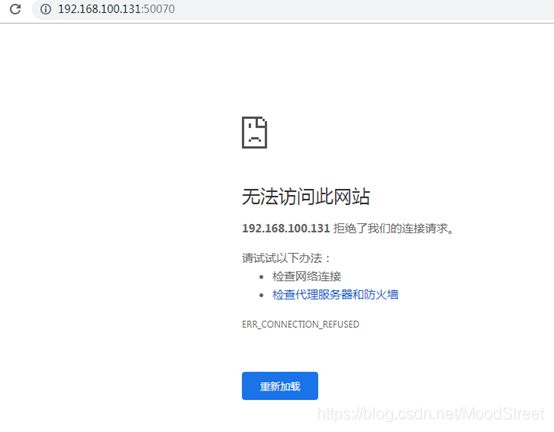
查看本机开发端口(不知道hadoop3.0以后端口改为9870),百度后得知3.0以后端口改了,去官网查证确实改了


采用9870端口访问成功了

-
拷贝Hadoop安装目录到另外3台服务器
[hadoop@server01 ~]$ scp -r apps server02:/home/hadoop -
启动datanode节点
[hadoop@server02 ~]$ hdfs --daemon start datanode
刷新网页查看是否成功

- 测试
上传一个文件,提示上传失败


采用命令上传吧,当前目录新建test文件
[hadoop@server01 ~]$ echo "hello hdfs " > test
上传test文件到根目录
[hadoop@server01 ~]$ hadoop fs -copyFromLocal test /
节点server02报错了

查找原因,server02是单独安装的,防火墙采用firewall,关闭防火墙就好了。网页刷新看到文件

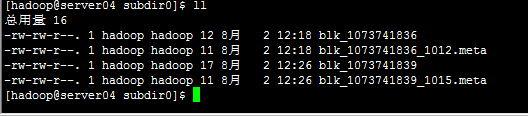
我上传了2个文件,之前配置hdfs-site.xml是设置2个副本(replication>datanode,以实际datanode数量存储副本数),刚好
文件都存在在server03和server04上了,
Server03

Server04
其他文件操作命令与Linux基本相同,在命令前加 hadoop fs
总结
写之前纠结了很久要不要写,刚好看到了这篇博文 https://blog.csdn.net/qq_40733911/article/details/94760047
就果断开始了,第一次写的不是很好,不喜勿喷,欢迎大家提出建议交流。