Spark Transformation算子---举例总结
(我这个是直接运行在spark-shell里面的)
算子,通俗一点儿就是函数,方法
spark里面的算子分两大类:
(1) 转换算子 Transformation(只作转换)
(2)行动算子 Action(行动)
以下提到的算子都是转换算子:
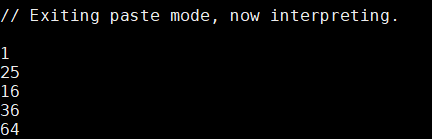
1. map :遍历每一个元素,返回一个新的RDD(弹性分布式数据集)
val arr=Array(1,5,4,6,8)
val numRDD=sc.parallelize(arr) //sc= new SparkContext
val resultRDD=numRDD.map(x=>x*x) //每一个元素变成平方
resultRDD.collect.foreach(println)
输出结果:
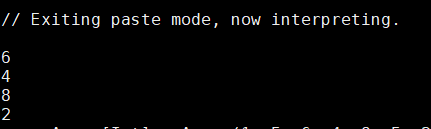
2. filter : 返回一个新的RDD,该RDD由计算之后值为true的元素组成
(比如这个RDD是由取余值为0的元素(偶数)组成的)
可以理解为筛选器,筛选出我们自己想要的
val arr =Array(1,5,6,4,8,5,2,77)
val numRDD=sc.parallelize(arr)
val resultRDD=numRDD.filter(_%2==0)
resultRDD.collect.foreach(println)
运行结果:
-
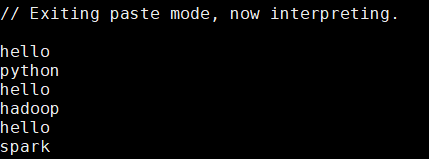
flatMap : 扁平化,提到扁平化可以想到那个单词统计案例
第一步textFile 读取一行内容
第二步flatMap 扁平化(按照条件得到一个个的单词)
第三步map 变成(k,v)形式
第四步 reduceByKey相同的key的value值放一起进项行相加聚合
第五步 collect 显示在控制台
val words=Array("hello python","hello hadoop","hello spark")
val wordRDD=sc.parallelize(words)
wordRDD.flatMap(_.split(" ")).collect.foreach(println)
// — 表示的是遍历的每一个元素,split 是切割 ,此处是按照空格切割
运行结果:
- mapPartitions: 类似map ,但map 是对一个个的元素进行操作,mapPartitions 是以每一个分区为单位,对分区数据进行操作,需要用迭代器遍历分区里面的数据
import scala.collection.mutable.ArrayBuffer
//需要导这个包,因为下面用到了 数组集合 ArrayBuffer
val arrayRDD=sc.parallelize(Array(1,2,3,4,8,6,4))
arrayRDD.mapPartitions(elements=>{
//这里的elements指的就是每一个分区
val result=new ArrayBuffer[Int]
//定义一个数组result,用来存放当前所在分区里面的数据
elements.foreach(e=>{
//这里的e指的是分区里面的数据
result +=e
//把获取到的元素一个个添加到数组里面
})
result.iterator
//用迭代器遍历到写一个分区
}).foreach(println)
运行结果:
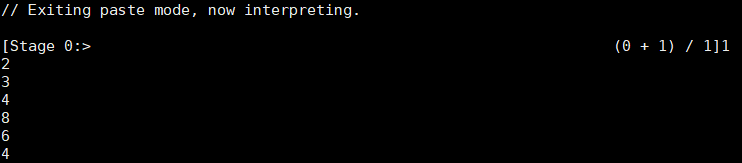
mapPartition 因为是按照分区执行的,所以比其他的执行速度快,但是mapPartition 因为按分区操作,所以要等到所有分区操作完之后才能释放空间,前面执行完的分区,也要等到最后一个分区执行完之后才能释放内存,所以使用mapPartition 的时候容易出现内存溢出现象,所以当内存充足的时候使用mapPartition ,执行速度快,但是内存不够大的时候不建议使用。
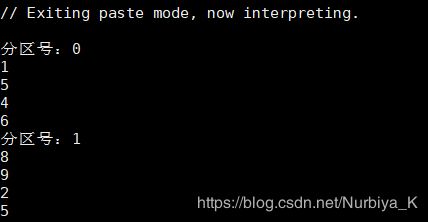
- mapPartitionsWithIndex: 类似于mapPartition ,这里的Index是指分区号,可以通过分区索引来遍历其内的数据
val arrayRDD=sc.parallelize(Array(1,5,4,6,8,9,2,5),2)
//parallelize 是并行的意思,是把数据自动分到各个分 区里面,这了最后的2 是指分成两个区
arrayRDD.mapPartitionsWithIndex((index,elements)=>{
//index 指的是分区号,elements是指这个分区里面的元素集合
println("分区号:"+index)
//输出分区索引,一般从零开始
import scala.collection.mutable.ArrayBuffer
val result=new ArrayBuffer[Int]
elements.foreach(e=>{
result +=e
//分区里面的元素一个个加到集合里面
})
result.iterator
//遍历所有分区
}).foreach(println)
输出结果:
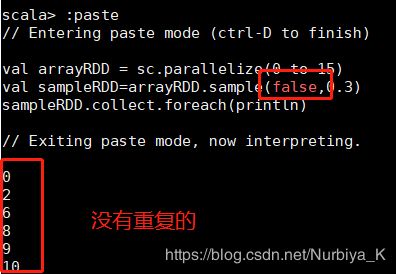
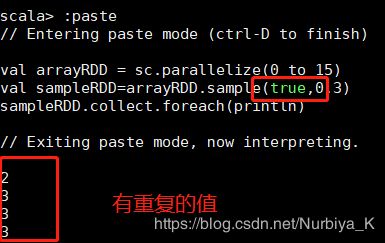
- sample(withReplacement : scala.Boolean, fraction : scala.Double,seed scala.Long):抽出随机数,有3个参数:
withReplacement:表示抽出样本后是否在放回去,true表示会放回去,这也就意味着抽出的样本可能有重复
fraction :抽出多少,这是一个double类型的参数,0-1之间,eg:0.3表示抽出30%
seed:表示一个种子,根据这个seed随机抽取,一般情况下只用前两个参数就可以
详细介绍点击此处
- groupByKey: 按照key值相同的分一起
val scores = Array(("class1",95),("class2",85),("class1",75))
val scoreRDD=sc.parallelize(scores)
scoreRDD.groupByKey.collect.foreach(_._2.foreach(println))
//分区,把key一样的放到一个区,然后遍历出来
结果:
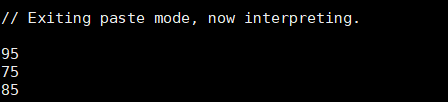
- reduceByKey : 相同的key放到一个区,把value值归约合并,就像上面的单词数量统计案例一样,把相同key的value放到一个集合
val scores = Array(Tuple2("class1",95),Tuple2("class2",85),Tuple2("class1",75))
val scoreRDD=sc.parallelize(scores)
scoreRDD.reduceByKey(_+_).collect.foreach(println)
//两个 - 表示前后两个元素,把他们相加起来
结果:
![]()
- sortByKey :排序,后面的参数为true则升序,参数为false,则降序
val arr=sc.parallelize(Array ((7,"aa"),(1,"bb"),(5,"gb")))
arr.sortByKey(true).collect()
// 结果:
Array[(Int, String)] = Array((1,bb), (5,gb), (7,aa))
arr.sortByKey(false).collect()
// 结果:
Array[(Int, String)] = Array((7,aa), (5,gb), (1,bb))
- union :对两个RDD求并集,返回一个新的RDD
val rdd1=sc.parallelize(1 to 10)
// 1 到 10 的元素,包括1 和10
val rdd2=sc.parallelize(11 to 20)
val result=rdd1.union(rdd2)
//两个分区里面的元素求并集
result.collect.foreach(print)
运行结果:
1234567891011121314151617181920
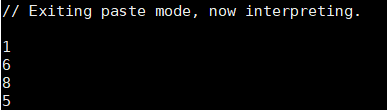
- intersection:求两个集合的交集
val rdd1=sc.parallelize(Array(1,5,4,6,8,6))
val rdd2=sc.parallelize(Array(1,5,2,3,6,8))
val result=rdd1.intersection(rdd2)
result.collect.foreach(println)
运行结果:
- distinct:比较两个RDD里面的元素去掉重复的元素
val arr=Array(
Tuple3("max","math",90),
Tuple3("max","english",85),
Tuple3("mike","math",100))
val scoreRDD=sc.parallelize(arr)
val userNumber=scoreRDD.map(_._1).distinct.collect
println(userNumber.mkString(","))
运行结果:

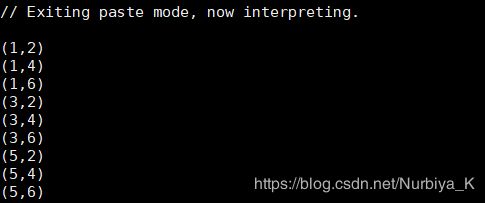
- cartesian:当调用T和U类型的数据集时,返回一个(T,U)类型的数据集
val arr1=sc.parallelize(Array(1,3,5))
val arr2=sc.parallelize(Array(2,4,6))
arr1.cartesian(arr2).collect.foreach(println)
运行结果:
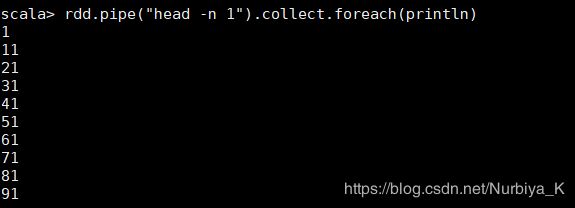
- pipe:对RDD的每个分区进行管道连接
val rdd = sc.parallelize( 1 to 100,10)
rdd.pipe("head -n 1").collect.foreach(println)
运行结果: